







目录
2.2 检索增强的交叉注意力集中机制(Retrieval-augmented Cross-Attention)
2.3 重定义注意力集中机制(Attention Reformulation)
为了应对bert模型输入受限制的问题,发现了这篇论文(https://arxiv.org/pdf/2305.01625v1.pdf),开始研读。
Abstract
本文提出了Unlimiformer,一种用于改进预训练语言模型(如BART)性能的方法。Unlimiformer可以在测试时使用,而无需进一步训练,从而在GovReport和SummScreen数据集上分别提高了1.8和1.4的ROUGE-1分数。此外,通过在验证时使用Unlimiformer进行早期停止,可以在训练成本相同的情况下进一步提高性能。实验结果表明,Unlimiformer在长文档摘要任务上取得了显著的性能提升。
2 Unlimiformer
给定一个训练过的encoder-decoder transformer,在每个解码步骤中Unlimiformer让每一个交叉注意力头(cross-attention head)从全长度的输入(full-length input)中选择单独的键(separate keys)。我们在每个解码器层中注入kNN搜索:在交叉注意力集中机制(cross-attention)之前,模型在kNN索引中执行最近邻搜索,以选择一组每个解码器层每个注意力头的标记进行关注。
2.1 Encoding
为了编码一个比模型的上下文窗口更长的输入序列,我们使用给定的模型的编码器来编码重叠的输入块,遵循Ivgi等人的《使用短文本模型高校理解长文本》。我们只保留每个块中编码向量的中间半半部分,以确保编码在两边都有足够的上下文。最后,我们使用Faiss(Johson索引,2019)等库对kNN索引中的编码输入进行索引(python中有库可以直接调用,是一种调用GPU的快速搜索算法),使用点积作为索引的最近邻相似度度量。
这里有必要对于《使用短文本模型高校理解长文本》做一定的介绍,简单概括来说就是这一张图的内容。
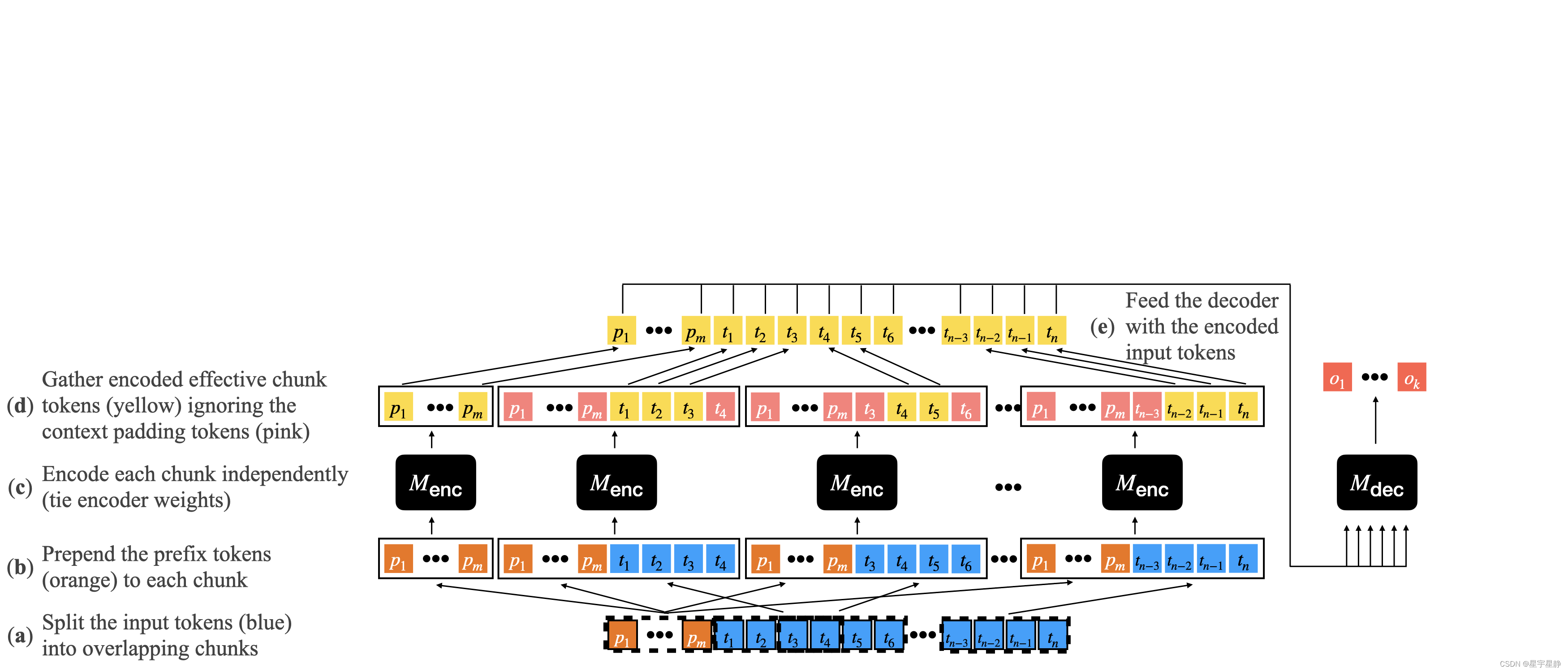
- 文档tokens被拆分成长度为c的C个块(图中为c=4,蓝色),每个块的中间(1-p)x c个快成为有效块,因为他们将构成encoder的输出,并且没测通过token进行上下文填充。有小块的左右各加(p x c)/2个token,用于把有效块中的每个tokens放在上下文环境中。
- 每个块前面都有可选的前缀token(橙色);
- 使用M编码器对每个块独立编码;
