






前言
接着前一部分所述,这一节介绍稀疏回归、稀疏表示、鲁棒主成分回归、稀疏传感器布置(Sparse Sensor Placement)等等。
5、稀疏回归
l
1
l_1
l1范数可用于正则化统计回归,既可以惩罚统计异常值,又可以获得尽可能少的简化统计模型。
最小二乘回归是用于数据拟合的最常见的统计模型,但是容易被单个大的异常值破坏,因为与拟合线的距离是平方关系,所以异常值的权重更大。相对应,
l
1
l_1
l1最小解对所有数据给予相同的权重,使其对异常值和破坏的数据更具鲁棒性,此过程被称为最小绝对偏差(LAD),下面的例子显示了最小二乘回归和最小偏差回归的差别:
import numpy as np
import matplotlib.pyplot as plt
import os
from scipy.optimize import minimize
plt.rcParams['figure.figsize'] = [7, 7]
plt.rcParams.update({'font.size': 18})
x = np.sort(4*(np.random.rand(25,1)-0.5),axis=0) # Random data from [-2,2],从小到达排序
b = 0.9*x + 0.1*np.random.randn(len(x),1) # 返回的结果是服从均值为0,方差为1的标准正态分布,而不是局限在0-1之间,也可以为负值
atrue = np.linalg.lstsq(x,b,rcond=None)[0] # 最小二乘 输出包括四部分:回归系数、残差平方和、自变量X的秩、X的奇异值。
atrue = atrue.item(0)#保留斜率k
b[-1] = -5.5 # Introduce outlier#增加异常值
aL2 = np.linalg.lstsq(x,b,rcond=None)[0] # New slope
aL2 = aL2.item(0)
plt.plot(x[:-1],b[:-1],'o',color='b',ms=8,label='Data') # Data
plt.plot(x[-1],b[-1],'o',color='r',ms=8,label='Outlier') # Outlier ms标记符大小
xgrid = np.arange(-2,2,0.01)
plt.plot(xgrid,atrue*xgrid,'--',linewidth=3,color='r',label='True Model') # L2 fit (no outlier)
plt.plot(xgrid,aL2*xgrid,'--',linewidth=3,color='c',label='L2 fit') # L2 fit (outlier)
plt.legend()
plt.show()#包含异常值时L1的结果更稳定,L2偏差较大
## L1 optimization to reject outlier
def L1_norm(a):
return np.linalg.norm(a*x-b,ord=1)
a0 = aL2
res = minimize(L1_norm, a0)
aL1 = res.x[0] # aL1 is robust
plt.plot(x[:-1],b[:-1],'o',color='b',ms=8,label='Data') # Data
