






背景概述
Leader告诉我一个需求:需要统计前台客户页面的文章阅读数、以及其他访问信息。之前也没有接触过这块,因此开始针对访问信息收集的研究。也借此机会,在模块开发完成之际,对模块进行一个回顾。文中所有代码信息已做脱密处理。
技术选型
后台数据库:Mysql+MongoDB
前台后端:springboot–Filter
定时任务:@Scheduled
这里应注意的是,系统分为前台(用户访问端)和后台(集团管理维护端)
MongoDB
MySQL自然不用多说,这里说一下为什么要使用MongoDB;
1、前期选择使用Mysql存储,后面发现访问量增加,数据条目增加,单条数据涵盖信息上升,占用空间增大使得访问Mysql数据速度变慢;
2、访问日志数据属于半结构化数据,以文本的形式记录,适合MongoDB
基本结构
主要由:文档(document)集合(collection)数据库(database)组成
document:相当于数据库的中的一行记录
collection: 由多个document组成,相当于数据库中的表
database:由多个collection组成,逻辑上的组织在一起,就是数据库。
过滤器Filter
使用意义
WEB开发人员通过Filter技术,对web服务器管理的所有web资源:例如JSP,Servlet,静态图片文件或静态HTML文件进行拦截,从而实现一些特殊功能。例如实现URL级别的权限控制、过滤敏感词汇、压缩响应信息等一些高级功能。
原理-链的形式
我们使用过滤器时,过滤器会对游览器的请求进行过滤,过滤器可以动态的分为3个部分
1.放行之前的代码,2.放行,3.放行后的代码
public interface Filter {
// 执行过滤器的初始化工作
default void init(FilterConfig filterConfig) throws ServletException {
}
// 当请求和响应被过滤器拦截后,都会交给doFilter来处理:其中两个参数分别是被拦截request和response对象,可以使用chain的doFliter方法来放行。
void doFilter(ServletRequest var1, ServletResponse var2, FilterChain var3) throws IOException, ServletException;
// 释放关闭Filter对象打开的资源,在web项目关闭时,由web容器自动调用该方法。
default void destroy() {
}
}
对应上述三个部分,Filter生命周期可分为三个阶段:分别是初始化,拦截和过滤,销毁。
初始化阶段:当服务器启动时,我们的服务器(Tomcat)就会读取配置文件,扫描注解,然后来创建我们的Filter。
拦截和过滤阶段:只要请求资源的路径和拦截的路径相同,那么过滤器就会对请求进行过滤,这个阶段在服务器运行过程中会一直循环。
销毁阶段:当服务器(Tomcat)关闭时,服务器创建的Filter也会随之销毁。
定时任务 Scheduled
Spring 3.0 版本之后自带定时任务,提供了@EnableScheduling注解和@Scheduled注解来实现定时任务功能。
- 关于多线程使用定时器
多线程使用定时器
异步/线程池(ThreadPoolTaskExecutor)
具体实现
定义过滤器
1、要想使用filter,需要写一个方法继承Filter类
2、对于游客用户(未注册)的处理
@Component
@WebFilter(filterName = "MyFilter", urlPatterns = "/*")
public class MyFilter implements Filter {
// 这里的ALLOWED_PATHS 字面上是放行路径,实际上是后文不需要进行访问统计分析的路径
private static final Set<String> ALLOWED_PATHS = Collections.unmodifiableSet(new HashSet<>(
Arrays.asList(
"/js",
"/elementui",
"/images",
"/doc",
"/getImage",
"/chart",
"/video"
)));
private Logger log = LoggerFactory.getLogger(this.getClass());
@Autowired
@Lazy
MongoBasicService mongoBasicService;
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
// do something 处理request 或response
// doFilter()方法中的servletRequest参数的类型是ServletRequest,需要转换为HttpServletRequest类型方便调用某些方法
try {
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
String path = request.getRequestURI().substring(request.getContextPath().length()).replaceAll("[/]+$", "");
