






nanodet是一个实时目标检测模型,模型小且轻量化,专门设计用于在计算资源有限的硬件设备上。这个模型通常被优化,以在资源受限的环境中快速而准确地检测图像或视频帧中的对象。
一、环境搭建
系统:服务器
编程语言:python=3.8
开发环境:Anaconda3
深度学习框架:pytorch1.9.0+cu11.6
开发代码IDE:vscode
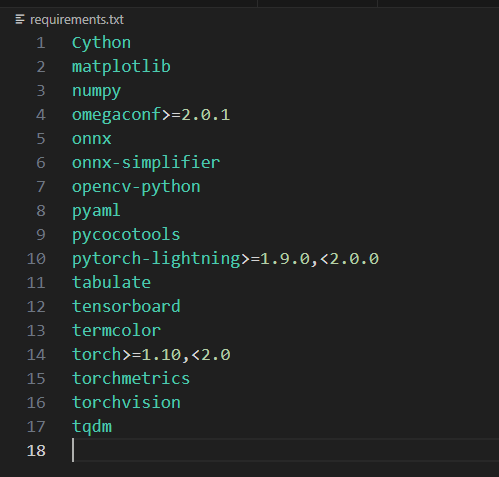
在搭建环境时首先要查看nanodet文件夹下的requirement.txt文件,根据要求选择python、cuda、pytorch和pytorch-lightning对应版本
二、nanodet模型下载
1、源码官方下载地址:https://github.com/RangiLyu/nanodet
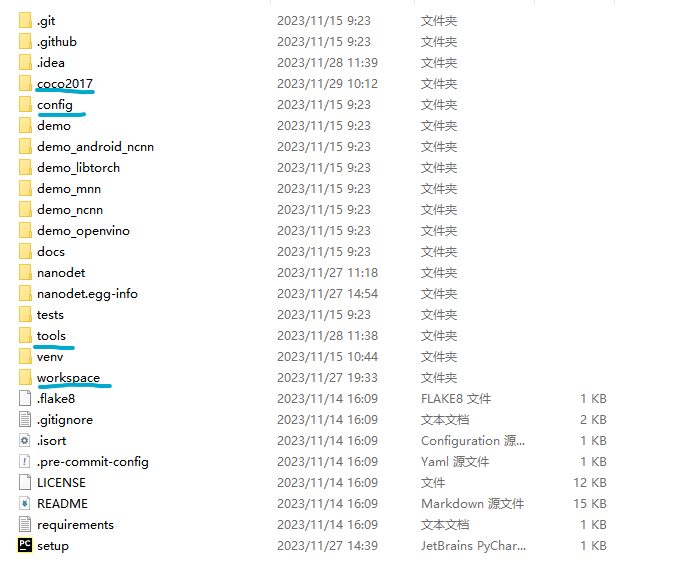
2、在nanodet目录下创建文件夹
(1)coco2017:存放数据集、验证集、测试集和json标注文件
(2)workspace:存放训练好后的模型权重文件
(3)config:存放训练和测试用的配置文件
(4)tools:存放训练用的主文件
二、COCO数据集
COCO数据集是一个常用的数据集,包括目标检测、分割等。COCO数据集包括训练集、验证集和测试集,超过33万张图像,标注过的图像超过20万张,150万个对象实例,80个目标类别,91个材料类别,每张图片有5段情景描述,对25万人进行了关键点标注。
1、数据集下载地址:http://cocodataset.org/
2、将下载的数据集放置coco2017文件夹中
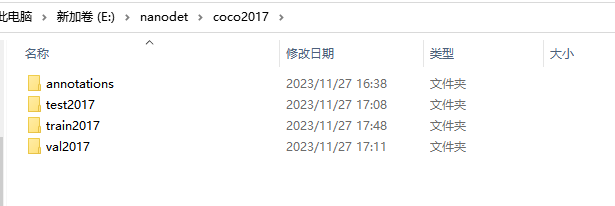 annotations:对应标注文件夹,json文件
annotations:对应标注文件夹,json文件
test2017:测试图像文件夹
train2017:训练图像文件夹
val:验证图像文件夹
三、安装nanodet
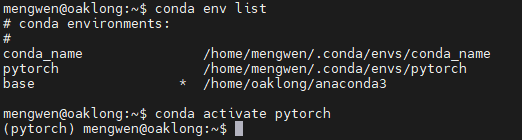
1、创建虚拟环境并进入
这里创建了一个名为pytorch的虚拟环境,后续安装库文件、执行操作都基于这个环境
conda create -n pytorch python=3.8
2、安装setup.py文件
在虚拟环境下,进入到nanodet目录下
cd nanodet
ls
python setup.py develop