plt.plot(x[-1],b[-1],'o',color='r',ms=8,label='Outlier') # Outlier
xgrid = np.arange(-2,2,0.01)
plt.plot(xgrid,atrue*xgrid,'--',linewidth=3,color='r',label='True Model') # L2 fit (no outlier)
plt.plot(xgrid,aL2*xgrid,'--',linewidth=3,color='c',label='L2 fit') # L2 fit (outlier)
plt.plot(xgrid,aL1*xgrid,'--',linewidth=3,color='k',label='L1 fit') # L1 fit (outlier)
plt.legend()
plt.show()#包含异常值时L1的结果更稳定,L2偏差较大
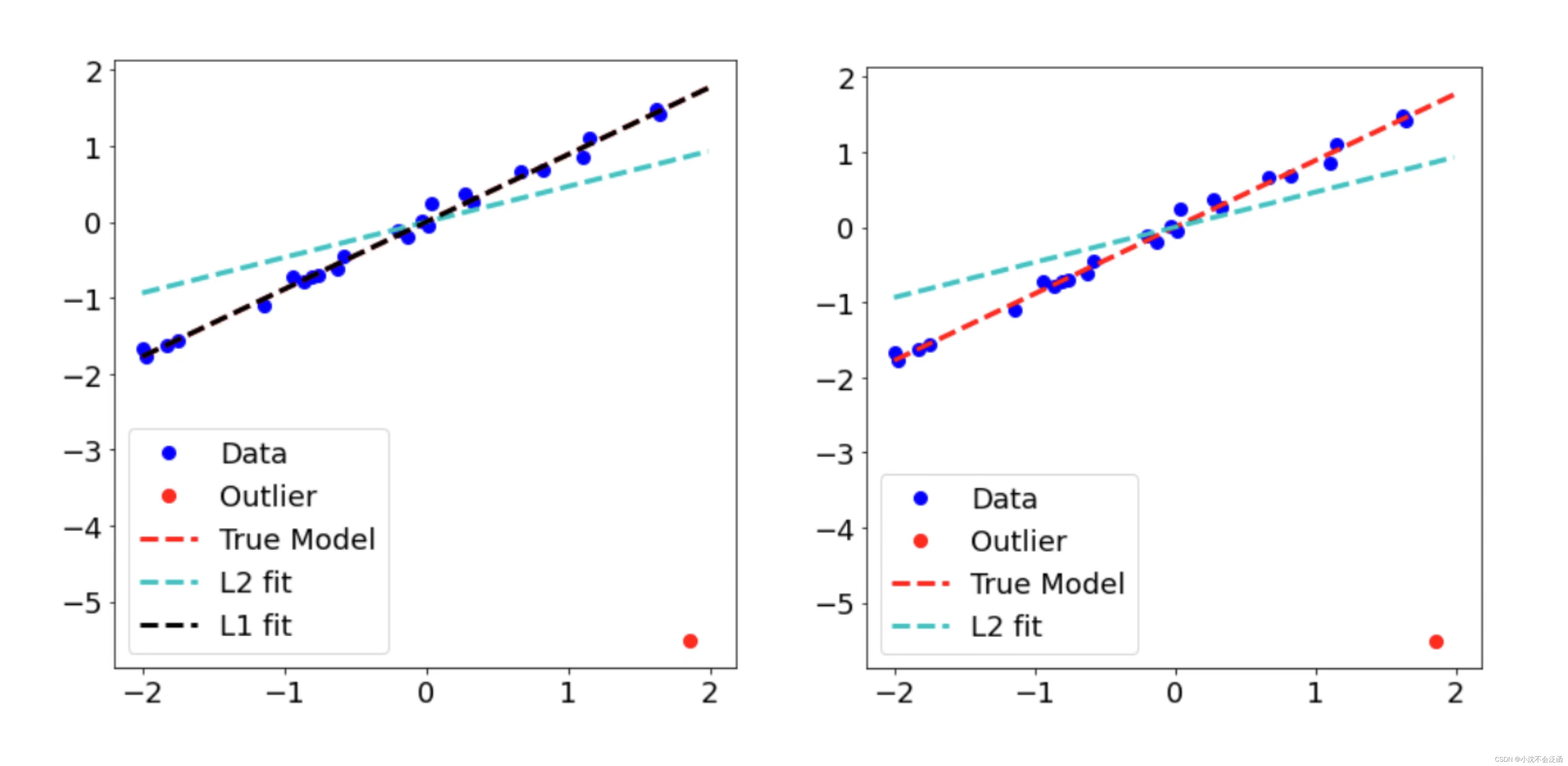
结果如上图,可见
l
1
l_1
l1最小范数解确实对异常值有很大的鲁棒性,在有无异常值的两种情况下几乎无差别。
下面介绍特征选择和LASSO回归,可解释性在统计模型中是很重要的,最小绝对收缩和选择算子(LASSO)是一种
l
1
l_1
l1惩罚回归技术,可在模型复杂性和描述能力之间取得平衡。
给定一个观测系统的若干预测值和输出值,按行排列成矩阵
A
A
A和向量
b
b
b,通过回归分析寻求
A
A
A的列和
b
b
b之间的相容关系,可以写成
A
x
=
b
Ax=b
Ax=b,最小二乘回归往往导致向量
x
x
x的所有项的系数都不为0,这意味着必须用
A
A
A的所有列来预测
b
b
b,但是我们通常认为统计模型应该更简单,即
x
x
x是稀疏的。LASSO回归的损失函数为:
x
=
argmin
x
′
∥
A
x
′
−
b
∥
2
+
λ
∥
x
∥
1
\mathbf{x}=\underset{{x}'}{\operatorname*{argmin}}\|{A}{x}'-{b}\|_2+\lambda\|{x}\|_1
x=x′argmin∥Ax′−b∥2+λ∥x∥1加入惩罚项的目的是防止过拟合,岭回归中的惩罚项是将上式中的
∣
x
∥
1
|{x}\|_1
∣x∥1换成
∣
x
∥
2
|{x}\|_2
∣x∥2,而弹性网络的惩罚项是
λ
1
∥
x
∥
1
+
λ
2
∥
x
∥
2
\lambda_1\|{x}\|_1+\lambda_2\|{x}\|_2
λ1∥x∥1+λ2∥x∥2。
LASSO回归中的
λ
\lambda
λ在一系列值中变化,并且拟合在保留数据的测试集上。如果没有足够多的数据来提供充分多大的训练集和测试集,通常会在随机选择的情况下重复训练和测试模型,从而得到交叉验证的性能,此外LASSO回归可以很好的解决超定问题。
举一个简单的例子,
b
b
b是100个输出观测值组成的列向量,
b
b
b中的每个输出值由10个候选预测因子中的两个组合来给出,这些预测观测值按行排列成矩阵
A
∈
R
100
×
10
A\in R^{100\times10}
A∈R100×10,向量
x
x
x构造成稀疏的,并且向
b
b
b中添加了噪声,通过构造训练集和测试集、交叉验证和网格搜索将均方误差(MSE)绘制为