boolean allowedPath = false;
for (String prefix : ALLOWED_PATHS) {
if (path.startsWith(prefix + "/") || path.startsWith(prefix)) {
allowedPath = true;
break;
}
}
// 这里的allowedPath实际上是设置了一些不需要进行过滤器处理的资源
if (!allowedPath) {
String ip = request.getRemoteAddr();
String url = request.getRequestURL().toString();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date d = new Date();
String date = sdf.format(d);
// 定义JSON对象-后续存至MongoDB-这里是获取信息的关键
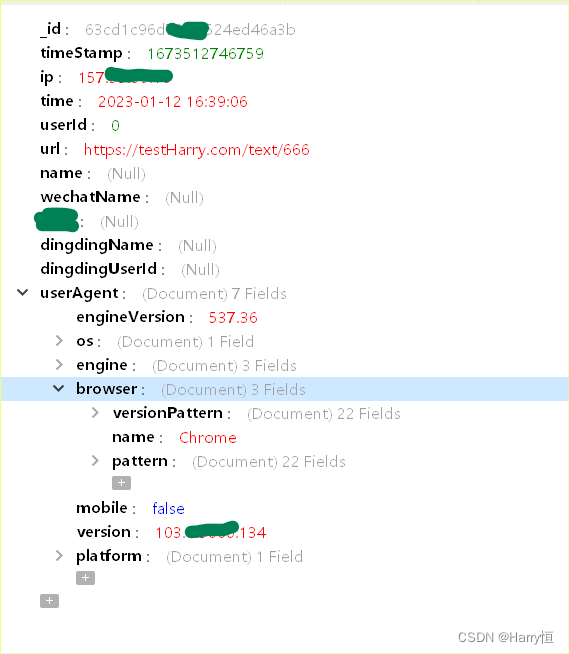
JSONObject j = new JSONObject();
j.put("ip", ip);
j.put("url", url);
j.put("time", date);
j.put("timeStamp", d.getTime());
HttpSession session = request.getSession();
if (session != null) {
//考虑游客情况
if (session.getAttribute("id") != null) {
j.put("userId", session.getAttribute("id"));
} else {
j.put("userId", 0);
}
if (session.getAttribute("name") != null) {
j.put("name", session.getAttribute("name"));
}
if (session.getAttribute("wechatName") != null) {
j.put("wechatName", session.getAttribute("wechatName"));
}
}
j.put("userAgent", UserAgentUtil.parse(request.getHeader("User-Agent")));
}
System.out.println(date + " -- " + j.toString());
log.info("#filter# -- " + j.toString());
// 存放至MongoDB
this.mongoBasicService.insert(j, Constant.COLLECTION_VISIT_LOG);
}
filterChain.doFilter(request, response);
} catch (Exception e) {
e.printStackTrace();
log.warn(e.toString());
}
}
}
定义用户登录控制器
看到上面过滤器中的参数获取时你可能有点懵,session当中的用户属性是从哪来的呢?这其实是我们在用户登录平台时就进行了获取,在这里我们把属性获取放在了userController当中,将获取到的属性存放至session当中。
示例:
//微信id
session.setAttribute("wid", account.getwId());
//首次通过微信登录需要绑定手机号码
session.setAttribute("account", account);
- session和cookie区别
存放至MongoDB
关于mongoDB使用可以参考下一个章节
这里展示的使用mongoTemplate来对MongoDB进行插入操作,这里使用JSON格式存储数据,注意这里使用了异步;
@Async
public void insert(JSONObject j, String collectionName){
try{
this.mongoTemplate.insert(j,collectionName);
}catch(Exception e){
e.printStackTrace();
log.warn(e.toString());
}
}
- 关于JAVA异步操作
至此,前台页面的用户信息获取功能开发完成;下面开始后台分析处理程序的开发
MongoDB
下载安装这些比较简单,建议直接百度
这里需要说明一下如何使用数据库管理工具来连接MongoDB,个人喜欢Navicat
Navicat下载
基本使用
参考文章MongoDB用户密码登录
注意:第一次使用前需要配置环境变量
1、登录使用
mongod --port 66667 --dbpath D:/MonogoDB4/data/db
2、新建指定用户
---> 执行命令
mongo --port 66667
use admindb.createUser(
... {
... user: "user",
... pwd: "user123456",
