






如题,爬取爱彼迎首页时,返回的数据为空,即返回[]
def parse(self, response):
# self.logger.debug(response.body)
print(type(response))
print("===============")
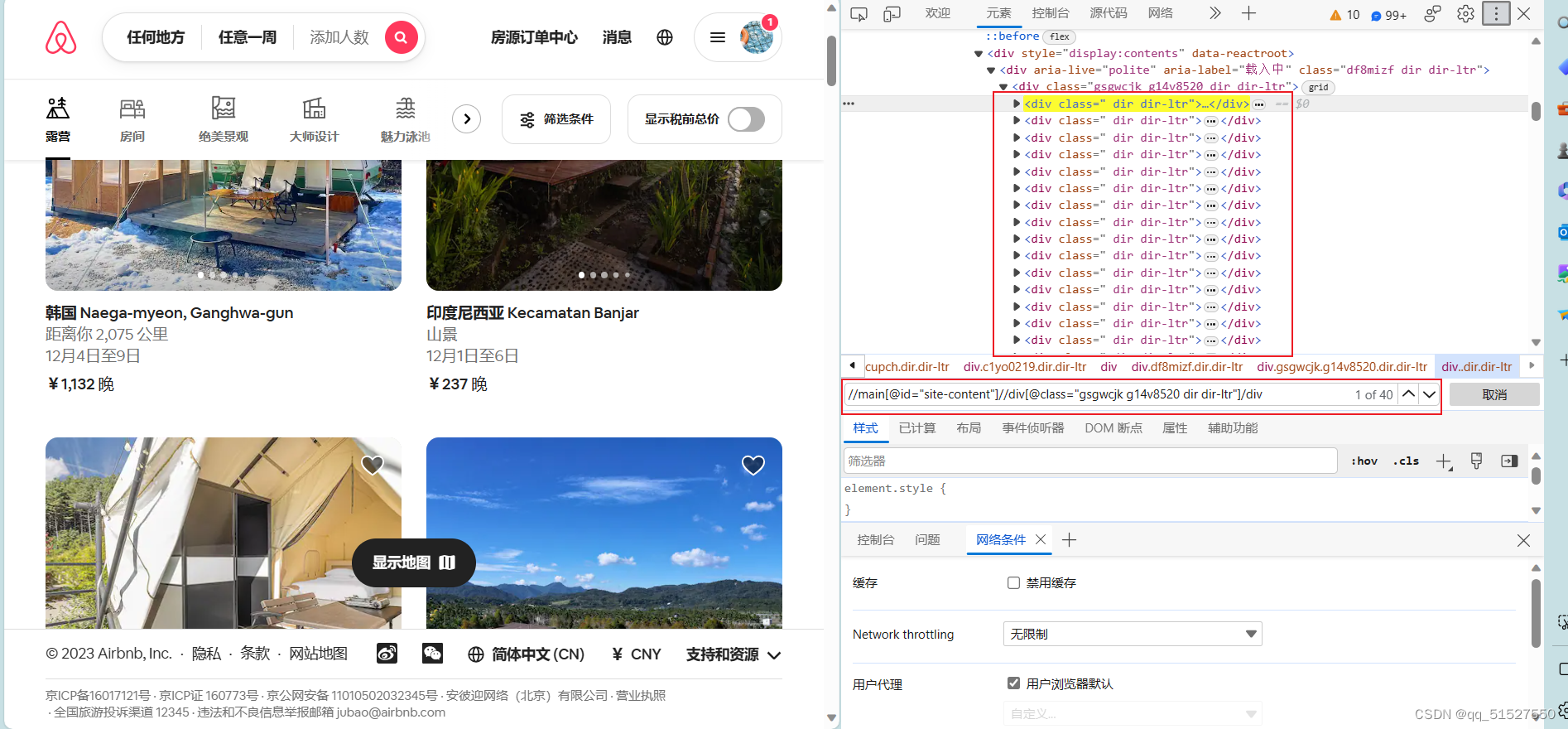
div_list = response.xpath('//main[@id="site-content"]//div[@class="gsgwcjk g14v8520 dir dir-ltr"]/div')