λ
\lambda
λ的函数:
import numpy as np
import matplotlib.pyplot as plt
import os
import scipy.io
from sklearn import linear_model
from sklearn import model_selection
plt.rcParams['figure.figsize'] = [7, 7]
plt.rcParams.update({'font.size': 18})
A = np.random.randn(100,10) # Matrix of possible predictors
x = np.array([0, 0, 1, 0, 0, 0, -1, 0, 0, 0]) #Two nonzero predictors
b = A @ x + 2*np.random.randn(100)
xL2 = np.linalg.pinv(A) @ b#最小二乘回归系数
reg = linear_model.LassoCV(cv=10).fit(A, b)#交叉验证次数,训练的x,y,LassoCV(eps=0.0001,n_alphas=300,cv=5).fit(xtrain,ytrain)
lasso = linear_model.Lasso(random_state=0, max_iter=10000)
alphas = np.logspace(-4, -0.5, 30)#产生等比数列,第一项是10的-4次方
tuned_parameters = [{'alpha': alphas}]#参数取值范围
clf = model_selection.GridSearchCV(lasso, tuned_parameters, cv=10, refit=False)#网格搜索
clf.fit(A, b)
scores = clf.cv_results_['mean_test_score']#均方误差
scores_std = clf.cv_results_['std_test_score']
plt.semilogx(alphas, scores,'r-')
# 绘制显示 +/- 标准误差的误差线
std_error = scores_std / np.sqrt(10)
plt.semilogx(alphas, scores + std_error, 'k--')
plt.semilogx(alphas, scores - std_error, 'k--')
plt.fill_between(alphas, scores + std_error, scores - std_error, alpha=0.1,color='k')#填充两条曲线之间, alpha=0.1表示透明度从0到1
plt.ylabel('CV score +/- std error')
plt.xlabel('alpha')
plt.axhline(np.max(scores), linestyle='--', color='.5')
plt.xlim([alphas[-1], alphas[0]])
plt.show()
alphas = np.logspace(-4, -0.5, 30)#产生等比数列,第一项是10的-4次方
