







1.Python 的 sklearn 扩展包中包含了“威斯康星州乳腺癌”数据集,其中详细记录了 威斯康星大学附属医院的乳腺癌测量数据。数据集包括 569 行和 31 个特征。可以使用 这个数据集训练一个支持向量机模型,参考代码如下。教师给出部分代码。请输出测试 精度。
参考代码: from sklearn.svm import SVC 12 / 15 from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt from matplotlib.colors import ListedColormap # 导入肺癌数据集 data = load_breast_cancer() X = data['data'] y = data['target'] print(X.shape) x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 建立支持向量机模型 clf1 = SVC(kernel='linear') #线性核函数 clf2 = SVC(kernel='rbf', C=10, gamma=0.0001) #采用高斯核函数 clf1.fit(x_train, y_train) clf2.fit(x_train, y_train) # 输出两个 SVM 模型的精度。 此处填入你的代码。
SVM模型,即支持向量机(Support Vector Machine),是一种二类分类模型。其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
以下是一些SVM模型的应用例子:
- 图像分类:SVM可以用于图像分类任务,如人脸识别、物体识别等。在这个过程中,首先会对图像进行预处理,例如调整大小、灰度化等,然后提取图像的特征向量,最后利用这些特征向量进行分类。参考李飞飞在2005年发表的论文《A Bayesian Hierarchical Model for Learning Natural Scene Categories》中的方法,可以通过对每张图进行SIFT+Kmeans聚类+直方图统计构建场景特征的特征库(词库),然后利用SVM对场景进行分类。
- 文本分类:SVM可以通过将文本表示为词袋模型或者TF-IDF等特征表示方法,然后训练一个分类器来实现文本分类。这个过程包括数据预处理(对文本进行清洗、分词、去除停用词等处理)、训练模型(使用SVM算法训练一个分类器)以及测试和评估(使用测试集对分类器进行评估,计算准确率、召回率等指标)。
- 异常检测:SVM也可以应用于异常检测,即通过训练一个SVM模型,可以检测出与其他样本不同的异常样本。在异常检测中,SVM可以识别出那些与正常样本最不相似的样本。
from sklearn.svm import SVC
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
# 导入肺癌数据集
data = load_breast_cancer()
X = data['data']
y = data['target']
print(X.shape)
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 建立支持向量机模型
clf1 = SVC(kernel='linear') #线性核函数
clf2 = SVC(kernel='rbf', C=10, gamma=0.0001) #采用高斯核函数
clf1.fit(x_train, y_train)
clf2.fit(x_train, y_train)
# 输出两种支持向量机模型的精度。此处填入你的代码。(1)
score1 = clf1.score(x_test, y_test) # 线性核函数的SVM模型在测试集上的精度
score2 = clf2.score(x_test, y_test) # 高斯核函数的SVM模型在测试集上的精度
print(f"SVM with linear kernel test accuracy: {score1}")
print(f"SVM with RBF kernel test accuracy: {score2}")
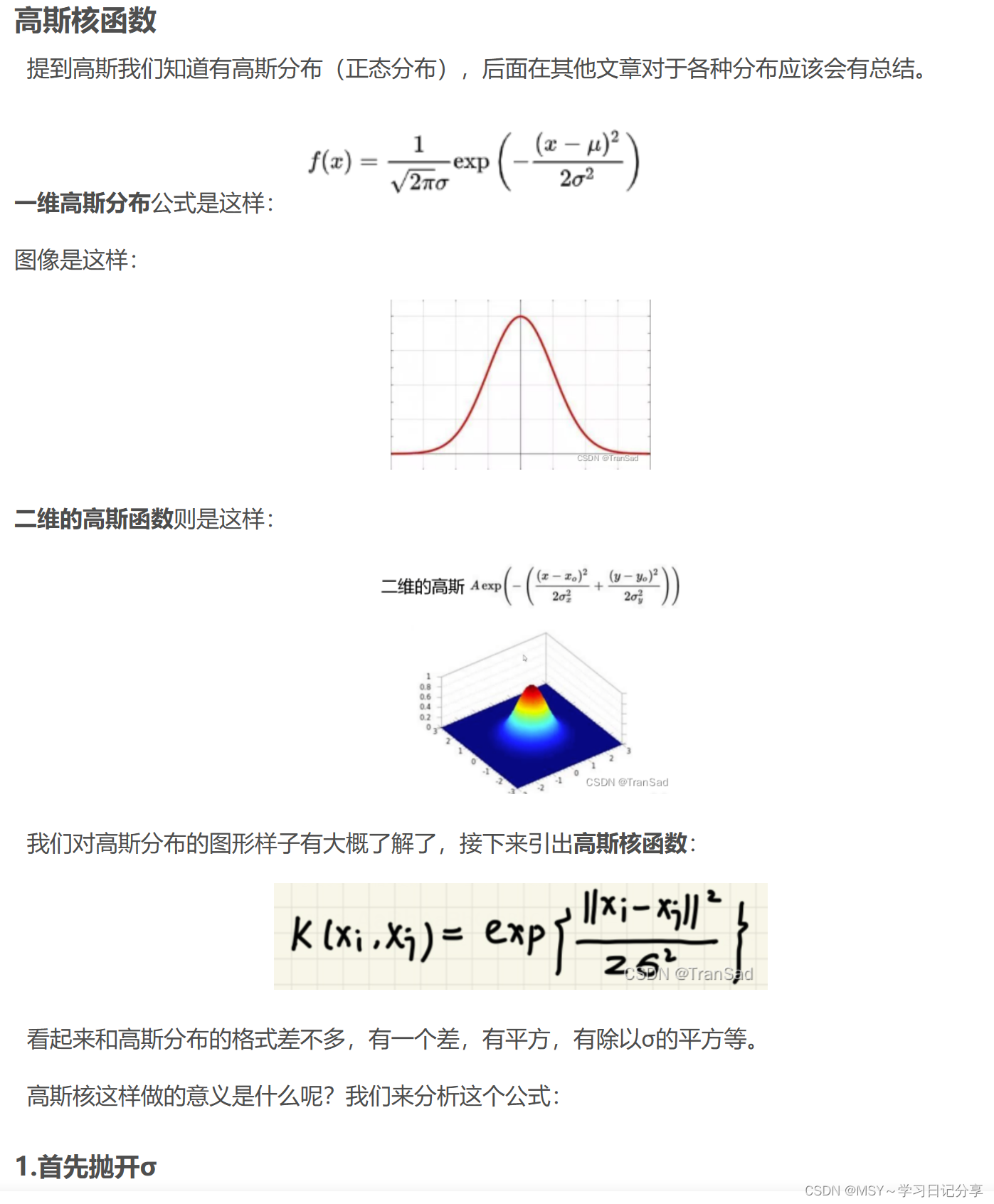
线性核函数和高斯核函数学习参考:


2. 保持公司的员工满意的问题是一个长期存在且历史悠久的挑战。如果公司投入了大量 时间和金钱的员工离开,那么这意味着公司将不得不花费更多的时间和金钱来雇佣其他 人。以 IBM 公司的员工流失数据集(HR-Employee-Attrition.csv)作为处理对象,使用 第三方模块 sklearn 中的相关类来建立支持向量机模型,进行 IBM 员工流失预测。教师 给出部分代码。要求:1)对数据集做适当的预处理操作,2)划分 25%的数据集作为测 试数据,3)输出支持向量,4)输出混淆矩阵,计算查准率、查全率和 F1 度量,并绘 制 P-R 曲线和 ROC 曲线。 说明:数据集的第 2 列(Attrition)为员工流失的类别。
import numpy as np
import pandas as pd
#导入数据,地址根据文件地址更改
df = pd.read_csv('HR-Employee-Attrition.csv')
df.head()
#第一题:数据预处理
df.nunique().nsmallest(10) # 无效列值检查
# EmployeeCount, Over18 and StandardHours 这些属性值完全相同
# 删除无效列值
df.drop(['StandardHours', 'EmployeeCount', 'Over18', 'EmployeeNumber'], axis=1, inplace=True)
df.isnull().sum() # 缺失值检查
df[df.duplicated()] # 重复值检查
df.head()
#中文编码为数字
from sklearn.preprocessing import LabelEncoder
#LabelEncoder对非数字格式列编码
dtypes_list=df.dtypes.values#取出各列的数据类型
columns__list=df.columns#取出各列列名
#循环遍历每一列找出非数字格式进行编码
for i in range(len(columns__list)):
if dtypes_list[i] == 'object':#判断类型
lb=LabelEncoder() # 导入LabelEncoder模型
lb.fit(df[columns__list[i]]) # 训练
df[columns__list[i]] = lb.transform(df[columns__list[i]]) # 编码\
df.head()
#查看各列相关性
import matplotlib.pyplot as plt
import seaborn as sns
corr=df.corr()
corr.head()
sns.heatmap(corr,xticklabels=corr.columns.values,yticklabels=corr.columns.values)
plt.show()
#黑色负相关,白色正相关
'''通过热力图下,可以看到
MonthlyIncome 与 JobLevel 相关性较强;
TotalWorkingYears 与 JobLevel 相关性较强;
TotalWorkingYears 与 MonthlyIncome 相关性较强;
PercentSalaryHike 与 PerformanceRating 相关性较强;
YearsInCurrentRole 与 YearsAtCompany 相关性较强;
YearsWithCurrManager 与 YearsAtCompany 相关性较强;
StockOptionLevel与MaritalStatus成负相关,删除其中一列'''
df.drop(['JobLevel', 'TotalWorkingYears', 'YearsInCurrentRole', 'YearsWithCurrManager',
'PercentSalaryHike', 'StockOptionLevel'],axis=1, inplace=True)
df.head()
# 特征提取
X = df.drop(['Attrition'], axis=1)
y = df['Attrition']
# 标准化数据
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X = sc.fit_transform(X)
mean = np.mean(X, axis=0)