... roles: [ { role: "userAdminAnyDatabase", db: "admin" } ]
... }
... )
---> 返回打印
Successfully added user: {
"user" : "qiao",
"roles" : [
{
"role" : "userAdminAnyDatabase",
"db" : "admin"
}
]
}
MongoDB基本操作
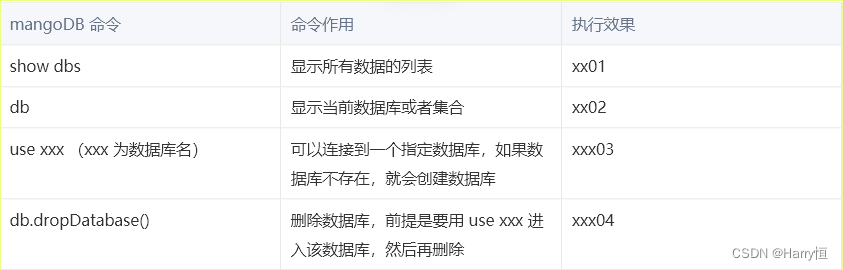
这里注意:如果DB数据库中没有表,在 show dbs时不会出现;
参考文章
从MongoDB获取原始访问记录
在上文我们在前台系统中已经获取到访问数据,并存储到了MongoDB中;在后台我们将针对原始数据进行分析;
这里主要有几个点需要注意:
1、MongoDB条件查询
2、为什么要做limit分页处理,防止一次性读取数据过多造成卡死;
3、如何读取到所有数据:使用do while循环进行判断
do{
//查询mongo数据
Query query = new Query();
// 模糊查询
//如果url使用模糊查询则 创建正则
query.addCriteria(
new Criteria().and("url").regex("/msg/")
);
query.addCriteria(
new Criteria().andOperator(
Criteria.where("time").gt(lastDate)
)
);
query.limit(20000);
visitLogs = mongoTemplate.find(query, VisitLog.class);
} while (visitLogs.size() != 0);
统计逻辑
阅读量统计主要逻辑:
针对MongoDB每一条原始数据进行解析,然后插入/更新Mysql数据表。
如果数据表已有访问记录,对原纪录的count计数进行累加;
如果数据表没有记录,即待处理记录(比如该文章在数据表中尚未记录),那么需要新建一条对应记录,count计数为1;
具体的代码实际上和具体的业务场景有很大关系,这里就不贴出了。
异步处理
这是为了提高处理速度,这一块打算后面有时间再细细研究一下,整理出来
实现异步的两种方式
1、@Async注解来执行异步任务,需要我们手动去开启异步功能,开启的方式就是需要添加@EnableAsync
2、ThreadPoolTaskExecutor手动实现
Async注解详解
https://juejin.cn/post/6858854987280809997
原理:基于AOP + 注解
1、通知的具体实现如下:
● 第一步获取异步任务线程池 AsyncTaskExecutor,用来执行异步任务
● 使用Callable包裹目标方法
● 执行异步异步任务,根据不同的返回值类型做相应的处理
2、通过BeanPostProcessor的后置处理对满足切点的Bean生成代理
线程池使用及配置(这里属于IO密集型)
可以看到默认线程池的队列大小和最大线程数都是Integer的最大值,显然会给系统留下一定的风险隐患
asks :每秒的任务数,假设为500~1000
taskcost:每个任务花费时间,假设为0.1s
responsetime:系统允许容忍的最大响应时间,假设为1s
1、corePoolSize = 每秒需要多少个线程处理?
I/O密集型核心线程数 = CPU核数 / (1-阻塞系数)。阻塞系数在在0到1范围内。一般为0.8~0.9之间;我们这里取的50;
threadcount = tasks/(1/taskcost) = tasks*taskcout = (500 ~ 1000)*0.1 = 50~100 个线程。
corePoolSize设置应该大于50。
2、maxPoolSize 最大线程数在生产环境上我们往往设置成corePoolSize一样,这样可以减少在处理过程中创建线程的开销。
3、queueCapacity = (coreSizePool/taskcost)responsetime
计算可得 queueCapacity = 80/0.11 = 800。意思是队列里的线程可以等待1s,超过了的需要新开线程来执行。不能设置得太大,否则响应时间陡增
executor.setMaxPoolSize(maxPoolSize);
executor.setCorePoolSize(corePoolSize);
executor.setQueueCapacity(queueCapacity);
executor.setKeepAliveSeconds(keepAliveSeconds);
// 线程池对拒绝任务(无线程可用)的处理策略 -如果添加到线程池失败,那么主线程会自己去执行该任务,不会等待线程池中的线程去执行
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
核心线程数计算方式
参考文章
最最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目
a.假如一个程序平均每个线程CPU运行时间为0.5s,而线程等待时间(非CPU运行时间,比如IO)为1.5s,CPU核心数为8,那么最佳的线程数应该是?