# name = response.xpath('//div[@class="gsgwcjk g14v8520 dir dir-ltr"]/div[@class=" dir dir-ltr"]//div[@class="t1jojoys dir dir-ltr"]')
print(div_list)
确认了xpath是没问题的,在浏览器输入相应的xpath是可以获取到想要的元素的:
“print(”===============")"能执行,说明没有反爬,但是却没有获取到想要的div
![可以看到返回了一个[]](https://img-blog.csdnimg.cn/bf407a7dd406441f90fa9329629e99ae.png)
也检查了没有遵守“君子协议”
**原因:**如果目标网站使用JavaScript来渲染页面内容,Scrapy默认情况下可能无法获取到动态生成的内容。
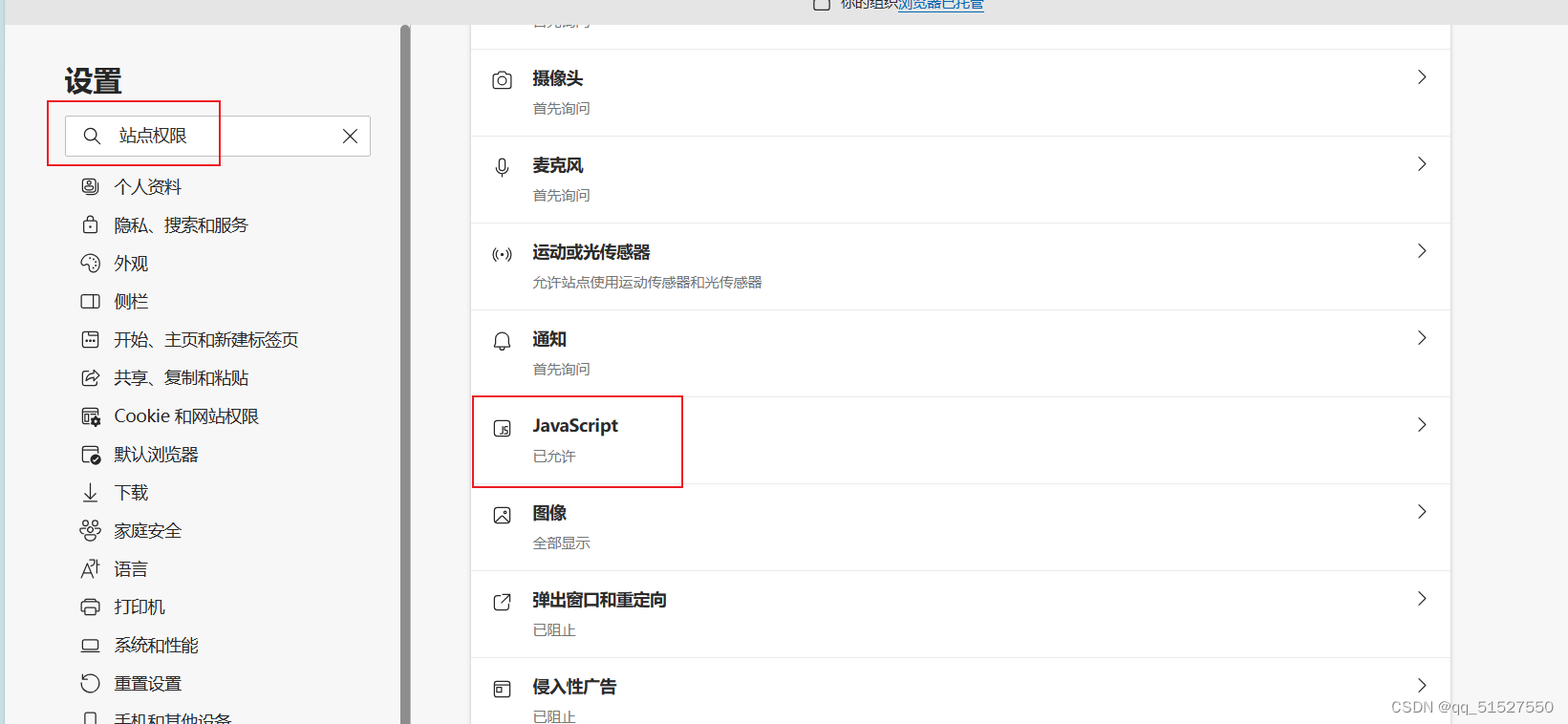
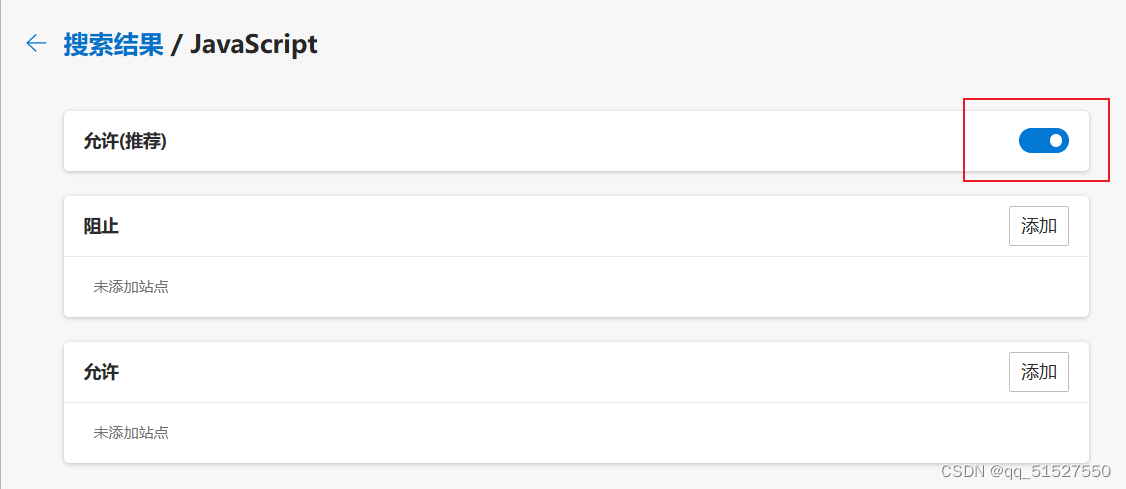
**验证:**在浏览器禁用JavaScript,观察页面是否会发生变化。方法:(以Edge浏览器示范)在浏览器中点开设置,搜索“站点权限”,找到“JavaScript",然后点进去,将”允许“的开关关掉。
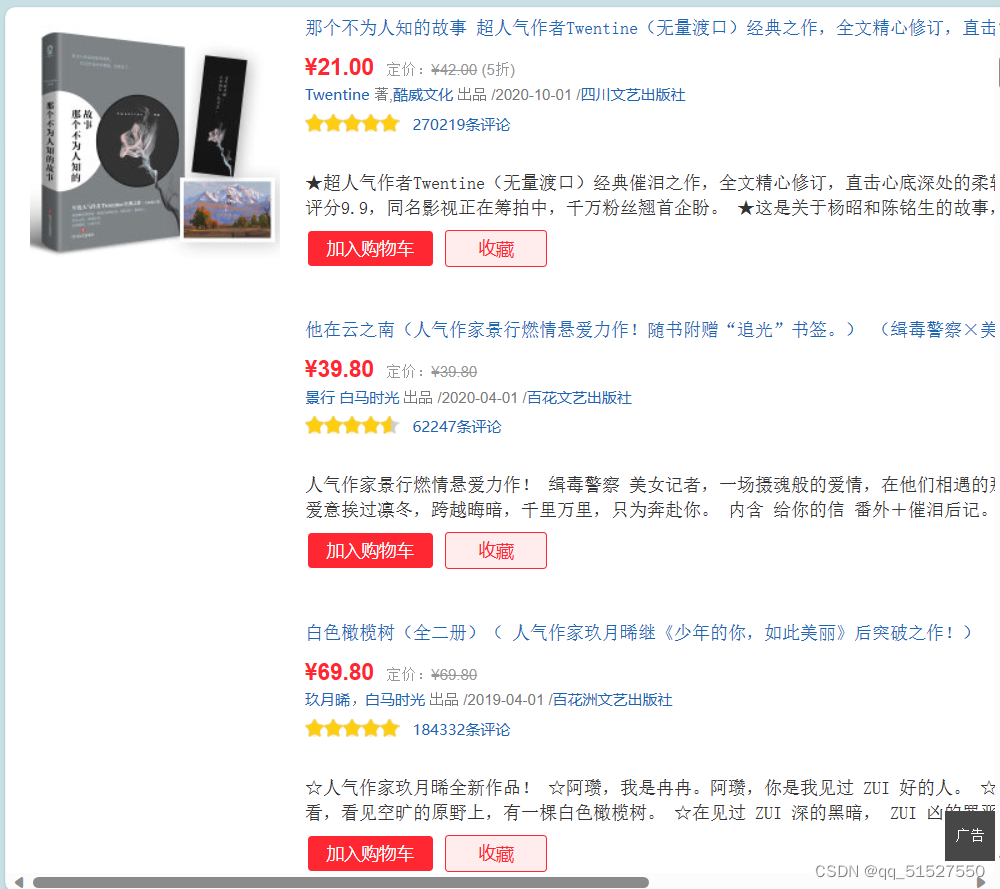