print('均值')
print(mean)
standard_deviation = np.std(X, axis=0)
print('标准差')
print(standard_deviation)
# 第二题:划分 25%的数据集作为测试数据
from sklearn.model_selection import train_test_split
# 此处填入你的代码。(1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
X_train
from sklearn.svm import SVC
from sklearn import metrics
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_curve, auc
# 默认
svc=SVC()
svc.fit(X_train,y_train)
y_pred=svc.predict(X_test)
print('Accuracy Score:')
# 输出Accuracy Score。此处填入你的代码。(2)
accuracy = accuracy_score(y_test, y_pred) # 计算准确率
print(accuracy) # 打印准确率
#输出支持向量
print('支持向量:',np.matrix(svc.fit(X_train, y_train).support_vectors_))
# 第三题:混淆矩阵
y_pred = svc.predict(X_test)
# 获取混淆矩阵。此处填入你的代码。(3)
print('Confusion Matrix:')
cnf_matrix = confusion_matrix(y_test, y_pred)
print(cm)
class_names = [0, 1] # name of classes
fig, ax = plt.subplots()
tick_marks = np.arange(len(class_names))
plt.xticks(tick_marks, class_names)
plt.yticks(tick_marks, class_names)
plt.tight_layout()
plt.title('Confusion matrix', y=1.1)
plt.ylabel('Actual label')
plt.xlabel('Predicted label')
# create heatmap
sns.heatmap(pd.DataFrame(cnf_matrix), annot=True, cmap="YlGnBu", fmt='g')
ax.xaxis.set_label_position("top")
# 第四题:准确度、精确度和召回率
print("Accuracy:", metrics.accuracy_score(y_test, y_pred))
print("Precision:", metrics.precision_score(y_test, y_pred))
print("Recall:", metrics.recall_score(y_test, y_pred))
# 输出F1_score。此处填入你的代码。(4)
print("F1_score:",metrics.f1_score(y_test, y_pred, average='binary'))
#第四题:PR曲线
from sklearn.metrics import precision_recall_curve
y_scores = svc.decision_function(X_test)
plt.figure("P-R Curve")
plt.title('Precision/Recall Curve')
plt.xlabel('Recall')
plt.ylabel('Precision')
#y_test为样本实际的类别,y_scores为样本为正例的概率
precision, recall, thresholds = precision_recall_curve(y_test, y_scores)
# 绘制recall,precision曲线。此处填入你的代码。(5)
plt.plot(recall, precision, marker='.')
