







代码解释在注释部分,有其他疑问可以评论区提问
本文内容原创,请勿转载!
需要手动敲的代码部分:
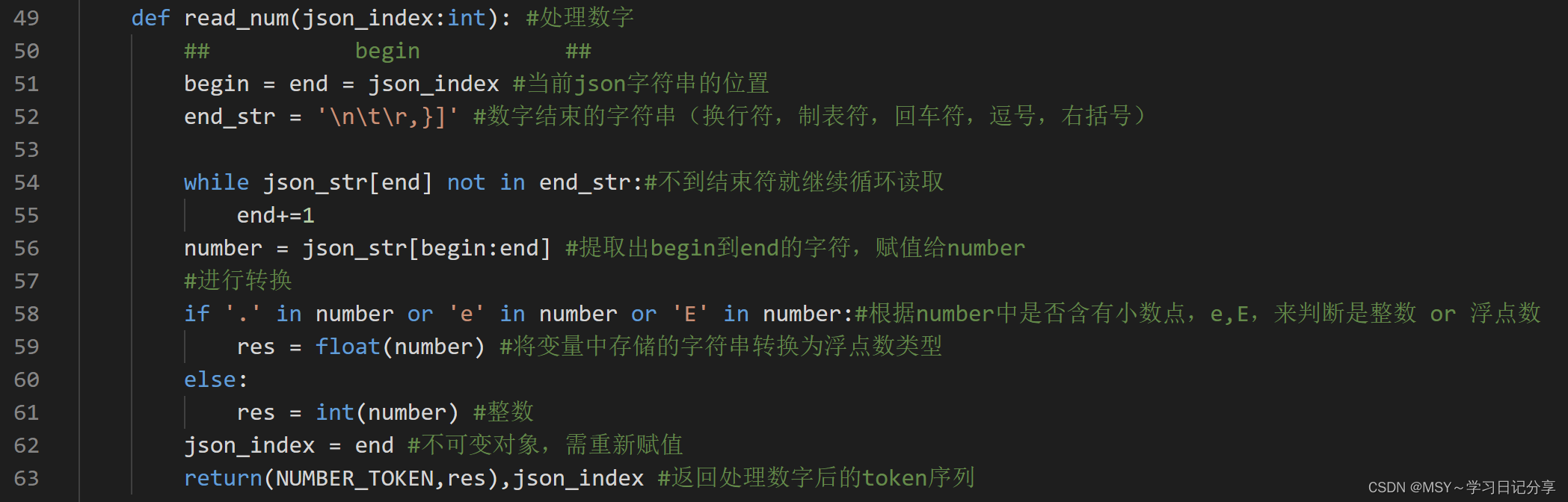
(一)处理数字
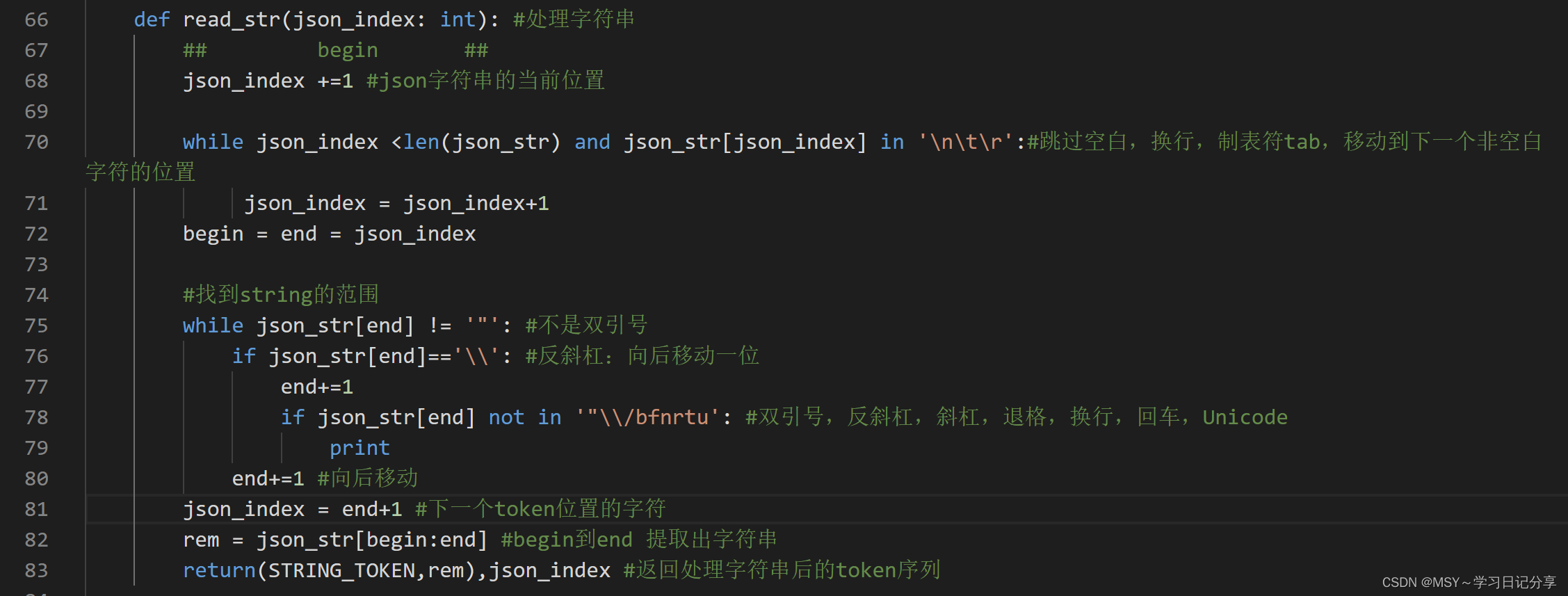
(二)处理字符串
源码:
from typing import List
from enum import Enum
"""
全局标量定义来表示符合 JSON 所规定的数据类型
(学生可以使用字典结构表示此结构)
其中:
BEGIN_OBJECT({)
END_OBJECT(})
BEGIN_ARRAY([)
END_ARRAY(])
NULL(null)
NUMBER(数字)
STRING(字符串)
BOOLEAN(true/false)
SEP_COLON(:)
SEP_COMMA(,)
"""
# Signal token
BEGIN_OBJECT = 1
BEGIN_ARRAY = 2
END_OBJECT = 4
END_ARRAY = 8
# variable token
NULL_TOKEN = 16
NUMBER_TOKEN = 32
STRING_TOKEN = 64
BOOL_TOKEN = 128
# separator token
COLON_TOKEN = 256
COMMA_TOKEN = 512
# end signal
END_JSON = 65536
# json index
json_index = 0
def token_parse(json_str: str, json_index: int) -> (tuple, int):
"""
完成词法解析,返回token
:param json_str: 输入的json字符串
:param json_index: json字符串的位置
:return: 返回已处理好的token和json字符串的位置
"""
def read_num(json_index:int): #处理数字
## begin ##
begin = end = json_index #当前json字符串的位置
end_str = '\n\t\r,}]' #数字结束的字符串(换行符,制表符,回车符,逗号,右括号)
while json_str[end] not in end_str:#不到结束符就继续循环读取
end+=1
number = json_str[begin:end] #提取出begin到end的字符,赋值给number
#进行转换
if '.' in number or 'e' in number or 'E' in number:#根据number中是否含有小数点,e,E,来判断是整数 or 浮点数
res = float(number) #将变量中存储的字符串转换为浮点数类型
else:
res = int(number) #整数
json_index = end #不可变对象,需重新赋值
return(NUMBER_TOKEN,res),json_index #返回处理数字后的token序列
def read_str(json_index: int): #处理字符串
## begin ##
json_index +=1 #json字符串的当前位置
while json_index <len(json_str) and json_str[json_index] in '\n\t\r':#跳过空白,换行,制表符tab,移动到下一个非空白字符的位置
json_index = json_index+1
begin = end = json_index
#找到string的范围
while json_str[end] != '"': #不是双引号
if json_str[end]=='\\': #反斜杠:向后移动一位
end+=1
if json_str[end] not in '"\\/bfnrtu': #双引号,反斜杠,斜杠,退格,换行,回车,Unicode
print
end+=1 #向后移动
json_index = end+1 #下一个token位置的字符
rem = json_str[begin:end] #begin到end 提取出字符串
return(STRING_TOKEN,rem),json_index #返回处理字符串后的token序列
def read_null():
"""
处理null
:return: 返回处理null后的token序列
"""
rem = json_str[json_index: json_index + 4]
return (NULL_TOKEN, rem), json_index + 4
def read_bool(s: str):
"""
处理true,false
:param s: json字符串
:return: 返回处理true,false后的token序列
"""
if s == 't':
rem = json_str[json_index: json_index + 4]
return (BOOL_TOKEN, rem), json_index + 4
else:
rem = json_str[json_index: json_index + 5]
return (BOOL_TOKEN, rem), json_index + 5
if json_index == len(json_str):
return (END_JSON, None), json_index
elif json_str[json_index] == '{':
return (BEGIN_OBJECT, json_str[json_index]), json_index + 1
elif json_str[json_index] == '}':