出现以下页面表示成功
四、修改配置文件
(1)参考:
深度学习:使用nanodet训练自己制作的数据集并测试模型,通俗易懂,适合小白
五、出现的报错
1、No module named ’torch._six‘
这里是pytorch版本过高,我使用的版本是2.0.0
解决方法:
(1)卸载pytorch2.0.0,安装1.12.0
pip uninstall pytorch #卸载原有版本
pip install torch-1.12.0+cu116-cp38-cp38-linux_x86_64.whl #安装torch低版本
pip install torchvision-0.13.0+cu116-cp38-cp38-linux_x86_64.whl #安装与torch对应的torchvision
pytorch下载地址:https://download.pytorch.org/whl/torch_stable.html
(2)替换代码中调用torch._six的部分(不建议)
详细见:解决No module named ’torch._six‘问题
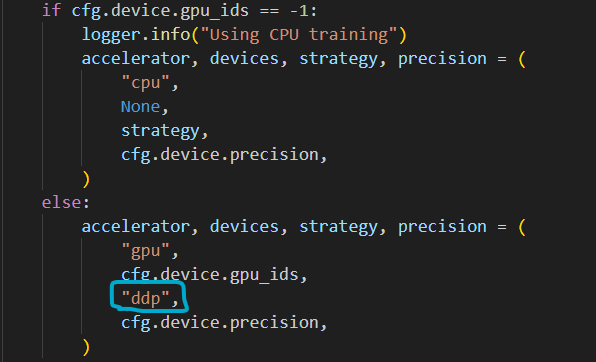
2、ValueError: You selected an invalid strategy name: strategy=None. It must be either a string or an instance of pytorch_lightning.strategies.Strategy. Example choices: auto, ddp, ddp_spawn, deepspe
这里对nanodet\tools\trains.py代码进行更改,将None换成 “ddp”
3、NotImplementedError: Support for training_epoch_end has been removed in v2.0.0. TrainingTask implements this method
这里是pytorch_lightning的版本过高,刚开始使用pip install pytorch_lightning 安装了最新版本
解决方法:安装1.9.0版本
pip uninstall pytorch_lightning
pip install pytorch_lightning==1.9.0
4、RuntimeError: CUDA out of memory. Tried to allocate 50.00 MiB (GPU 0; 4.00 GiB total capacity; 682.90 MiB already allocated; 1.62 GiB free; 768.00 MiB reserved in total by PyTorch)
这种情况是是GPU内存不够
解决方法:在nanodet/config/legacy_v0.x_configs路径下,,将nanodet-m.yml文件中的batchsize_per_gpu的值改小
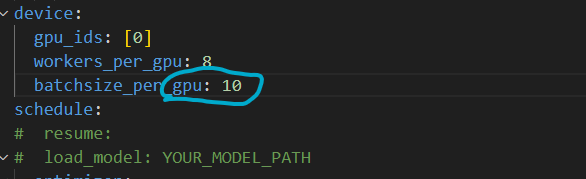
六、训练数据集
(1)虚拟环境下,终端中输入以下命令:
cd nanodet
python tools/train.py ./config/legacy_v0.x_configs/nanodet-m.yml
 训练好的模型权重文件会被存放到根目录下的workspace文件夹中
训练好的模型权重文件会被存放到根目录下的workspace文件夹中
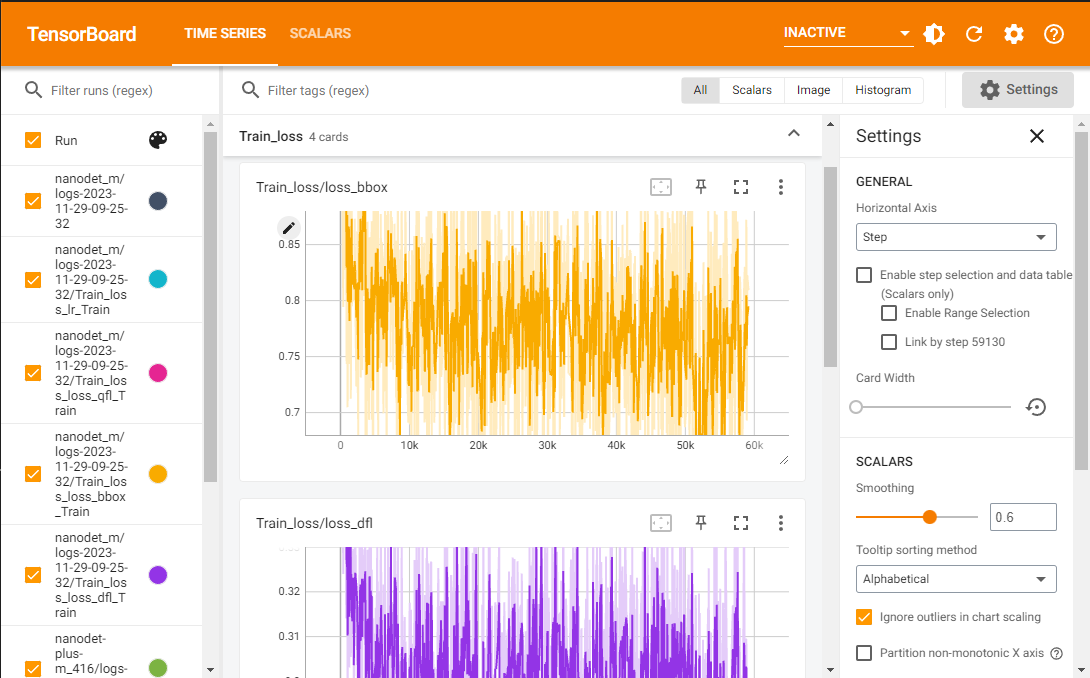
(2)训练结束后对训练过程进行可视化
tensorboard --logdir ./
















 9494
9494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









