







HTTP(HyperText Transfer Protocol)使目前使用最广泛的Web应用程序使用的基础协议,是基于TCP协议之上的一种请求-响应协议
服务器与客户端之间的连接如下:
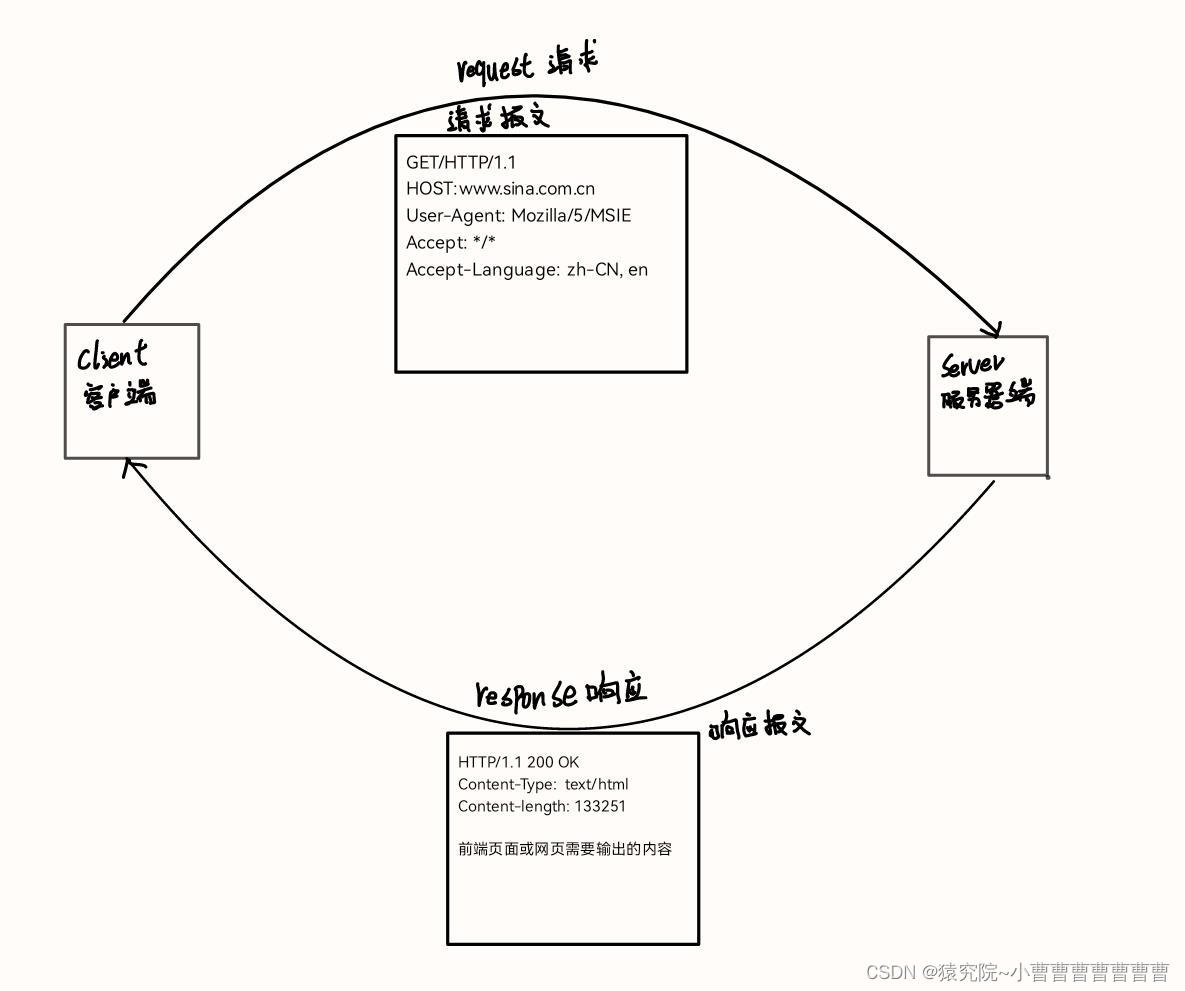
HTTP的请求由HTTP Header和HTTP Body两部分构成,图片所示为Header部分内容,服务器主要依靠某些特定的Header来识别客户端的请求
- Host: 请求的域名,用于确定请求发给哪个网站。由于一台服务器可能托管多个网站,因此通过Host字段来识别目标网站。
- User-Agent: 客户端标识信息,不同的浏览器使用不同的标识。服务器可以根据User-Agent字段判断客户端的类型,如IE、Chrome、Firefox或Python爬虫等。
- Accept: 客户端能够处理的HTTP响应格式。通配符*/*表示接受任意格式,text/*表示接受任意文本格式,image/png表示接受PNG格式的图片。
- Accept-Language: 客户端接受的语言类型,可以按照优先级排序。服务器可以根据此字段返回适合用户语言偏好的网页版本。
如果是GET请求,那么只有Header即可,如果是POST请求,则还需Body,且Header与Body之间必须有空行分隔,如下:
POST /login HTTP/1.1
Host: www.example.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 30
username=hello&password=123456HTTP响应:
HTTP的响应也是由Header与Body组成,如下:
HTTP/1.1 200 OK
Content-Type: text/html
Content-Length: 133251
<!DOCTYPE html>
<html><body>
<h1>Hello</h1>
...Content-Type: 响应文本的类型,可以是image/text/html/
Content-Length:响应文本的长度(可不写)
响应文本为简单文本如下(客户端为浏览器):
//基于Http协议(应用层)+TCP协议(传输层)的服务器端
public class Server {
public static void main(String[] args) {
// 传输层使用TCP协议处理应用层请求
try(ServerSocket serverSocket = new ServerSocket(8009)){
//访问时主机ip+:+8009 例:193.168.254.138:8009
while(true) {
//监听端口,等待客户浏览器的请求
Socket clientSocket = serverSocket.accept();
//服务器按照Http协议向客户端进行响应
//响应文本
try(OutputStream out = clientSocket.getOutputStream()){
out.write("HTTP/1.1 200 OK\r\n".getBytes());//必须有,每一条响应头都需要换行
out.write("Content-Type: text/html\r\n".getBytes());
out.write("Content-Length: 133251\r\n".getBytes());
//响应头和具体响应内容中间有一个空行
out.write("\r\n".getBytes());
//具体响应内容
out.write(UUID.randomUUID().toString().getBytes());
out.flush();
}
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}我们首先通过TCP协议来进行网络连接,并且监听端口,等待客户端响应;服务器则按照Http协议将包含响应头和具体响应内容的响应内容与客户端进行响应(当使用自己主机时也可在浏览器输入127.0.0.1:8009)
响应的类型为图片时:
//响应图片
public class imgServer {
public static void main(String[] args) {
// 传输层使用TCP协议处理应用层请求
try(ServerSocket serverSocket = new ServerSocket(8009)){
//访问时主机ip+:+8009 例:193.168.254.138:8009
while(true) {
//监听端口,等待客户浏览器的请求
Socket clientSocket = serverSocket.accept();
//服务器按照Http协议向客户端进行响应
//响应文本
try(OutputStream out = clientSocket.getOutputStream()){
byte[] image = Files.readAllBytes(Paths.get("E:\\猿究院\\20230707\\第.jpg"));
out.write("HTTP/1.1 200 OK\r\n".getBytes());//必须有,每一条响应头都需要换行
out.write("Content-Type: image/jpeg\r\n".getBytes());
out.write(("Content-Length:"+image.length+"\r\n").getBytes());
//响应头和具体响应内容中间有一个空行
out.write("\r\n".getBytes());
//具体响应图片
out.write(image);
out.flush();
}
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
多次刷新可能会影响性能,修改如下:
try(OutputStream out = clientSocket.getOutputStream();
FileInputStream fis = new FileInputStream("E:\\猿究院\\20230707\\第.jpg")){
//byte[] image = Files.readAllBytes(Paths.get("E:\\猿究院\\20230707\\第.jpg"));
out.write("HTTP/1.1 200 OK\r\n".getBytes());//必须有,每一条响应头都需要换行
out.write("Content-Type: image/jpeg\r\n".getBytes());
out.write(("Content-Length:"+fis.available()+"\r\n").getBytes());
//响应头和具体响应内容中间有一个空行
out.write("\r\n".getBytes());
//具体响应图片
//out.write(image);
byte[] buff = new byte[1024];
int len = -1;
while((len= fis.read(buff))!=-1) {
out.write(buff);
out.flush();
} HTTP请求:
以上代码主要是当客户端为浏览器时,模拟服务器端与客户端进行响应,我们同样可以模拟客户端,发起对http的请求(包含浏览器请求头),获取某个网页的信息,普通代码如下:
public class Fetch {
public static void main(String[] args) {
try {
// 创建url对象,代表一个网址(统一资源定位符)
URL url = new URL("https://tech.163.com");
//发起请求,打开应用程序与服务器之间的连接
HttpsURLConnection connection = (HttpsURLConnection) url.openConnection();
//System.out.println(connection);
connection.setRequestMethod("GET");//请求方式
connection.setConnectTimeout(3000);//超时时间
//请求头信息,模拟请求
connection.setRequestProperty("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7");
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.67");
connection.connect();
//处理响应
//获取中文时可能出现乱码,对文字进行处理
try(BufferedReader reader = new BufferedReader(new InputStreamReader(connection.getInputStream(),StandardCharsets.UTF_8))){
String line = null;
while((line = reader.readLine())!=null) {
System.out.println(line);
}
}
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}在模拟请求获取某个网页信息时,需要使用其认可的请求头,请求头的查看方法为打开网页-->右击选择检查-->网络-->重新刷新页面