根据上面这个公式估算得到最佳的线程数:((0.5+1.5)/0.5)*8=32。
b.假如在一个请求中,计算操作需要5ms,DB操作需要100ms,对于一台8个CPU的服务器,总共耗时100+5=105ms,而其中只有5ms是用于计算操作的,CPU利用率为5/(100+5)。使用线程池是为了尽量提高CPU的利用率,减少对CPU资源的浪费,假设以100%的CPU利用率来说,要达到100%的CPU利用率,又应该设置多少个线程呢?
((5+100)/5)*8=168 个线程。
利用 ThreadPoolTaskExecutor 批量插入数十万条数据
在批处理插入数据时,如果在单线程环境下是非常耗时
spring 容器注入线程池 bean 对象
@Bean(name = "threadPoolTaskExecutor")
public ThreadPoolTaskExecutor threadPoolTaskExecutor()
{
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setMaxPoolSize(maxPoolSize);
executor.setCorePoolSize(corePoolSize);
executor.setQueueCapacity(queueCapacity);
executor.setKeepAliveSeconds(keepAliveSeconds);
// 线程池对拒绝任务(无线程可用)的处理策略
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
return executor;
}
创建异步操作接口
public interface IUserDataService
{
/**
* 异步批量插入用户注册信息
* @param userData 用户信息
* @return
*/
public void asyncinsertUserDataList(UserData userData, CountDownLatch countDownLatch);
}
异步线程业务类
public class UserDataServiceImpl implements IUserDataService
{
/**
* 异步插入用户注册信息
* @param userData 用户信息
* @param countDownLatch
*/
@Override
@Async("threadPoolTaskExecutor")
public void asyncinsertUserDataList(UserData userData, CountDownLatch countDownLatch)
{
try {
log.info("start executeAsync");
userDataMapper.insertUserData(userData);
log.info("end executeAsync");
} catch(Exception e){
e.printStackTrace();
} finally {
// 无论上面程序是否异常必须执行 countDown,否则 await 无法释放
countDownLatch.countDown();
}
}
}
定时任务
前置-为什么要定时处理
将要处理的数据积攒成“批”,在指定时间一次性进行处理,被称为:批处理,也叫:跑批。
拓展:
1.跑批业务的特点:处理量大(成批),有特定的触发时机(指定时间点),可自动处理(无需人工干预)
2、针对银行,不是所有的数据都是实时操作,特别是针对那些大批量的业务,集中发工资、集中开卡等, 因此跑批就是为此诞生。
常见定时任务实现方式
参考文章
1、Java自带timer
2、ScheduledExecutorService
3、Java Task(本文使用,也就是定时去处理访问数据)
代码实现
创建定时任务类,来管理需要定时任务的业务 @Scheduled
import org.springframework.scheduling.annotation.Async;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
/**
* 基于注解设定多线程定时任务
* @author pan_junbiao
*/
@Component
@EnableScheduling // 1.开启定时任务
@EnableAsync // 2.开启多线程
public class MultithreadScheduleTask
{
@Async
@Scheduled(fixedDelay = 1000) //间隔1秒
public void first() throws InterruptedException {
// TODO 这里可以写需要定时处理的任务,如日志读取、访问数据分析
System.out.println("第一个定时任务开始 : " + LocalDateTime.now().toLocalTime() + "\r\n线程 : " + Thread.currentThread().getName());
System.out.println();
Thread.sleep(1000 * 5);
}
@Async
@Scheduled(fixedDelay = 2000)
public void second() {
// TODO 这里可以写需要定时处理的任务,如日志读取、访问数据分析
System.out.println("第二个定时任务开始 : " + LocalDateTime.now().toLocalTime() + "\r\n线程 : " + Thread.currentThread().getName());
System.out.println();
}
}
以上就是利用springboot+MongoDB阅读量统计的全过程,整个过程略显粗暴,小白请各位大佬多多指教。未经许可,不得转载。















 7111
7111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