XL1 = linear_model.Lasso(alpha=clf.best_params_['alpha'])
XL1.fit(A,b)
xL1 = XL1.coef_
xL1DeBiased = np.linalg.pinv(A[:,np.abs(xL1)>0]) @ b
xL1DeBiased
做出的图像应该是左侧的,但是运行此代码后却差强人意:
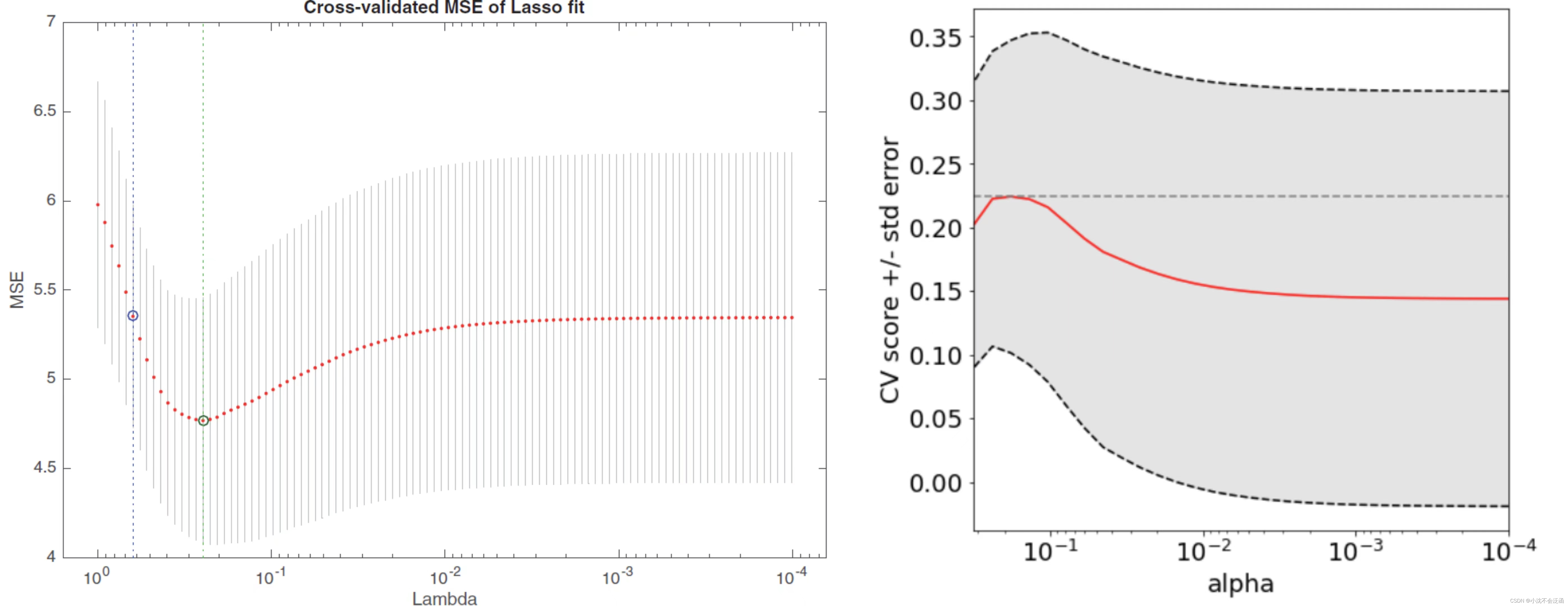
对于代码的修改感觉也无从下手,说白了不知道错误出在什么地方,对于正确的结果(对应重构的
x
x
x)所得的
x
L
1
xL1
xL1应该是稀疏的并且非零项的位置和大小应该很接近,但是这些项的回归值并不准确,有必要应用最小二乘回归对非零系数进行辨识,以此对LASSO回归去偏。(加粗的部分说实话我并没有理解缘由以及操作的原理)
6、稀疏表示
当高维信号表现出低维结构时,在适当的基或字典中,会出现稀疏表示,前几部分都是在傅里叶基上为例,这里在完备的字典上讨论,以特征脸为例,字典中的列由训练数据本身组成,使用人脸图像库构建超完备库
Θ
\Theta
Θ,数据库中每一个人都使用30张图像,共有20个人,
Θ
\Theta
Θ有600列,为了使用压缩感知,需要保证
Θ
\Theta
Θ是欠定的,将每个图像的像素从192×168降采样到12×10,从而使每个图像变成120个成分的向量,当然这种降采样对分类的精度有影响,对于20个人中的某一个或几个人的图像(即为
c
c
c类)降采样形成新的的测试图像,根据
y
=
Θ
s
y=\Theta s
y=Θs使用压缩感知算法,所得向量
s
s
s应该是稀疏的,理想情况下,在与
c
c
c类对应的库中,该向量具有较大的系数(
s
s
s为600行的列向量,在某连续的30行系数较大)。算法的分类阶段利用向量
s
s
s中的每一类的系数(每30行)来计算
l
2
l_2
l2重构误差。大致的示意图如下:
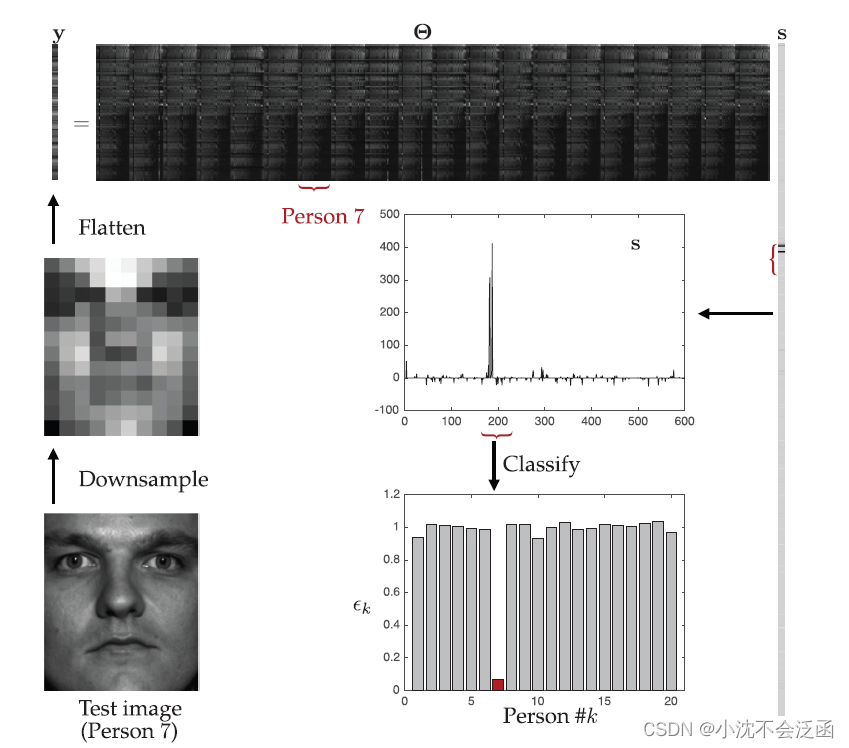
import numpy as np
import matplotlib.pyplot as plt
import os
import scipy.io
from sklearn import linear_model
from sklearn import model_selection
from scipy.optimize import minimize
from skimage.transform import resize
from matplotlib.image import imread
plt.rcParams['figure.figsize'] = [7, 7]
plt.rcParams.update({'font.size': 18})
mustache = imread(os.path.join('..','DATA','mustache.jpg'))
mustache = np.mean(mustache, -1); # 转化为灰度图像
mustache = (mustache/255).astype(int)#转化为整数类型
mustache = mustache.T#转置
mat = scipy.io.loadmat(os.path.join('..','DATA','allFaces.mat'))
