






本篇内容参考对比损失思想设计loss function的方法,有关对比学习相关工作的讲解请细看原文。
目录
1. Improved Deep Metric Learning with Multi-class N-pair Loss Objective
2. Unsupervised Feature Learning via Non-Parametric Instance Discrimination
3. Momentum Contrast for Unsupervised Visual Representation Learning
一、对比损失介绍(What)
对比损失在非监督学习中应用很广泛。最早源于 2006 年Yann LeCun的“Dimensionality Reduction by Learning an Invariant Mapping”,该损失函数主要是用于降维中,即本来相似的样本,在经过降维(特征提取)后,在特征空间中,两个样本仍旧相似;而原本不相似的样本,在经过降维后,在特征空间中,两个样本仍旧不相似。同样,该损失函数也可以很好的表达成对样本的匹配程度。
 https://ieeexplore.ieee.org/abstract/document/1640964
https://ieeexplore.ieee.org/abstract/document/1640964在非监督学习时,对于一个数据集内的所有样本,因为我们没有样本真实标签,所以在对比学习框架下,通常以每张图片作为单独的语义类别,并假设:同一个图片做不同变换后不改变其语义类别,比如一张猫的图片,旋转或局部图片都不能改变其猫的特性。因此,假设对于原始图片 X,分别对其做不同变换得到 A 和 B,此时对比损失希望 A、B 之间的特征距离要小于 A 和任意图片 Y 的特征距离。
二、对比损失的定义
对比损失(Contrastive Loss)是对比学习中常用的一种损失函数,它通过比较正样本对和负样本对之间的相似性,引导模型学习有意义的特征表示。在对比损失中,目标是使正样本对的相似性更大,而负样本对的相似性更小。
对比损失的定义如下:
设输入样本为
和
,它们分别属于同一类别的正样本对,或者来自不同类别的负样本对。对于这两个样本,模型输出的特征表示分别为
和
,通常通过一个神经网络得到。
对比损失的基本形式是欧氏距离(Euclidean Distance)的平方,如下:
其中:
·是指示函数,当样本
·是一个控制负样本对间隔的超参数,通常称为
。
· 欧氏距离用于度量样本对在特征空间中的距离。
·表示样本对
对比损失的含义是,在正样本对
对比损失函数L:
其中,
代表两个样本特征的欧式距离,
代表特征的维度,
为两个样本是否匹配的标签(
代表两个样本相似或匹配,
代表两个样本不相似或不匹配),
为设定的阈值(超过
的把其
看作 0,即如果两个不相似特征离得很远,那么对比
应该是很低的),
为样本数量。
通过 : ,
可以发现,对比损失可以很好的描述成对样本的匹配程度,能够很好的用于训练提取特征的模型:
(1) 当时,即两个样本相似或匹配时,损失函数
,即如果原本相似或匹配的样本如果其被模型提取的特征欧氏距离很大,说明模型效果不好导致
很大。
(2) 当时,即两个样本不相似或不匹配时,损失函数
,如果这时两个样本被模型提取的特征欧式距离很小,那么
会变大以增大模型的惩罚从而使
减小,如果两个样本被模型提取的特征欧式距离很大,说明两个样本特征离得很远,此时如果超过阈值
则把其
看作 0,此时的
很小。
三、一些现有工作
1. Improved Deep Metric Learning with Multi-class N-pair Loss Objective
Paper_add:https://proceedings.neurips.cc/paper/2016/file/6b180037abbebea991d8b1232f8a8ca9-Paper.pdf
简介:本文是基于 Distance metric learning,目标是学习数据表征,但要求在 embedding space 中保持相似的数据之间的距离近,不相似的数据之间的距离远。其中,N-pair loss指的是——需要从 N 个不同的类中构造 N 对样本——属于自监督学习。
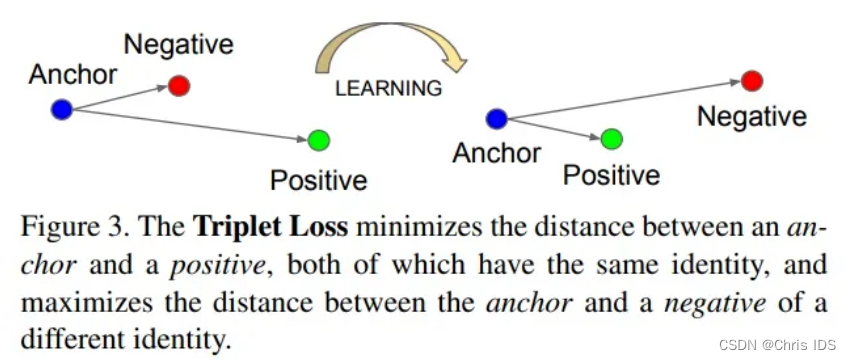
