







一,上传spark到Linux并解压文件到相应目录

进行解压 解压命令格式:tar -zxvf 压缩包名 /目录
tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz 解压后修改名字
mv spark-2.4.5-bin-hadoop2.7/ spark-standalone 
二,配置环境变量:
vi ~/.bashrc添加配置:
export SPARK_HOME=/usr/soft/spark-standalone
export PATH=$PATH:$SPARK_HOME/bin
最后source:
source ~/.bashrc三, 修改配置文件:
(1)进入解压缩路径(spark-standalone)的conf目录,修改slaves.template文件名为slaves:
mv slaves.template slaves(2)修改slaves文件,添加work节点:
vim slaves
在slaves添加自己另外两台虚拟机的主机名(每个人的主机名不一样)
(3)修改spark-env.sh.template文件名为spark-env.sh:
mv spark-env.sh.template spark-env.sh(4)修改spark-env.sh文件,添加JAVA_HOME环境变量和集群对应的master节点:
vim spark-env.sh
在spark-env.sh文件中添加:
export JAVA_HOME=/opt/tool/jdk/jdk1.8
SPARK_MASTER_HOST=master
SPARK_MASTER_PORT=7077注意:JAVA_HOME是你自己jdk目录
SPARK_MASTER_HOST=你自己的主机名

注意:7077端口,相当于hadoop3内部通信的8020端口,此处的端口需要确认自己的Hadoop配置。
(5)分发spark-standalone目录
要在另外两台虚拟机创建与主虚拟机一样的目录 然后分发到一样的目录下
分发格式:
scp -r spark-standalone/ node1:/目录 scp -r spark-standalone/ node2:/目录五,启动集群:
(1)执行以下命令:
sbin/start-all.sh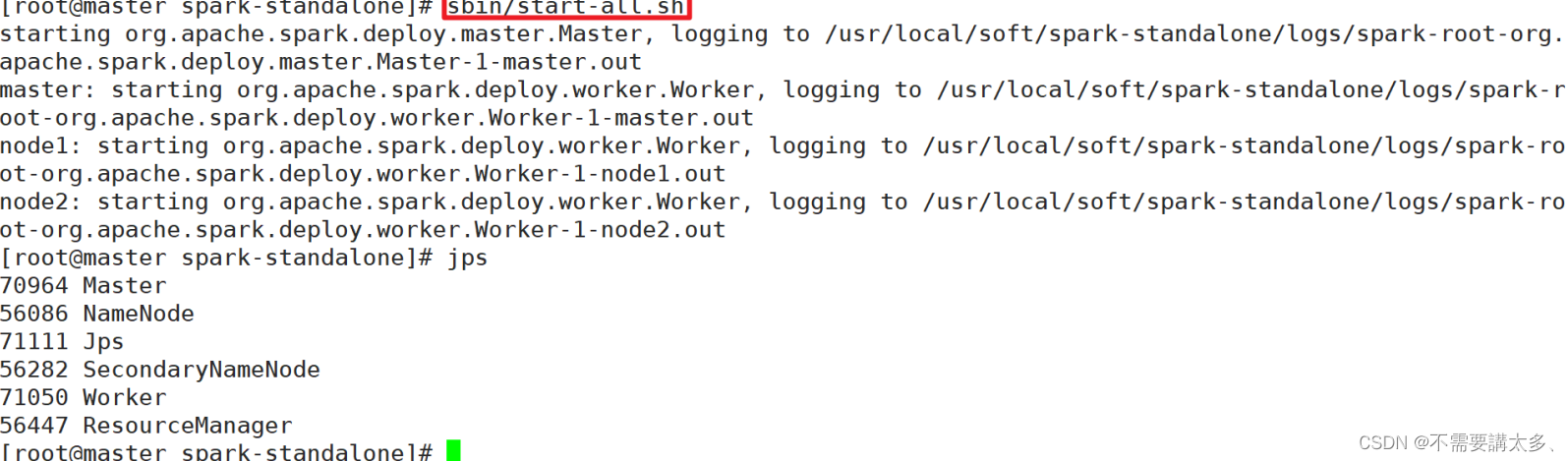
(2)查看三台服务器运行进程
master:
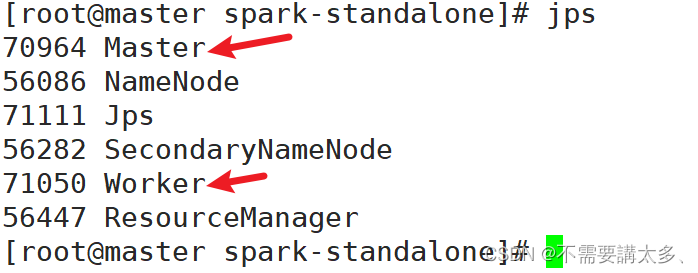
node1:

node2:

(3)查看Master资源监控Web UI界面:http://master:8080(如果加载不出来可以把主机名改成IP地址)
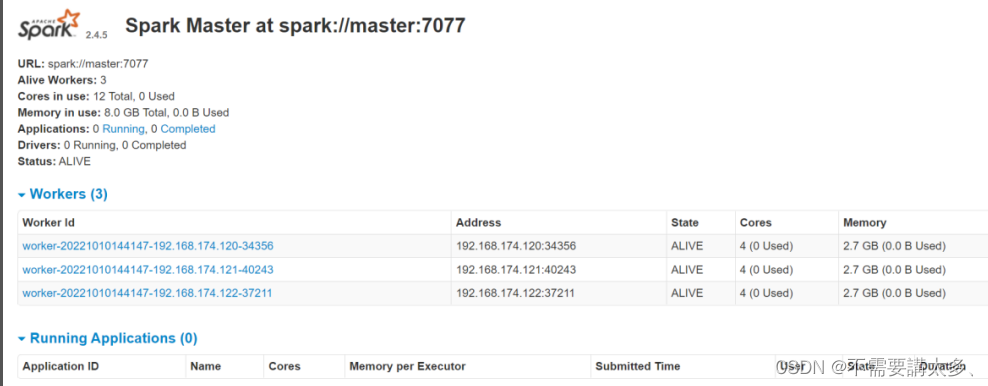















 106
106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