X = mat['faces']#mat创建矩阵
nfaces = mat['nfaces'].reshape(-1)#转换成行向量
n = mat['n']##
n = int(n)
m = mat['m']
m = int(m)
#print(X.shape)=(32256, 2410),m=168,n=192
## 构建训练集和测试集
nTrain = 30
nTest = 20
nPeople = 20
Train = np.zeros((X.shape[0],nTrain*nPeople))#X行数×600的元素为0的矩阵
Test = np.zeros((X.shape[0],nTest*nPeople))
for k in range(nPeople):
baseind = 0
if k > 0:
baseind = np.sum(nfaces[:k])
inds = range(baseind,baseind+nfaces[k])
Train[:,k*nTrain:(k+1)*nTrain] = X[:,inds[:nTrain]]
Test[:,k*nTest:(k+1)*nTest] = X[:,inds[nTrain:(nTrain+nTest)]]
## 降采样训练(建立完备 Theta库)
M = Train.shape[1]#训练集的列数=600
Theta = np.zeros((120,M))
for k in range(M):
temp = np.reshape(np.copy(Train[:,k]),(m,n))
tempSmall = resize(temp, (10, 12), anti_aliasing=True)
Theta[:,k] = np.reshape(tempSmall,(1,120))
## 标准化Theta列
normTheta = np.zeros(M)
for k in range(M):
normTheta[k] = np.linalg.norm(Theta[:,k])
Theta[:,k] = Theta[:,k]/normTheta[k]
## 构建4个测试图像 (Test[:,125] = test image 6, person 7)
x1 = np.copy(Test[:,125]) # 干净的测试图像
x2 = np.copy(Test[:,125]) * mustache.reshape(n*m)#胡须遮挡的
randvec = np.random.permutation(n*m)
first30 = randvec[:int(np.floor(0.3*len(randvec)))]
vals30 = (255*np.random.rand(*first30.shape)).astype(int)
x3 = np.copy(x1)
x3[first30] = vals30 # 30%遮挡像素的图像
x4 = np.copy(x1) + 50*np.random.randn(*x1.shape) # 图像添加噪声
## 下采样测试图像
X = np.zeros((x1.shape[0],4))
X[:,0] = x1
X[:,1] = x2
X[:,2] = x3
X[:,3] = x4
Y = np.zeros((120,4))
