







工具准备
开发工具:pycharm
开发环境:python3.7, Windows11
使用工具包:requests
项目思路解析
做爬虫案例首先需要明确自己的采集目标,白又白这里采集的是当前网页的所有图片信息,有目标后梳理自己的代码编写流程,爬虫的基本四步骤:
- 第一步:获取到网页资源地址
- 第二步:对地址发送网络请求
- 第三步:提取对应数据信息
- 提取数据的方式一般有正则、xpath、bs4、jsonpath、css选择器
- 第四步:保存数据信息
第一步:找数据地址
数据的加载方式一般有两种,一种静态一种动态,当前网页的数据在往下刷新时不断的加载数据,可以判断出数据加载的方式为动态的,动态数据需要通过浏览器的抓包工具获取,鼠标右击点击检查,或者按f12的快捷方式,找到加载的数据地址
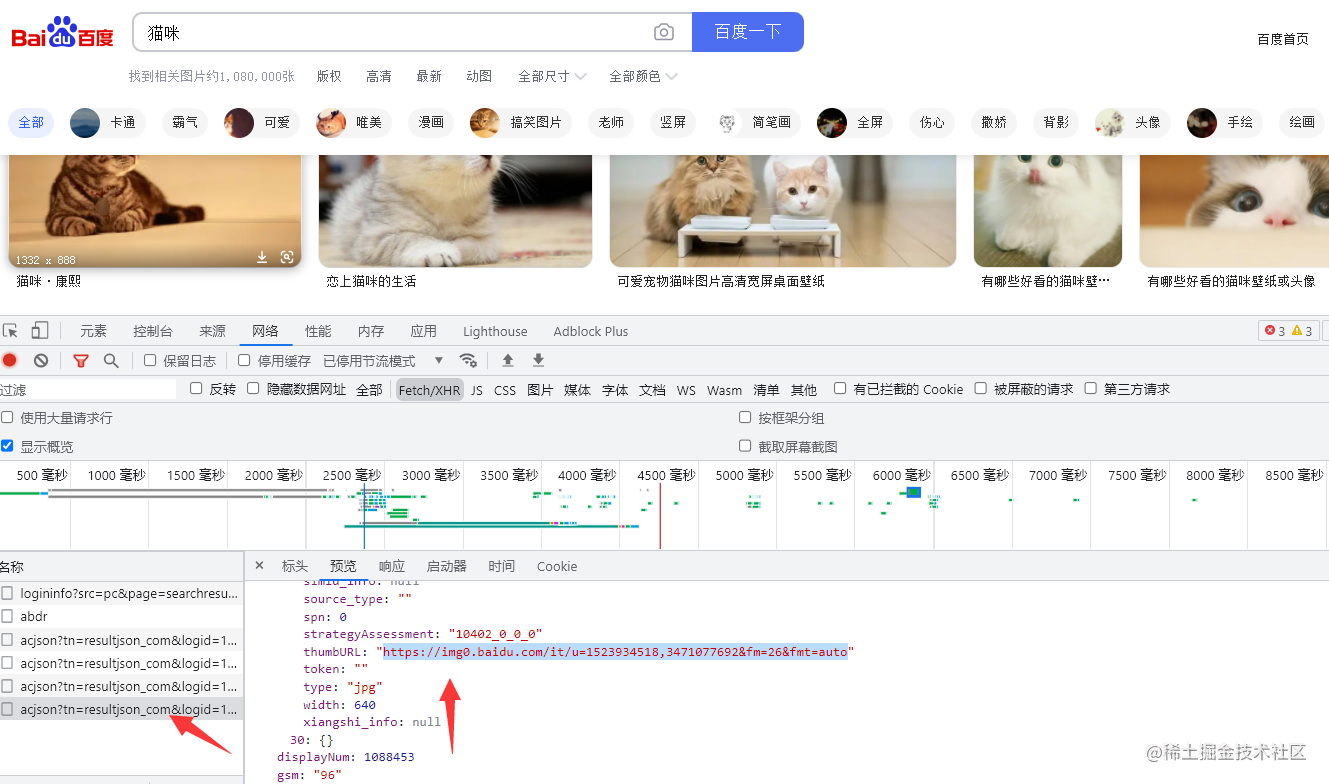
找到对应数据地址,点击弹出的接口后可以点击预览,预览打开的页面是展示给我们的数据,在数据多的时候通过他来进行查看,获取的数据是通过网址获取的,网址数据在请求里,对网址发送网络请求
第二步:代码发送网络请求
发送请求的工具包会非常多,入门阶段更多的是使用requests工具包,requests是第三方工具包,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3043
3043











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









