







笔者此前总结过一些Mysql基础问题,感兴趣的可以点击链接 Mysql基础篇 进行查看,本篇只讲Mysql高级,涉及工作常遇以及面试常问的一些问题。
文章目录
1、SQL语句的执行过程
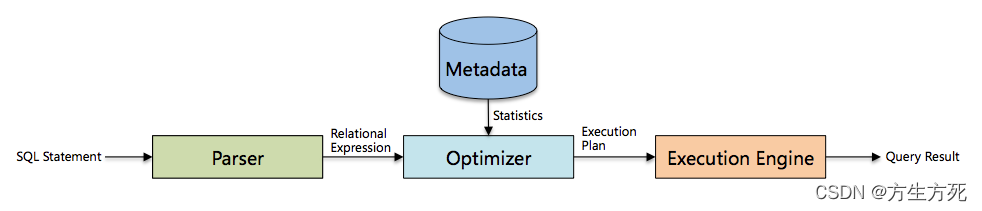
在实际的sql底层执行时:会将我们的sql语句通过解析器进行解析,判断是否有sql语法错误,语法无误则将其转换为sql查询树,通过优化器去判断是否走索引,走哪些索引比较快,最后通过我们具体的执行引擎(innodb或mysalam等)进行执行。
架构共性总结:在JVM加载类或是Mysql运行sql,首先都会去校验我们写的代码是否符合其规范,在一切符合规范的前提下,才会进行下一步的操作流程。在我们日常写代码过程中,这种先校验的方法,值得借鉴,切忌偷懒!
2、Mysql索引优化
索引在查询中的作用到底是什么?在我们查询中发挥着怎样的作用?
- 一个索引就是一个B+树,索引让我们的查询可以快速定位和扫描到我们需要的数据记录上,加快查询的速度;
- 一个SELECT查询语句在执行过程中一般最多能使用一个二级索引来加快查询,即使在where条件中使用了多个二级索引。
2.1 排序在MYSQL中的优化
单路排序:所有的字段都放在sort_buffer缓存中,对sort_buffer中的数据按照指定字段进行排序;
双路排序:将主键id和排序字段放到sort_buffer中,对sort_buffer中的数据按照id和排序字段进行排序。遍历排好序的id和排序字段,按照id的值回到原表中取出所有的值返回给客户端。
区别:单路不需要回表,双路需要回表。MYSQL通过max_length_for_sort_data这个参数来控制排序,在不同场景使用不同排序,从而提高效率(一般max_length_for_sort_data<1024字节,使用单路排序)。但注意:非专业的DBA不要轻易调整,未必有MYSQL自己优化的好!
2.2 分页在MYSQL中的优化
当表中数据足够大时,我们发现翻前几页很快,但越往后,比如100页,响应越慢,例如下面这条sql(其中name为索引字段)在MYSQL中是如何执行的呢?
SELECT * FROM employees ORDER BY name LIMIT 100,100;
从100页开始取100条数据,MYSQL是查询出前10100条数据,然后将前10000条数据截取剔除,保留后面的100条返回。但上述SQL使用EXPLAIN执行后发现并没有走name索引字段,因为扫描整个索引并查找到没索引的行(2.1中提到的单路排序!遍历多个索引树的成本比扫描全表的成本更高,优化器放弃使用索引)现在知道没有走索引,优化关键:让排序时返回的字段尽可能少!(双路排序)
SELECT * FROM employees e INNER JOIN
(SELECT id FROM employees ORDER BY name LIMIT 100,100) ed
ON e.id=ed.id;
优化后时间缩短一半!
2.3 对于关联sql的优化
1)关联字段加索引
2)小表驱动大表(略)
2.4 索引设计原则
1)代码先行、索引后上
并非建完表就立马建索引,一般是主体业务功能开发完,把涉及到该表相关的sql都要拿出来分析之后在建立索引。
2)联合索引尽量覆盖条件
即每一个联合索引尽量取sql语句里的where、order by、group by的字段,还要确保这些字段顺序尽量满足sql查询的最左前缀原则。
3)不要在小基数字段上建立索引
索引基数指这个字段在表里有多少个不同的值,比如一张表里有100万的数据,其中性别字段不是男就是女,那么该字段基数就是2,这种小基数建索引,还不如全表扫描来的快。
4)长字符串采用前缀索引