for k in range(4):
temp = np.reshape(np.copy(X[:,k]),(m,n))
tempSmall = resize(temp, (10, 12), anti_aliasing=True)
Y[:,k] = np.reshape(tempSmall,(1,120))
## L1 Search, 干净图像
y1 = np.copy(Y[:,0])
eps = 0.01
# L1 Minimum norm solution s_L1
def L1_norm(x):
return np.linalg.norm(x,ord=1)
constr = ({'type': 'ineq', 'fun': lambda x: eps - np.linalg.norm(Theta @ x - y1,2)})#不等条件,默认大于等于0 ,误差小于0.01
x0 = np.linalg.pinv(Theta) @ y1 # initialize with L2 solution
res = minimize(L1_norm, x0, method='SLSQP',constraints=constr)
s1 = res.x
plt.figure()
plt.plot(s1)#稀疏向量s
plt.figure()
plt.imshow(np.reshape(Train @ (s1/normTheta),(m,n)).T,cmap='gray')
plt.figure()
plt.imshow(np.reshape(x1 - Train @ (s1/normTheta),(m,n)).T,cmap='gray')
binErr = np.zeros(nPeople)
for k in range(nPeople):
L = range(k*nTrain,(k+1)*nTrain)
binErr[k] = np.linalg.norm(x1-Train[:,L] @ (s1[L]/normTheta[L]))/np.linalg.norm(x1)#x1-第k个人对应的s的系数*训练集中第k个人的图像信息,
#重构的的越接近测试图像则对应这类的误差最小
plt.figure()
plt.bar(range(nPeople),binErr)
plt.show()
算法的分类阶段选用了干净的图像、假胡须遮挡、30%像素遮挡、添加白噪声四个图像测试,从最后的的分类结果上看效果还是不错的。
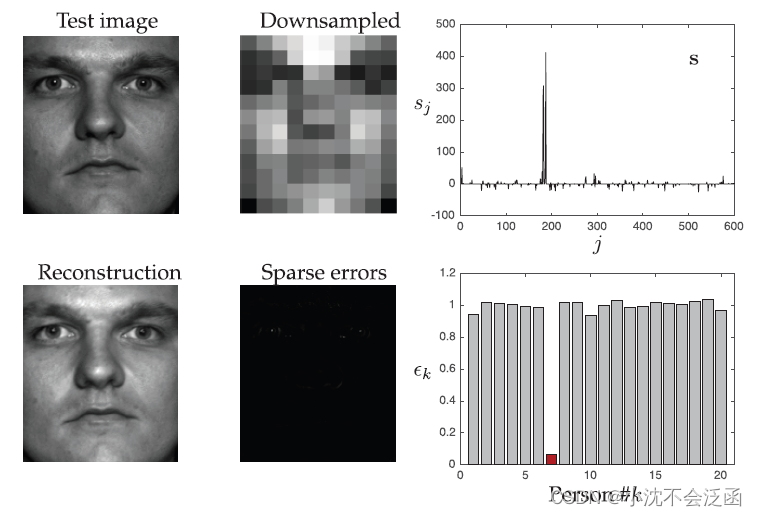
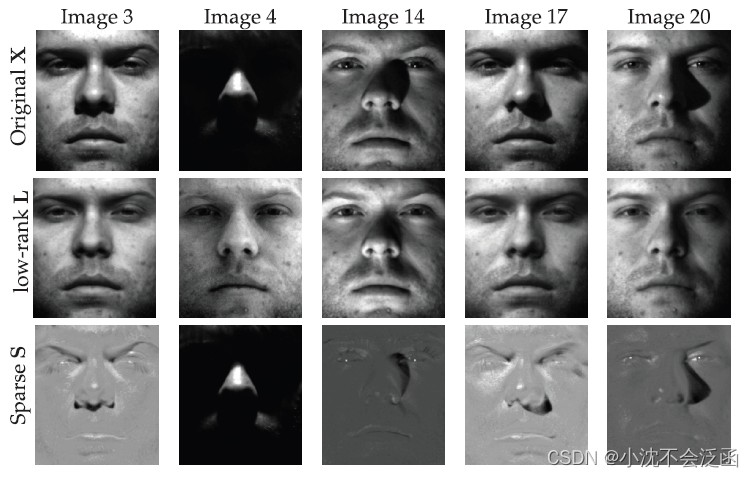
七、鲁棒主成分分析
前文所述最小二乘回归模型极易受到异常纸盒缺失数据的的影响,主成分分析也有同样的缺点,使其在异常值方面非常脆弱,为了改善这种敏感性,产生了鲁棒主成分分析(RPCA)方法,将数据矩阵
X
X
X分解为结构化的低秩矩阵
L
L
L和包含异常值和被污染数据的稀疏矩阵
S
S
S:
X
=
L
+
S
X=L+S
X=L+S
L
L
L的主成分对
S
S
S中的异常值和被污染数据具有鲁棒性。
从数学上讲,RPCA的目标是找到满足以下条件的
L
L
L和
S
S
S:
min
L
,
S
r
a
n
k
(
L
)
+
∥
S
∥
0
s
u
b
j
e
c
t
t
o
L
+
S
=
X
.