扩展:
以上方法模拟请求获取到了该页面的所有信息,但是在提取页面信息时,使用字符串很难进行处理,开源库Jsoup则可以对html的格式进行处理,例如提取该页面的所有标题
public class Fetch {
public static void main(String[] args) {
try {
// 创建url对象,代表一个网址(统一资源定位符)
URL url = new URL("https://tech.163.com");
//发起请求,打开应用程序与服务器之间的连接
HttpsURLConnection connection = (HttpsURLConnection) url.openConnection();
//System.out.println(connection);
connection.setRequestMethod("GET");//请求方式
connection.setConnectTimeout(3000);//超时时间
//请求头信息,模拟请求
connection.setRequestProperty("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7");
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.67");
connection.connect();
//处理响应
//读取来自服务器的响应内容
StringBuilder response = new StringBuilder(8192);
try(BufferedReader reader = new BufferedReader(new InputStreamReader(connection.getInputStream(),StandardCharsets.UTF_8))){
String line = null;
while((line = reader.readLine())!=null) {
response.append(line);
}
}
//jsoup开源库:解析HTML格式的工具
//加载使用整个页面html内容
Document document = Jsoup.parse(response.toString());
//查找<div class = "newDigest">
Elements elements = document.select("div[class=banner_main]");
for(Element div : elements) {
//获取div标签下的第一个element子节点
Element p1 = div.firstElementChild();
Element p2 = p1.firstElementChild();
//注意,div.firstChild()获取第一个子节点,可能获取到的值是换行符
//获取新闻标题
String title = p2.text();//获取标题之间的文本内容
System.out.println(title);
}
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}













 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