2. Unsupervised Feature Learning via Non-Parametric Instance Discrimination
Paper_add:https://arxiv.org/pdf/1805.01978.pdf
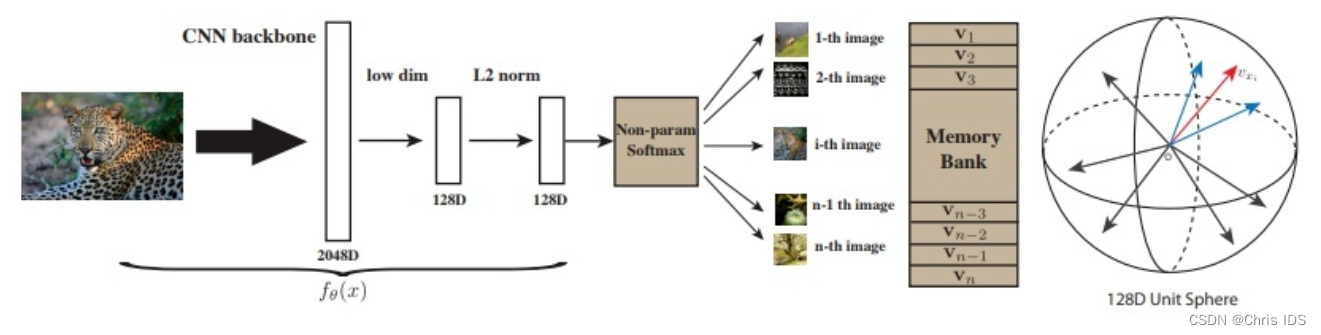
简介:本文将 instance discrimination 机智地引入了 memory bank 机制,并且真正地把 loss 用到了 unsupervised learning。该论文主要论述如何通过非参数的 instance discrimination 进行无监督的特征学习。主要的思想是将每个单一实例都看作不同的“类”。
其中,Instance discrimination 区分不同实例,将当前实例于不同实例进行空间划分 memory bank 由数据集中所有样本的表示组成。
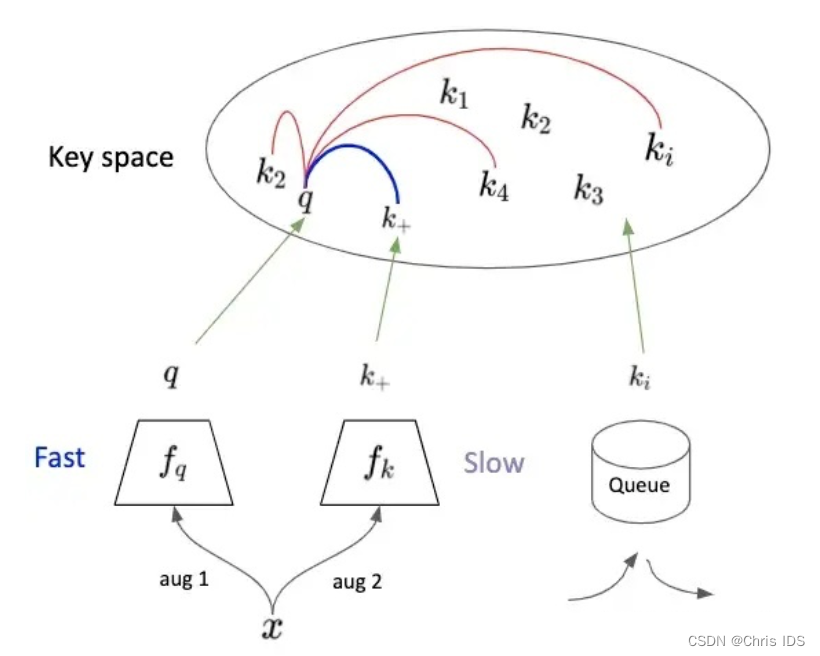
3. Momentum Contrast for Unsupervised Visual Representation Learning
Paper_add:https://arxiv.org/pdf/1911.05722.pdf
简介:本文解决了一个非常重要的工程问题:如何节省内存节省时间搞到大量的 negative samples?文章的 motivation源于之前 contrastive learning 存在两种问题:1)在用 online 的 dictionary 时(即是文章中比较的 end-to-end 情形),constrastive learning 的性能会受制于 batch size,或者说显存大小。2)在用 offline 的 dictionary 时(即是文章中说的 memory bank(InstDisc)情形),dictionary 是由过时的模型生成的,某种程度上可以理解为 supervision 不干净,影响训练效果。那么很自然的,如果想要一个 trade-off,兼顾 dictionary 的大小和质量。文章给出的解法是对模型的参数空间做 moving average,相当于做一个非常平滑的 update。
四、初认识——Contrastive learning
经过对Contrastive learning的定义和基本知识的学习。大家应该可以发现,设计对比学习模型的重点在于——定义一个合适的对比损失函数和构建对比样本。
对比学习是一种自监督学习方法,通过学习样本之间的相似性和差异性,来学习有意义的特征表示。在设计对比学习模型时,我们可以从下面的一些关键点着重切入:
对比损失函数的选择: 对比损失函数是对比学习模型的核心。常见的对比损失函数包括Triplet Loss、Contrastive Loss、N-pair Loss等。这些损失函数在衡量正样本对之间的相似性和负样本对之间的差异性方面有不同的设计思路。选择适合任务和数据特点的对比损失函数非常关键。
正负样本的构建: 对比学习依赖于构建正负样本对。正样本对应于同一样本的不同视图或增强,而负样本对应于不同样本。合理的样本构建策略有助于提高模型的泛化能力。对于图像任务,可以使用数据增强、随机裁剪等方式生成正负样本对。
网络架构设计: 对比学习模型的网络架构应当能够捕捉输入样本的有意义表示。常用的网络架构包括Siamese Network、Triplet Network以及近年来流行的Contrastive Divergence等。网络架构的设计需要考虑模型的深度、宽度以及是否使用预训练模型等因素。
学习率和优化算法: 对比学习的训练通常需要仔细调整学习率和选择合适的优化算法。适当的学习率可以加速模型收敛,而优化算法的选择可能影响到损失函数的优化效果。
评估指标: 在设计对比学习模型时,需要定义合适的评估指标来衡量模型的性能。这可能涉及到对比学习任务的具体应用,例如图像检索、特征表示学习等。
领域特定的调整: 对于不同的任务和应用场景,可能需要进行一些领域特定的调整。这包括选择合适的输入特征、调整损失函数的权重、进行领域自适应等。
后期,我将整理一篇对比学习高质量论文集,希望能从任务、构建loss角度等方面分块介绍一些有价值的研究工作。希望和大家一起进步!

















 3453
3453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