# 可选:绘制无信息率线(对角线),表示随机预测的性能
plt.plot([0, 1], [0, 1], linestyle='--')
# 可选:显示网格
plt.grid(True)
# 显示图形
plt.show()
#第四题: 绘制ROC曲线
# 模型预测
# sklearn_predict = sklearn_logistic.predict(X_test)
# y得分为模型预测正例的概率
# y_score = sklearn_logistic.predict_proba(X_test)[:,1]
y_scores= svc.decision_function(X_test)
# 计算不同阈值下,fpr和tpr的组合值,其中fpr表示1-Specificity,tpr表示Sensitivity
fpr,tpr,threshold = metrics.roc_curve(y_test, y_scores)
# 计算AUC的值
roc_auc = metrics.auc(fpr,tpr)
# 绘制面积图
plt.stackplot(fpr, tpr, color='steelblue', alpha = 0.5, edgecolor = 'black')
# 添加边际线
plt.plot(fpr, tpr, color='black', lw = 1)
# 添加对角线
plt.plot([0,1],[0,1], color = 'red', linestyle = '--')
# 添加文本信息
plt.text(0.5,0.3,'ROC curve (area = %0.2f)' % roc_auc)
# 添加x轴与y轴标签
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')
# 显示图形
plt.show()

3. (可选,加分)手写字母的识别问题。对于手写英文字母,可以根据写入字母的特征 信息(字母的宽度、高度、边际)来判断其属于哪一种字母。手写体字母数据集一共包 含 20000 个样本,每个样本有 17 个特征,其中 letter 为类别,具体值就是 20 个英文字 母。请利用对该数据集训练一个 SVM 模型,进行分类判断
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import classification_report
from sklearn.metrics import classification_report, roc_curve, auc, precision_recall_curve
import matplotlib.pyplot as plt
# 假设数据保存在CSV文件中,列名与问题描述中一致
def load_dataset(file_path):
"""
从CSV文件加载数据集。
参数:
file_path (str): 数据集的路径。
返回:
pandas.DataFrame: 加载的数据集。
"""
return pd.read_csv(file_path)
def preprocess_data(df):
"""
预处理数据,包括特征缩放和标签编码。
参数:
df (pandas.DataFrame): 原始数据集。
返回:
tuple: 包含特征矩阵X和标签y的元组。
"""
# 假设第一列是类别列,其余列是特征列
X = df.iloc[:, 1:] # 特征数据
y = df.iloc[:, 0] # 类别数据
# 类别编码,这里我们假设'letter'列已经是字符串形式的字母
# 在实际应用中,可能需要先将其转换为数值型标签
# 这里简化处理,直接使用字母索引作为标签
y = y.map(lambda x: ord(x.upper()) - ord('A'))
# 特征缩放
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
return X_scaled, y
