







本地环境部署
安装包下载地址
Index of /dist/spark/spark-3.0.0 (apache.org)
将安装包传入到虚拟机中
 将 spark-3.0.0-bin-hadoop3.2.tgz 文件上传到 Linux 并解压缩,放置在指定位置,路径中 不要包含中文或空格
将 spark-3.0.0-bin-hadoop3.2.tgz 文件上传到 Linux 并解压缩,放置在指定位置,路径中 不要包含中文或空格
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt
更改文件夹名称
mv spark-3.0.0-bin-hadoop3.2/ spark
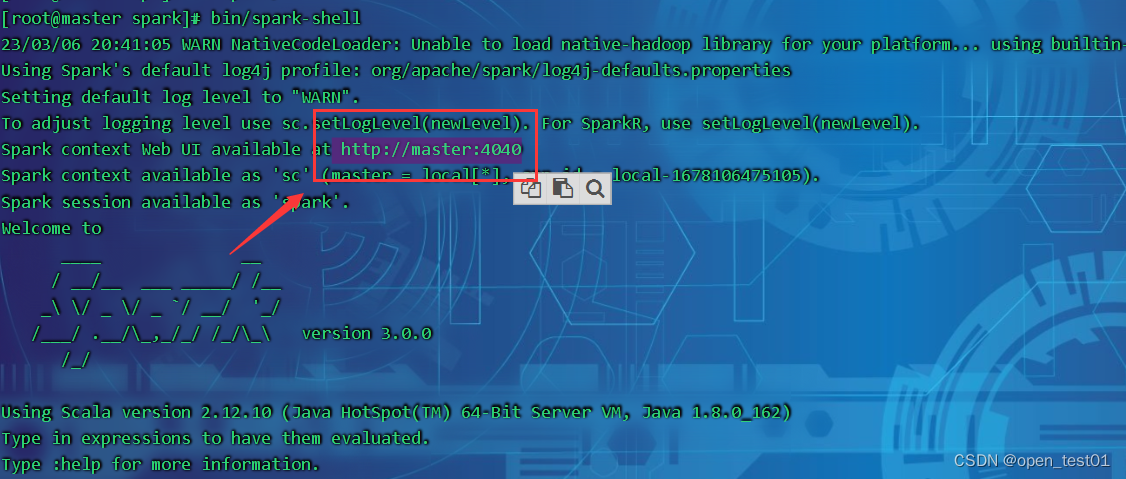
进入bin目录执行spark-shell文件可以执行简单的spark语句

启动成功后,可以输入网址进行 Web UI 监控页面访问(spark-shell执行后会有文字提示)
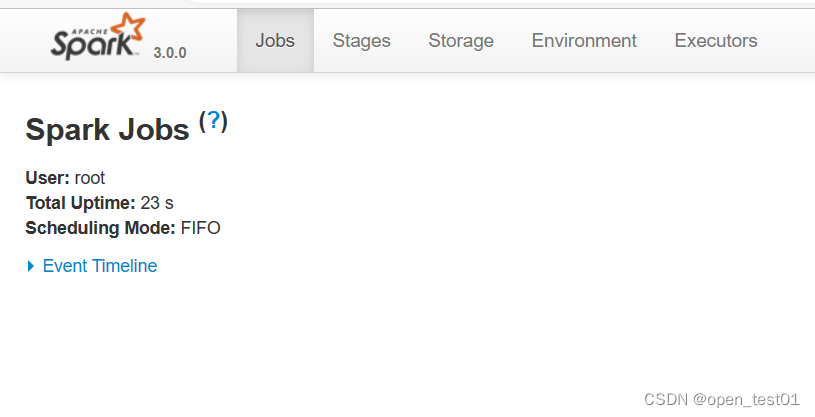
提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
- class 表示要执行程序的主类,此处可以更换为咱们自己写的应用程序
- master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟 CPU 核数量
- spark-examples_2.12-3.0.0.jar 运行的应用类所在的 jar 包,实际使用时,可以设定为咱 们自己打的 jar 包
独立环境部署
修改配置文件
1、进入解压缩后路径的 conf 目录,修改 slaves.template 文件名为 slaves
mv slaves.template slaves
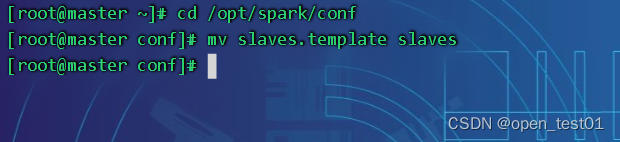
2、修改 slaves 文件,添加 work 节点
master //自己集群主机名称
slave1
slave2

