






正则表达式
匹配次数
- *:匹配前一个字符任意次
- .*:匹配前面任意字符任意次
- ?:匹配前一个字符0次或1次
- +:匹配前面的字符至少一次
- {n}:匹配前一个字符n次
- {m,n}匹配前一个字符至少m次,至多n次
- {,n} 匹配前一个字符至多n次
- {n,}匹配前一个字符至少n次
匹配字符
- .:匹配任意单个字符
- [] :匹配指定范围内的任意单个字符
- [^] :取反
- [:alnum:] 或 [0-9,a-z,A-Z]:匹配数字或字符
- [:blank:]: 空白字符
- [:digit:]: 十进制数字
- [:xdigit:]:十六进制数字
- [:print:]: 可打印字符
- [:punct:] :标点符号
贪婪匹配和惰性匹配
贪婪匹配:正则表达式中包含重复的限定符时,通常的行为是匹配尽可能多的字符。
惰性匹配,有时候需要匹配尽可能少的字符。
回溯:当前前面分支/重复匹配成功后,没有多余的文本可被正则后半部分匹配时,会产生回溯
例如:
对1234a做测试
贪婪匹配( /\d+\b/)
- \d+ 匹配得到 1234
- \b 匹配失败
- \d+尝试回吐一个字符,即匹配结果为 123 ,\b还是匹配失败!
- 那就继续回吐,一直到 1,还是匹配失败,那么这个正则就整体匹配失败了
- 这个回吐匹配结果的过程就是回溯
惰性匹配(/d+?\b/)
- \d+? 先匹配得到1 , \b 匹配失败
- \d+? 继续匹配,得到12 ,\b 匹配失败
- \d+? 一直匹配到1234,\b 一直匹配失败
- 整个正则匹配不成功
密码输入测试
要求数字、小写、大写字母以及符号,且位数在7-8位
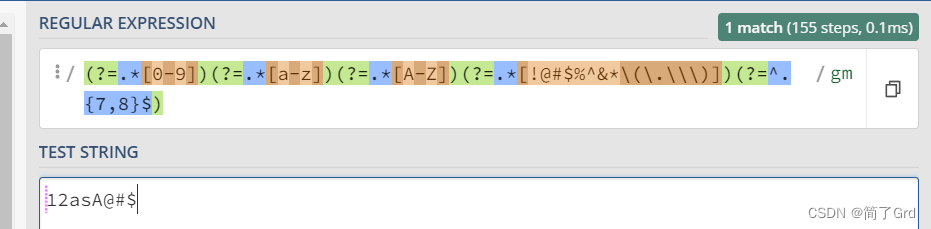
利用正则表达式绕过
打开靶场用order by检测列,确保列相同,保证联合查询

在4时显示unknown,代表没有那么多列,于是可以往后减,从而得知这个表有3列,其中username为2,password为3

于是可以通过用户和密码查找到user,但是由于正则表达式的限制无法继续

无法注入

只有不让正则表达式出现单词边界,改变from的值,才能绕过
mysql支持科学计数法,所以能使用1e1查询
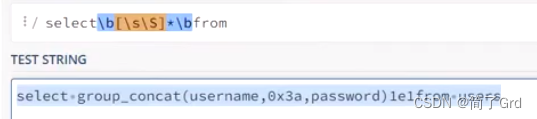
由于使用了1e1,mysql识别并且单独列出来一列,而且“1e1”可以和from连接在一起使用,系统会认为这是两个命令,所以这样既没有报错,同时也绕过了正则,但是也样并没有完全解决。

换一种方式来写,也就是换一种语法将4列换为3列。
添加:
localhost/Less-1/?id=1 'union select 1,group_cocat(username,0x3a,password)from users)–+
完成
















 837
837











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