return (END_OBJECT, json_str[json_index]), json_index + 1
elif json_str[json_index] == '[':
return (BEGIN_ARRAY, json_str[json_index]), json_index + 1
elif json_str[json_index] == ']':
return (END_ARRAY, json_str[json_index]), json_index + 1
elif json_str[json_index] == ',':
return (COMMA_TOKEN, json_str[json_index]), json_index + 1
elif json_str[json_index] == ':':
return (COLON_TOKEN, json_str[json_index]), json_index + 1
elif json_str[json_index] == 'n':
return read_null()
elif json_str[json_index] == 't' or json_str[json_index] == 'f':
return read_bool(json_str[json_index])
elif json_str[json_index] == '"':
return read_str(json_index)
if json_str[json_index].isdigit():
return read_num(json_index)
def tokenizer(json_str: str) -> list:
"""
生成token序列
:param json_str:
:return:
"""
json_index = 0
tk, cur_index = token_parse(json_str, json_index)
token_list = []
generate_tokenlist(token_list, tk)
while tk[0] != END_JSON:
tk, cur_index = token_parse(json_str, cur_index)
generate_tokenlist(token_list, tk)
return token_list
def generate_token(tokentype: int, tokenvalue: str) -> tuple:
"""
生成token结构
:param tokentype: token的类型
:param tokenvalue: token的值
:return: 返回token
"""
token = (tokentype, tokenvalue)
return token
def generate_tokenlist(tokenlist: list, token: tuple) -> list:
tokenlist.append(token)
return tokenlist
def parse_json(tokenlist: list):
def check_token(expected: int, actual: int):
if expected & actual == 0:
raise Exception('Unexpected Token at position %d' % json_index)
def parse_json_array():
"""
处理array对象
:return: 处理json中的array对象
"""
global json_index
expected = BEGIN_ARRAY | END_ARRAY | BEGIN_OBJECT | END_OBJECT | NULL_TOKEN | NUMBER_TOKEN | BOOL_TOKEN | STRING_TOKEN
while json_index != len(tokenlist):
json_index += 1
token = tokenlist[json_index]
# token_type -> TokenEnum
token_type = token[0]
token_value = token[1]
check_token(expected, token_type)
# check through each condition
if token_type == BEGIN_OBJECT:
array.append(parse_json_object())
expected = COMMA_TOKEN | END_ARRAY
elif token_type == BEGIN_ARRAY:
array.append(parse_json_array())
expected = COMMA_TOKEN | END_ARRAY
elif token_type == END_ARRAY:
return array
elif token_type == NULL_TOKEN:
array.append(None)
expected = COMMA_TOKEN | END_ARRAY
elif token_type == NUMBER_TOKEN:
array.append(int(token_value))
expected = COMMA_TOKEN | END_ARRAY
elif token_type == STRING_TOKEN:
# print("array-------------array")
array.append(token_value)
expected = COMMA_TOKEN | END_ARRAY
elif token_type == BOOL_TOKEN:
token_value = token_value.lower().capitalize()
array.append({'True': True, 'False': False}[token_value])
expected = COMMA_TOKEN | END_ARRAY
elif COMMA_TOKEN:
expected = BEGIN_ARRAY | BEGIN_OBJECT | STRING_TOKEN | BOOL_TOKEN | NULL_TOKEN | NUMBER_TOKEN
elif END_JSON:
return array
else:
raise Exception('Unexpected Token at position %d' % json_index)
def parse_json_object():
"""
处理json对象
:return:处理json中的json对象
"""
global json_index
expected = STRING_TOKEN | END_OBJECT
key = None
while json_index != len(tokenlist):
json_index += 1
token = tokenlist[json_index]
token_type = token[0]
token_value = token[1]
# print("expected: ", expected, "token_type: ", token_type, "token_value: ", token_value)
check_token(expected, token_type)
if token_type == BEGIN_OBJECT:
obj.update({key: parse_json_object()})
expected = COMMA_TOKEN | END_OBJECT
elif token_type == END_OBJECT:
return obj
elif token_type == BEGIN_ARRAY:
# print("join array")
obj.update({key: parse_json_array()})
expected = COMMA_TOKEN | END_OBJECT | STRING_TOKEN
elif token_type == NULL_TOKEN:
obj.update({key: None})
expected = COMMA_TOKEN | END_OBJECT
elif token_type == STRING_TOKEN:
pre_token = tokenlist[json_index - 1]
pre_token_value = pre_token[0]
# print(pre_token_value)
if pre_token_value == COLON_TOKEN:
value = token[1]
obj.update({key: value})
# print("----------")
expected = COMMA_TOKEN | END_OBJECT
else:
key = token[1]
expected = COLON_TOKEN
# print("+++++++++")
elif token_type == NUMBER_TOKEN:
obj.update({key: int(token_value)})
expected = COMMA_TOKEN | END_OBJECT
elif token_type == BOOL_TOKEN:
token_value = token_value.lower().capitalize()
obj.update({key: {'True': True, 'False': False}[token_value]})
expected = COMMA_TOKEN | END_OBJECT
elif token_type == COLON_TOKEN:
expected = NULL_TOKEN | NUMBER_TOKEN | BOOL_TOKEN | STRING_TOKEN | BEGIN_ARRAY | BEGIN_OBJECT
elif token_type == COMMA_TOKEN:
expected = STRING_TOKEN
elif token_type == END_JSON:
return obj
else:
raise Exception('Unexpected Token at position %d' % json_index)
array = []
obj = {}
global json_index
if tokenlist[0][0] == BEGIN_OBJECT:
return parse_json_object()
elif tokenlist[0][0] == BEGIN_ARRAY:
return parse_json_array()
else:
raise Exception('Illegal Token at position %d' % json_index)
if __name__ == "__main__":
raw_data = input()
jlist = tokenizer(raw_data)
try:
jdict = parse_json(jlist)
print(jdict)
except BaseException as result:
print(result)
















 756
756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









