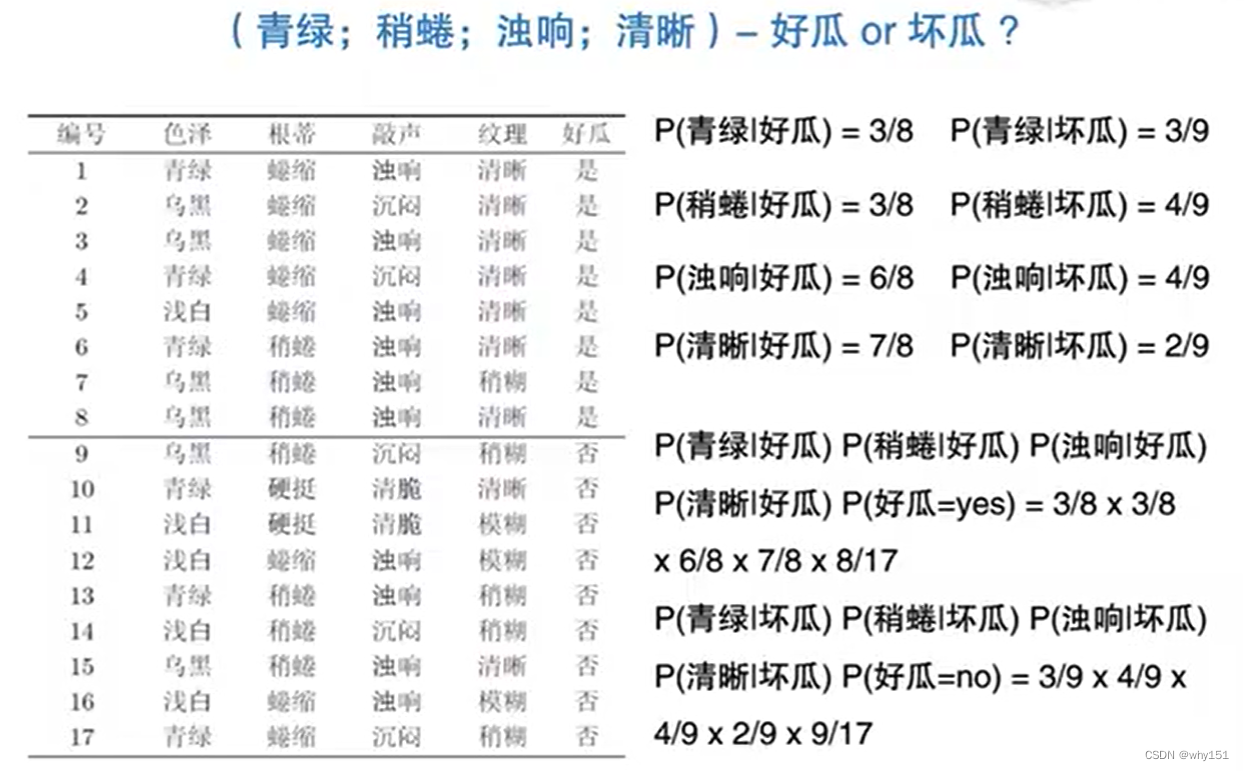
贝叶斯决策论 贝叶斯分类器:使用贝叶斯公式 贝叶斯学习:使用分布估计(不同于频率主义的点估计) 极大似然估计 朴素贝叶斯分类 半朴素贝叶斯 条件独立性假设,在现实生活中往往很难成立。 半朴素贝叶 斯的一个常用策略:独依赖估计,假设每个属性在类别之外最多依赖一个其他属性。 贝叶斯网、EM算法 见第14章


















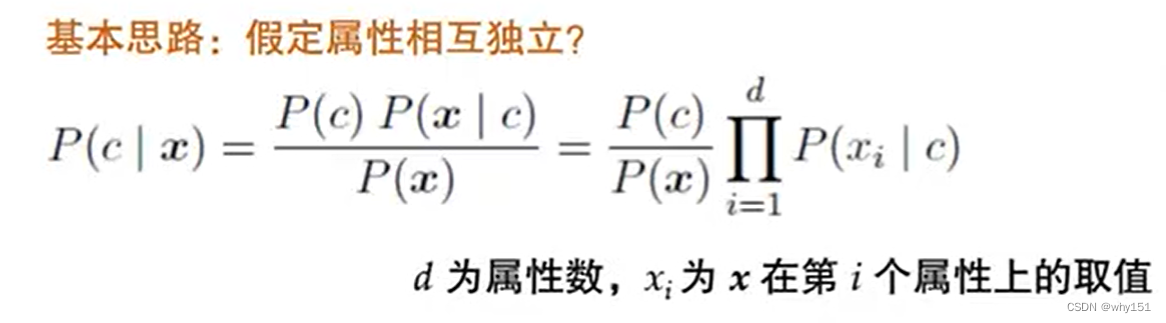
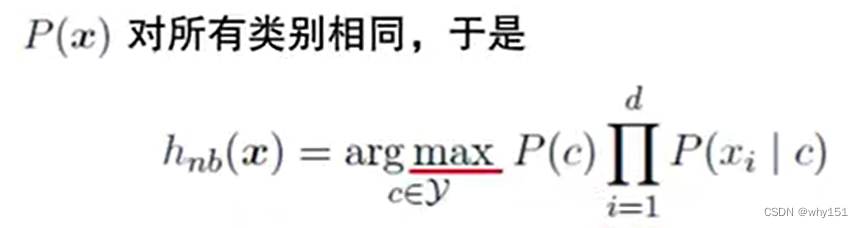

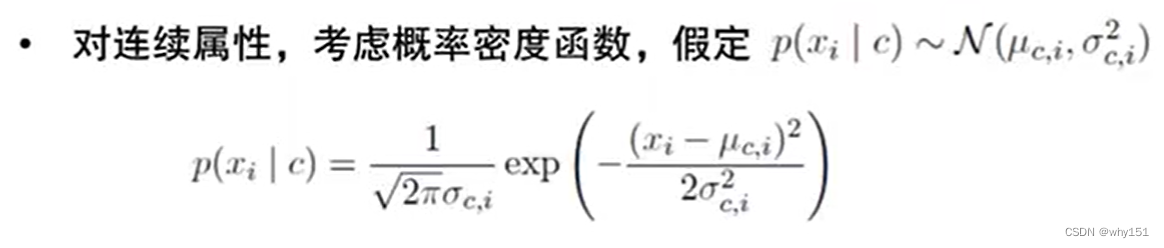

















 2326
2326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