def train_svm_model(X_train, y_train):
"""
训练SVM模型。
参数:
X_train (numpy.ndarray): 训练特征。
y_train (numpy.ndarray): 训练标签。
返回:
SVC: 训练好的SVM模型。
"""
model = SVC(kernel='rbf', C=1.0, gamma='scale') # 使用RBF核,C和gamma设为默认值
model.fit(X_train, y_train)
return model
def evaluate_model(model, X_test, y_test):
"""
评估模型性能。
参数:
model (SVC): 训练好的SVM模型。
X_test (numpy.ndarray): 测试特征。
y_test (numpy.ndarray): 测试标签。
返回:
str: 模型的分类报告。
"""
y_pred = model.predict(X_test)
report = classification_report(y_test, y_pred)
return report
# 假设数据保存在'handwritten_letters.csv'文件中
data_path = 'handwritten_letters.csv'
df = load_dataset(data_path)
X, y = preprocess_data(df)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练SVM模型
svm_model = train_svm_model(X_train, y_train)
# 评估模型
report = evaluate_model(svm_model, X_test, y_test)
print(report)
"""Precision(精确度):精确度衡量的是模型预测为正样本的实例中,真正为正样本的比例。
计算公式为:Precision = TP / (TP + FP),其中TP(True Positives)是真正例,FP(False Positives)是假正例。
Recall(召回率):召回率(也被称为敏感度或真正率)衡量的是所有真正例中被模型正确预测为正样本的比例。
计算公式为:Recall = TP / (TP + FN),其中FN(False Negatives)是假反例。
F1-score:(精确度和召回率的调和平均数),用于综合评估模型的性能。当精确度和召回率都很高时,F1分数也会很高。
计算公式为:F1 = 2 * (Precision * Recall) / (Precision + Recall)。
Support(支持数):支持数指的是每个类别在测试集中的样本数量。在您给出的例子中,每个类别的支持数都是4000,这意味着测试集中有4000个样本属于该类。
Accuracy(准确率):准确率衡量的是模型正确分类的样本比例。
计算公式为:Accuracy = (TP + TN) / (TP + FP + FN + TN),其中TN(True Negatives)是真反例。
没有直接显示整体的准确率,
macro avg:宏观平均值是对每个类别的指标进行简单平均,不考虑类别样本数量的差异。
宏观平均的精确度、召回率和F1分数都是0.95,说明模型在所有类别上的性能都很接近。
weighted avg:加权平均值是根据每个类别的支持数(即样本数量)来加权的指标平均值。
给予样本数量较大的类别更多的权重。由于每个类别的支持数都是4000,加权平均值和宏观平均值是一样的。
基于二分类问题。对于多分类问题,每个类别都会有一个对应的精确度、召回率和F1分数,而宏观平均值和加权平均值则是对所有类别指标的平均。"""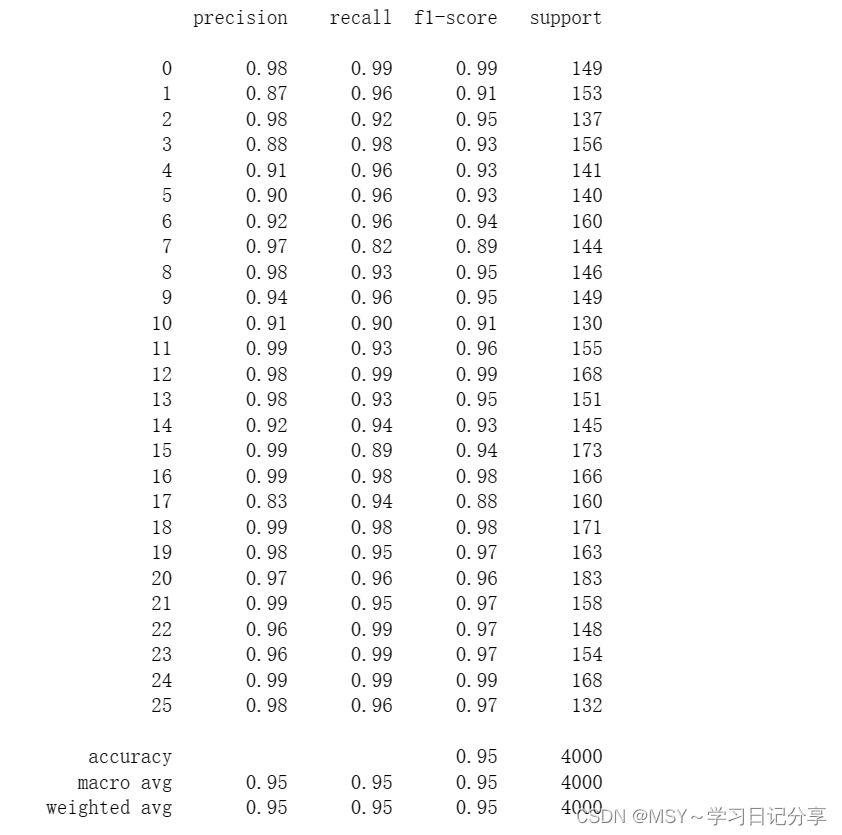

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