\min_{\mathrm{L,S}}\mathrm{rank}({L})+\|{S}\|_0\mathrm{subject~to}{L}+{S}={X}.
L,Sminrank(L)+∥S∥0subject toL+S=X.然而矩阵的秩和0范数都不是凸的(凸指的是凸函数,矩阵的秩可以考虑2×2的特例,0范数上一篇提到),这不是一个容易处理的优化问题,与压缩感知问题类似,可以使用松弛关系将上式转化为:
min
L
,
S
∥
L
∥
∗
+
λ
∥
S
∥
1
s
u
b
j
e
c
t
t
o
L
+
S
=
X
.
\min_{\mathrm{L,S}}\mathrm\|\mathbf{L}\|_*+\lambda\|{S}\|_1\mathrm{subject~to}{L}+{S}={X}.
L,Smin∥L∥∗+λ∥S∥1subject toL+S=X.其中
∥
L
∥
∗
\|\mathbf{L}\|_*
∥L∥∗表示核范数,由奇异值的和给出,它也代表秩的大小。
如果
λ
=
1
/
max
(
n
,
m
)
\lambda=1/\sqrt{\max(n,m)}
λ=1/max(n,m),其中
n
n
n和
m
m
m是
X
X
X的维度,假定
L
L
L和
S
S
S满足以下条件:
1、
L
L
L不是稀疏的;
2、
S
S
S不是低秩的,假设各元素是随机分布的,没有低维的列空间。
则松弛后的解可以在高概率下收敛到非凸的问题的解。
具体算法如下:构造增广拉格朗日算子
L
(
L
,
S
,
Y
)
=
∥
L
∥
∗
+
λ
∥
S
∥
1
+
⟨
Y
,
X
−
L
−
S
⟩
+
μ
2
∥
X
−
L
−
S
∥
F
2
.
\mathcal{L}({L}, {S}, {Y})=\|{L}\|_{*}+\lambda\|{S}\|_{1}+\langle{Y},{X}-{L}-{S}\rangle+\frac{\mu}{2}\|{X}-{L}-{S}\|_{F}^{2} .
L(L,S,Y)=∥L∥∗+λ∥S∥1+⟨Y,X−L−S⟩+2μ∥X−L−S∥F2.求解使
L
\mathcal{L}
L最小的
L
k
L_k
Lk和
S
k
S_k
Sk,更新拉格朗日乘子
Y
k
+
1
=
Y
k
+
μ
(
X
−
L
k
−
S
k
)
\mathbf{Y}_{k+1}=\mathbf{Y}_k+\mu\left(\mathbf{X}-\mathbf{L}_k-\mathbf{S}_k\right)
Yk+1=Yk+μ(X−Lk−Sk)然后一直迭代至收敛,在具体实现过程中需要构造收缩算子和奇异值阈值算子,在特征脸示例对此进行演示:
import numpy as np
import matplotlib.pyplot as plt
import os
import scipy.io
plt.rcParams['figure.figsize'] = [7, 7]
plt.rcParams.update({'font.size': 18})
mat = scipy.io.loadmat(os.path.join('..','DATA','allFaces.mat'))
faces = mat['faces']
nfaces = mat['nfaces'].reshape(-1)
## 定义收缩算子,奇异值阈值算子,RPCA
def shrink(X,tau):
Y = np.abs(X)-tau
return np.sign(X) * np.maximum(Y,np.zeros_like(Y))
def SVT(X,tau):
U,S,VT = np.linalg.svd(X,full_matrices=0)
out = U @ np.diag(shrink(S,tau)) @ VT
return out
def RPCA(X):
n1,n2 = X.shape
mu = n1*n2/(4*np.sum(np.abs(X.reshape(-1))))
lambd = 1/np.sqrt(np.maximum(n1,n2))
thresh = 10**(-7) * np.linalg.norm(X)
S = np.zeros_like(X)
Y = np.zeros_like(X)
L = np.zeros_like(X)
count = 0
while (np.linalg.norm(X-L-S) > thresh) and (count < 1000):
L = SVT(X-S+(1/mu)*Y,1/mu)
S = shrink(X-L+(1/mu)*Y,lambd/mu)
Y = Y + mu*(X-L-S)
count += 1
return L,S
X = faces[:,:nfaces[0]]
L,S = RPCA(X)
inds = (3,4,14,15,17,18,19,20,21,32,43)