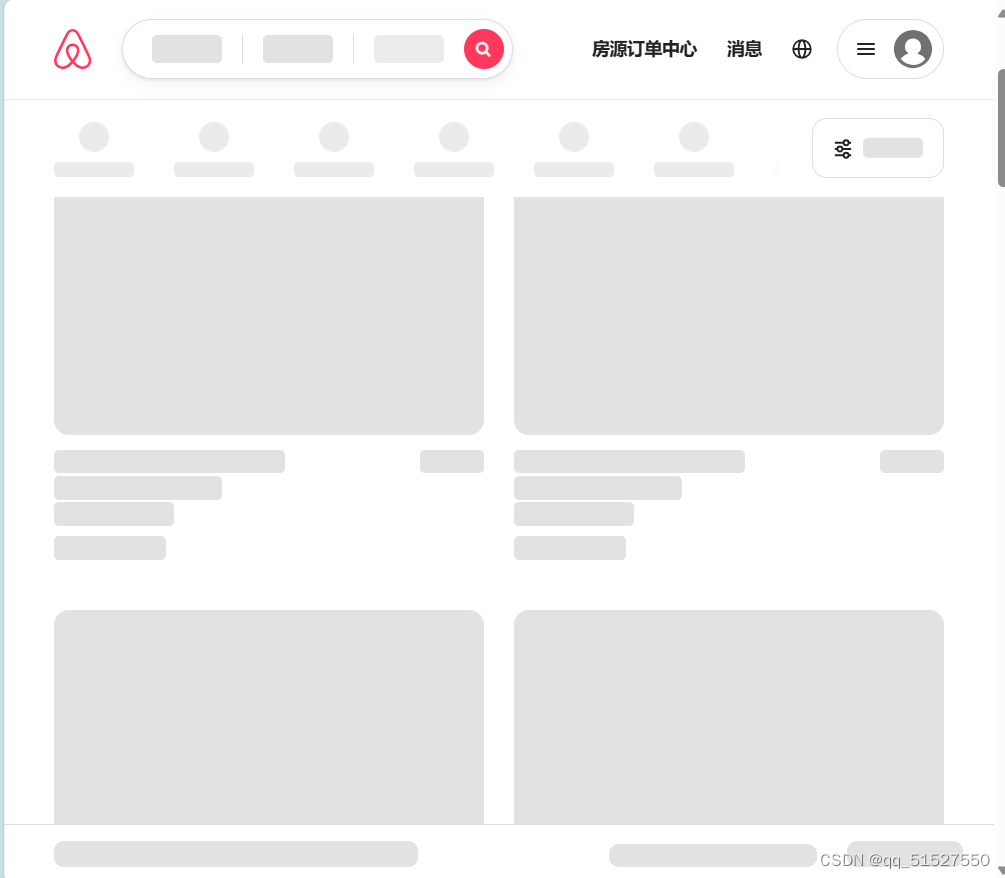
禁用JavaScript之后,拿之前能爬取成功的当当网检验,可以看到禁用之后,还是可以看到图书信息的。但是爱彼迎的话就会显示不出房源信息,说明了爱彼迎的页面用了JavaScript渲染。所以才会爬取不到。
**解决:**可以用selenium进行爬取,笔者还没有试验过,待更新。















 9850
9850











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