比如一个字段里截取前20位作为索引;
5)索引列的类型尽量小
数据类型越小,在查询时进行的比较操作越快;
数据类型越小,索引占用的存储空间越小,在一个数据页内就可以放下更多的记录,从而减少磁盘I/O带来的性能损耗,也就意味着可以将更多的数据页缓存在内存中,从而加快读写效率。
2.5索引约束
1)超过3个表禁止join(MYSQL扩展性差,优先选择在java层利用代码拆分),需要join的字段,数据类型保持绝对一致;多表关联时,保证被关联的字段需要有索引;
2)业务上具有唯一特性的字段,即使是组合字段,也必须建成唯一索引。(索引对insert的影响是很小的,即使在应用层做了非常完善的校验,只要没有唯一索引,根据墨菲定律,必定有脏数据产生)
3)在varchar字段上建索引,必须指定索引长度,没必要对全字段建立索引。
2.6 无索引行锁会升级为表锁
锁主要是加在索引上,如果对非索引字段更新,行锁可能会变表锁
session1执行:UPDATE account SET balance=800 WHERE name='lisi';
session2 对该account表任意操作都会阻塞
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁,并且该索引不能失效,否则都会从行锁升级为表锁
锁优化建议(记住第一点即可)
- 尽可能让所有数据检索都通过索引来完成,避免无索引行锁升级为表锁;
- 合理设计索引,尽量缩小锁的范围;
- 尽可能减少检索条件范围,避免间隙锁(间隙锁+mysql隔离级别可重复读可以解决幻读的问题);
- 尽量控制事务大小,减少锁定资源量和时间长度,涉及事务加锁的sql尽量放在事务最后执行;
- 尽可能低级别事务隔离;
3、MVCC(多版本并发控制)
当多个事务同时操作(增删改)一张表时,数据库是如何保证每个事务当前的操作不受其他事务的影响?这里就是使用的MVCC机制(读已提交和可重复读都实现了MVCC机制),目的解决读写冲突。
MVCC的实现原理主要是依赖记录中的 3个隐式字段,undo日志 ,Read View 来实现的。
3.1undo日志版本链与read view机制详解
undo日志版本链是指一行数据被多个事务依次修改后,在每个事务修改完后,Mysql会保留修改前的数据undo回滚日志,并且两个隐藏字段trx_id和roll_pointer把这些undo日志串联起来形成一个历史记录版本链(如下图)

在可重复读隔离级别,当事务开启,执行任何查询sql时会生成当前事务的一致性视图read-view,该视图在事务结束之前都不会变化(如果是读已提交隔离级别在每次执行查询sql时都会重新生成),这个视图由执行查询时所有未提交事务id数组(数组里最小的id为min_id)和已创建的最大事务id(max_id)组成,事务里的任何sql查询结果需要从对应版本链里的最新数据开始逐条跟read-view做对比,从而得到最终的快照结果。
3.2 版本链比对规则:
1、如果row的trx_id落在绿色部分(tri_id<min_id),表示这个版本是已提交的事务生成的,这个数据是可见的;
2、如果row的trx_id落在红色部分(tri_id>max_id),表示这个事务是由将来启动的事务生成的,是肯定不可见的;
3、如果row的trx_id落在黄色部分,那就包含两种情况
a、若row的trx_id在视图数组中,那么表示这个版本是由还没提交的事务生成的,不可见,当前自己的事务是可见的;
b、若row的trx_id不在视图数组中,表示这个版本是已经提交了的事务生成的,可见。














 3485
3485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