- 从每个块中只保留有效块中的token(黄色);
- 使用M编码器对前缀token进行编码,是的解码器能够访问前缀token;
- 最后使用M解码器生成输出,该解码器对m+n个编码的tokens使用标准交叉注意力。
2.2 检索增强的交叉注意力集中机制(Retrieval-augmented Cross-Attention)
在标准的交叉注意中,transformer 的译码器(decoder)关注编码器(encoder)的顶层隐藏状态,其中编码器通常截断输入,并只编码输入序列中的k个第一个词(token)。
我们不是只关注输入的k个标记(词)前缀,而是从每个交叉注意头的kNN索引中检索顶部k个隐藏状态,并且只关注这些顶部k个隐藏状态。这允许从整个输入序列中检索,而不是截断。在计算和gpu内存方面,我们的方法也比关注所有输入tokens更划算;由于softmax由最大值主导,检索关注最多的tokens保留了绝大部分的注意力量。
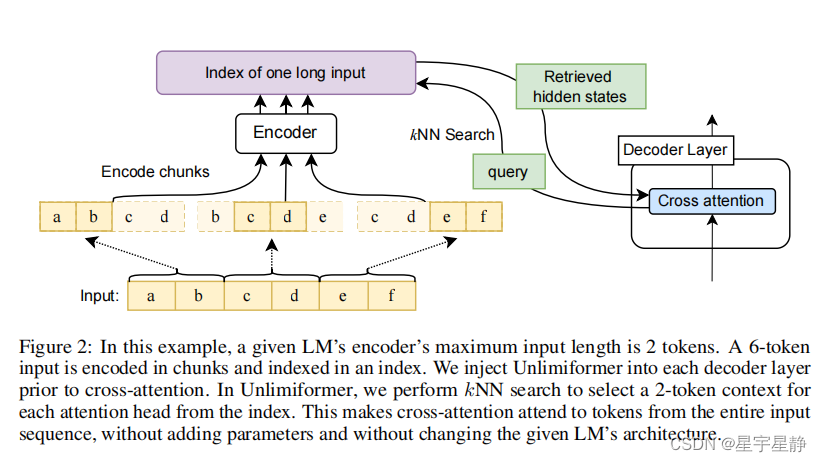
图2说明了我们对任何序列到序列(sequence-to-sequence)transformer的体系结构的通用更改。完整的输入使用编码器进行块编码,并在kNN索引中进行索引;然后,在每个解码步骤中查询所编码的隐藏状态的索引。kNN搜索步骤是非参数的,可以注入任何预训练的seq2seq(序列导序列)transformer。搜索步骤重新定义了对空间效率的关注,如下所述。
2.3 重定义注意力集中机制(Attention Reformulation)
设是解码器的隐藏状态,他是编码器的最后一层隐藏状态。变压器中单个磁头的标准交叉注意计算为:
其中是解码器状态
和查询权矩阵
的乘积;键
是最后一个编码器隐藏状态
与键权矩阵
的乘积;
也是
与值权矩阵
的乘积。我们的目标是检索一组最大化
的键
,
的大小固定为模型上下文窗口的大小,然后只计算
的标准注意力。
此外,我们提出了一个不同的顺序来计算众所周知的transformer注意公式,它允许我们在所有注意力头和所有解码器层上存储一个单一的索引,而不改变transformer的标准点积注意的数学定义。transformer注意力计算的点积部分可以改写如下:
使用我们的重新公式,索引只为每个输入标记存储一个向量。使用16位浮点数和大小为1024的隐藏状态,这只需要存储1,000,000个输入tokens。由于索引可以卸载到CPU内存,无限器的输入长度实际上是无限的
















 1420
1420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











