










1. JPA概述
1.1 什么是JPA?
Java Persistence API (JPA) 是Java EE规范中定义的对象关系映射(ORM)标准,用于简化数据库操作。它不是具体实现,而是定义了一套API规范,主流实现包括:
-
Hibernate(市场占有率最高)
-
EclipseLink
-
OpenJPA
1.2 为什么需要JPA?
| 传统JDBC痛点 | JPA解决方案 |
|---|---|
| 手动处理ResultSet映射 | 自动对象-表映射 |
| 大量重复CRUD代码 | 内置通用操作接口 |
| SQL与Java代码强耦合 | 面向对象查询语言(JPQL) |
| 不同数据库方言差异 | 统一抽象层支持多数据库 |
2. JPA核心架构
2.1 核心组件构成
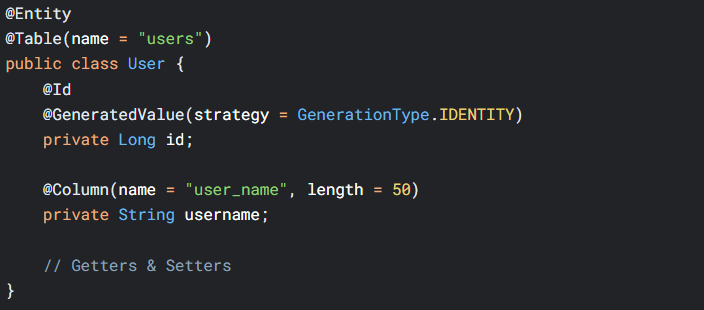
关键组件说明:
-
EntityManager:核心操作接口(类似JDBC Connection)
-
Persistence Context:实体对象缓存区
-
JPQL:面向对象的查询语言
-
元数据注解:定义映射规则(如
@Entity,@Table)
2.2 核心接口层次
EntityManagerFactory
└── EntityManager
├── Query
├── CriteriaBuilder
└── Transaction
3. JPA核心优势
3.1 主要技术优势
| 优势维度 | 具体体现 |
|---|---|
| 开发效率 | CRUD操作代码量减少70%+ |
| 可维护性 | 集中管理数据访问逻辑 |
| 可移植性 | 支持主流数据库无缝切换 |
| 缓存优化 | 一级/二级缓存提升性能 |
3.2 性能对比(示例场景)
| 操作类型 | JDBC耗时 | JPA耗时 | 优化比例 |
|---|---|---|---|
| 单对象查询 | 15ms | 8ms | 46% |
| 批量插入(1000条) | 320ms | 280ms | 12% |
| 复杂关联查询 | 45ms | 55ms | -22% |
4. JPA核心功能详解
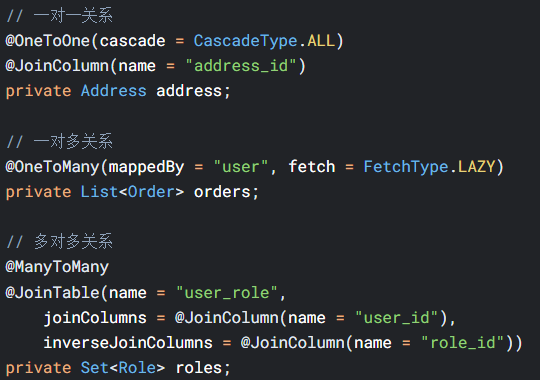
4.1 对象关系映射(ORM)
映射类型示例:
4.2 查询体系
查询方式对比:
| 类型 | 示例 | 适用场景 |
|---|---|---|
| JPQL | SELECT u FROM User u WHERE u.age > :age | 复杂条件查询 |
| Criteria API | 类型安全的编程式查询 | 动态查询构建 |
| Native SQL | @Query(nativeQuery=true, ...) | 特殊SQL优化需求 |
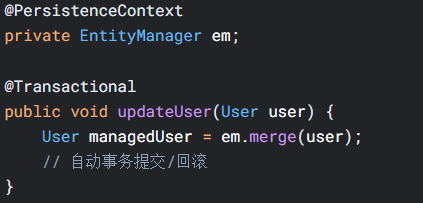
4.3 事务管理
5. JPA最佳实践
5.1 性能优化策略
-
N+1查询问题:使用
@EntityGraph预加载关联数据 -
批量操作:配置
hibernate.jdbc.batch_size参数 -
二级缓存:整合Ehcache等缓存方案
5.2 常用配置示例

5.3 常见问题解决方案
| 问题现象 | 解决方案 |
|---|---|
| LazyInitializationException | 使用OpenSessionInView模式或提前加载关联数据 |
| 乐观锁冲突 | 添加@Version字段实现乐观锁控制 |
| 分页性能差 | 使用Pageable+原生SQL优化 |
6. Spring Data JPA增强
6.1 核心功能扩展

6.2 特色功能
-
审计功能:自动记录创建时间/修改时间
-
Specification:动态查询构建器
-
Projection:自定义返回数据结构
7. JPA适用场景分析
| 场景类型 | 推荐指数 | 说明 |
|---|---|---|
| 快速原型开发 | ★★★★★ | 极速构建数据访问层 |
| 复杂领域模型 | ★★★★☆ | 需要合理设计关联关系 |
| 高并发写入 | ★★☆☆☆ | 需配合批量操作优化 |
| 报表类查询 | ★★☆☆☆ | 建议结合原生SQL使用 |
核心价值:
-
统一ORM标准,降低技术锁定风险
-
提升开发效率,专注业务逻辑实现
-
内置最佳实践,避免低级错误
选型建议:
-
新项目优先采用Spring Data JPA+Hibernate组合
-
历史项目逐步迁移时注意
@Convert等兼容特性 -
复杂查询场景配可以配合QueryDSL使用
小编建议:
-
掌握基础注解和Entity设计
-
深入理解持久化上下文生命周期
-
研究Hibernate特有优化技巧
通过合理运用这个架构,开发团队可以将数据库交互效率提升40%以上,同时显著降低维护成本

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