for k in inds:
fig,axs = plt.subplots(2,2)
axs = axs.reshape(-1)
axs[0].imshow(np.reshape(X[:,k-1],(168,192)).T,cmap='gray')
axs[0].set_title('X')
axs[1].imshow(np.reshape(L[:,k-1],(168,192)).T,cmap='gray')
axs[1].set_title('L')
axs[2].imshow(np.reshape(S[:,k-1],(168,192)).T,cmap='gray')
axs[2].set_title('S')
for ax in axs:
ax.axis('off')
在此例中,
X
X
X的原始列及其低阶和稀疏分量如图所示,RPCA有效地填充了与阴影相对应的图像遮挡区域,我们想要的就是低秩分量。
8、稀疏传感器布置
传感器一词第一次听可能有点疑惑,通读本节的内容可知,所谓的传感器就是测量矩阵
C
C
C中的非零位置,如下图所示:

传感器布置就是布置测量矩阵的非零位置,从而使得
C
C
C左乘定制基
Ψ
r
\Psi_r
Ψr后所得的
Θ
\Theta
Θ尽可能的“好”,以保证矩阵乘法或者求逆来求解
a
a
a,说的更为准确或者定量分析就是最小化“条件数”(矩阵最大奇异值与最小奇异值的比值),条件数越大,对噪声信号求逆的性能越差。举例说明最差的情形:当信号
a
a
a处在与最小奇异值相关的奇异向量方向上时,并且添加了与最大奇异值对应向量同一方向上的噪声,可以用下边这个式子表示:
θ
(
a
+
ϵ
a
)
=
σ
m
i
n
a
+
σ
m
a
x
ϵ
a
\theta(\mathbf{a}+\epsilon_\mathbf{a})=\sigma_\mathrm{min}\mathbf{a}+\sigma_\mathrm{max}\epsilon_\mathbf{a}
θ(a+ϵa)=σmina+σmaxϵa此时条件数最大也就是
σ
m
a
x
\sigma_\mathrm{max}
σmax较大,
σ
m
i
n
\sigma_\mathrm{min}
σmin较小,此时的信号
a
a
a被添加了更多的信号,因此信噪比随着条件数的增大而降低。
下面介绍两种重构的传感器布置:第一种是随机布置的传感器,也就是在测量矩阵
C
C
C中随机选取非零的位置,这样听上去显然不太好,事实也得的确如此,矩阵
θ
\theta
θ是奇异的,条件数接近
1
0
16
10^{16}
1016,这显然与我们的初衷相悖,当然也可以增加
C
C
C的行来过采样来改善这种情况。
第二种是由旋转
Q
R
QR
QR分解得到的传感器布置:有很多种方法进行
Q
R
QR
QR分解,最常用的一种就是对矩阵的列向量进行施密特正交化,这里说的旋转也是基于这种方法为基础。首先计算每个列向量的二范数(绝对值平方求和再开方),将二范数最大的列放到第一行,比如说是第
j
1
j_1
j1列,接下来利用这一列对后边的列进行施密特正交化,再次计算所得的列向量的二范数,将最大的排在第二列记为
j
2
j_2
j2,此时无需再次正交化,把剩下的列向量按照二范数大小一次排列,接下来分解的步骤与原来的相同,我们还需要记录列的旋转过程来生成
C
C
C,上边说到第一列变为
j
1
j_1
j1、第二列变为
j
2
j_2
j2,依次类推,第
n
n
n列为
j
n
j_n
jn,
C
C
C中的
C
(
k
,
j
k
)
=
1
C_(k,j_k)=1
C(k,jk)=1。
最后说一下用于分类的传感器:对于图像的分类需要比重构更少的传感器,主要原理由下图所示:
其中
X
A
X_A
XA和
X
B
X_B
XB是两类数据,
Ψ
r
\Psi_r
Ψr定制基,
w
w
w是由线性判别分析得出的一个方向向量,线性判别分析将会在后面的章节中介绍,西瓜书中也有提到,对于稀疏传感器
s
s
s由这个式子给出:
s
=
argmin
s
′
∥
s
′
∥
1
subject to
Ψ
r
T
s
′
=
w
.
\mathbf{s}=\underset{s'}{\operatorname*{argmin}}\|\mathbf{s'}\|_1\quad\text{subject to}\quad\mathbf{\Psi}_r^T\mathbf{s'}=\mathbf{w}.
s=s′argmin∥s′∥1subject toΨrTs′=w.说实话这个
s
s
s的具体意义也没太懂,书中给出了一个猫狗分类的例子:
这里
s
s
s所对应的是右图中红色的点。
















 700
700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