3、修改 spark-env.sh.template 文件名为 spark-env.sh
mv spark-env.sh.template spark-env.sh
4、修改 spark-env.sh 文件,添加 JAVA_HOME 环境变量和集群对应的 master 节点
vim spark-env.sh写入以下内容
export SPARK_DIST_CLASSPATH=$(/opt/hadoop-3.3.4/bin/hadoop classpath)
export JAVA_HOME=/usr/local/jdk1.8.0_162
export PATH=$PATH:$JAVA_HOME/bin
export SCALA_HOME=/usr/local/scala-2.13.10
export PATH=$PATH:$SCALA_HOME/bin
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin
SPARK_MASTER_HOST=master
export SPARK_MASTER_IP=master
SPARK_MASTER_PORT=7077
 5、配置环境变量
5、配置环境变量
vim /etc/profile
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin 6、在sbin的目录下的spark-config.sh 文件下未添加JAVA_HOME的索引
export JAVA_HOME=/usr/local/jdk1.8.0_1627、将配置好的spark分发
分发到slave1
scp -r /opt/spark root@slave1:/opt
 分发到slave2
分发到slave2
scp -r /opt/spark root@slave2:/opt
启动集群
sbin/start-all.sh查看 Master 资源监控 Web UI 界面: http://master:8080
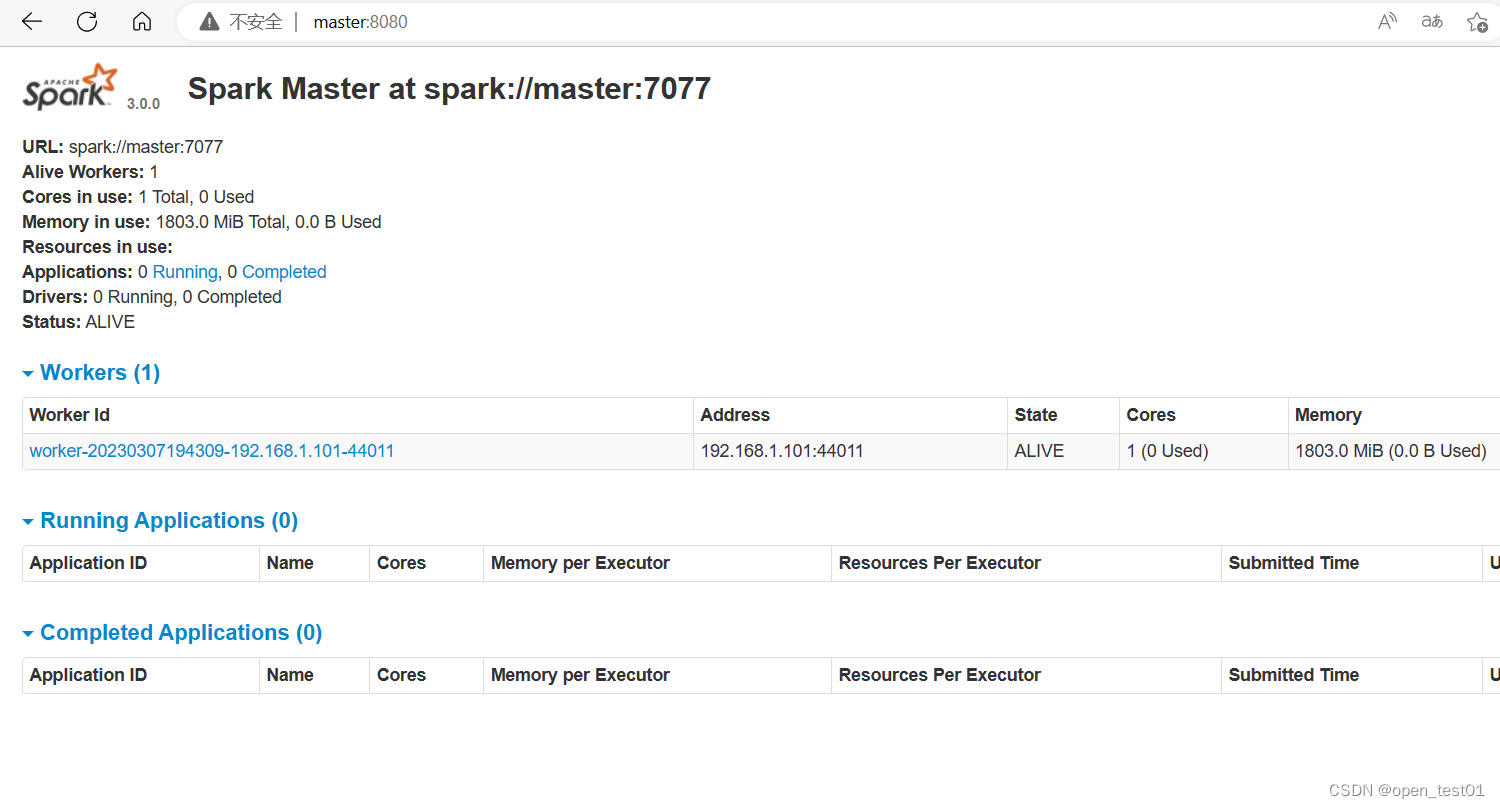
提交应用测试

















 2885
2885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











