 Python爬虫实战:基金信息数据爬取与四种图表可视化
Python爬虫实战:基金信息数据爬取与四种图表可视化





 本文介绍如何使用Python爬虫从基金网站抓取数据,将数据保存到表格,并通过matplotlib库创建折线图、饼图、散点图和柱状图进行数据可视化。适合初学者参考学习。
本文介绍如何使用Python爬虫从基金网站抓取数据,将数据保存到表格,并通过matplotlib库创建折线图、饼图、散点图和柱状图进行数据可视化。适合初学者参考学习。
用python爬取基金网信息数据,保存到表格,并做成四种简单可视化。(爬虫之路,永无止境!)
上次 2021-07-07写的用python爬取腾讯招聘网岗位信息保存到表格,并做成简单可视化。
有的人留言问我:
可以作为模板么?
我的回答:
可以,可以拿做模板使用
今天我带大家再来使用一下这个模板
开发环境:
windows10
python3.6
开发工具:
pycharm
库:
matplotlib、numpy、lxml
代码展示:
爬虫代码还是很简单的
1.start_url = ‘http://fund.eastmoney.com/fund.html’
2.使用ua大列表,进行ua的替换
3.获取页面源码,然后解析
4.进行xpath语法提取相应的数据
def __init__(self):
# 起始的请求地址----初始化
self.start_url = 'http://fund.eastmoney.com/fund.html'
def parse_start_url(self):
"""
发送请求,获取响应
:return:
"""
# 请求头
headers = {
# 通过随机模块提供的随机拿取数据方法
'User-Agent': random.choice(USER_AGENT_LIST)
}
# 发送请求,获取响应字节数据
response = session.get(self.start_url, headers=headers).content
"""序列化对象,将字节内容数据,经过转换,变成可进行xpath操作的对象"""
response = etree.HTML(response)
"""调用提取第二份响应数据"""
self.parse_response_data(response)
def parse_response_data(self, response):
"""
解析response响应数据,提取
:return:
"""
# 股票名称
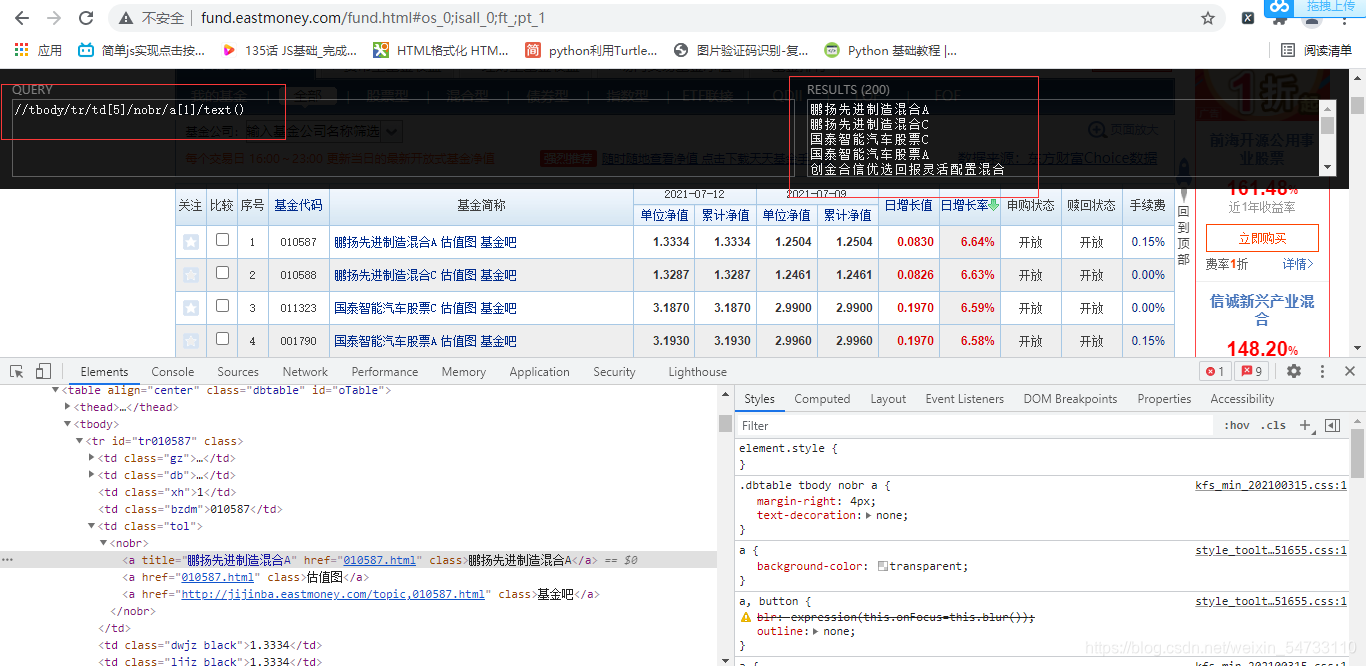
name_list_1 = response.xpath('//tbody/tr/td[5]/nobr/a[1]/text()')
# 昨日单位净值
num_1_list_data_1 = response.xpath('//tbody/tr/td[6]/text()')
# 昨日累计净值
num_2_list_data_1 = response.xpath('//tbody/tr/td[7]/text()')
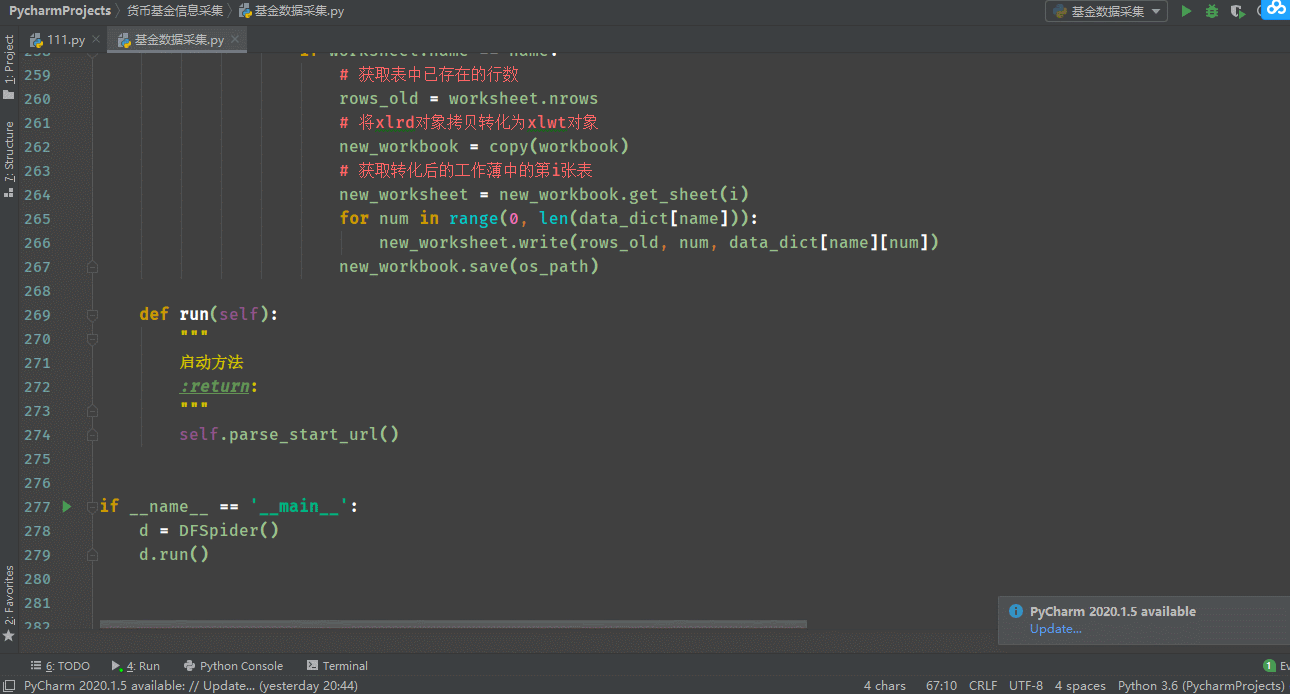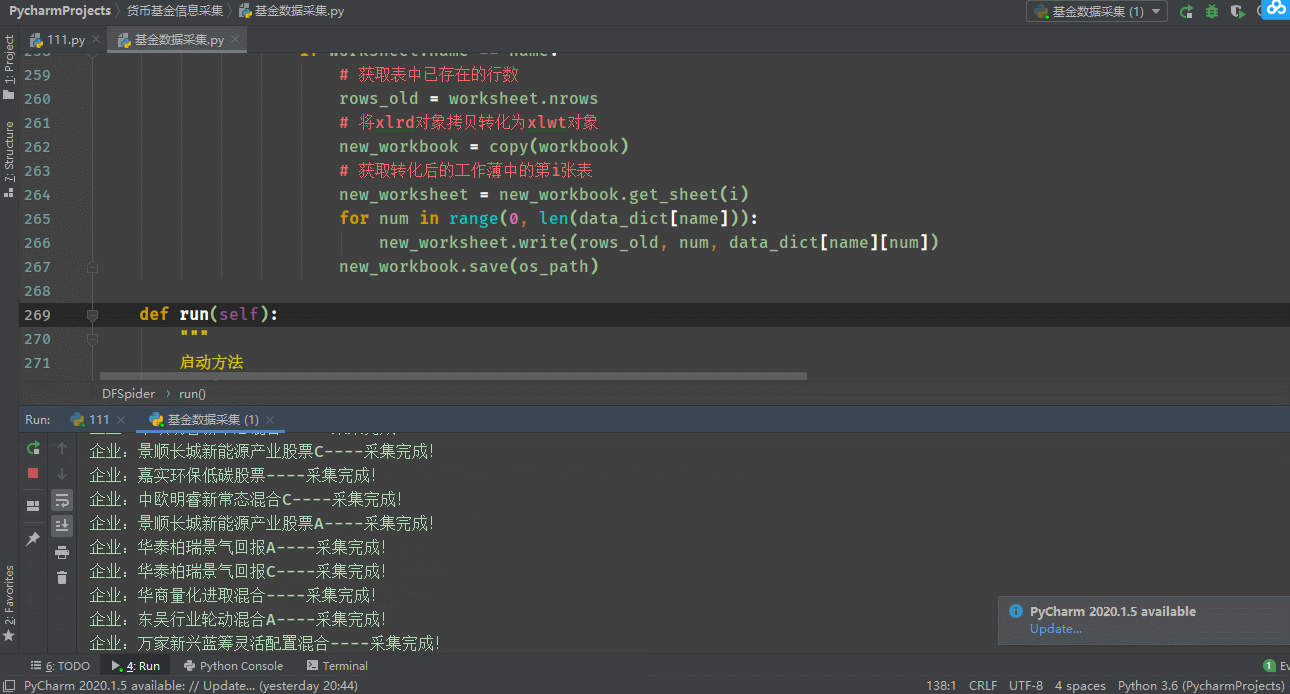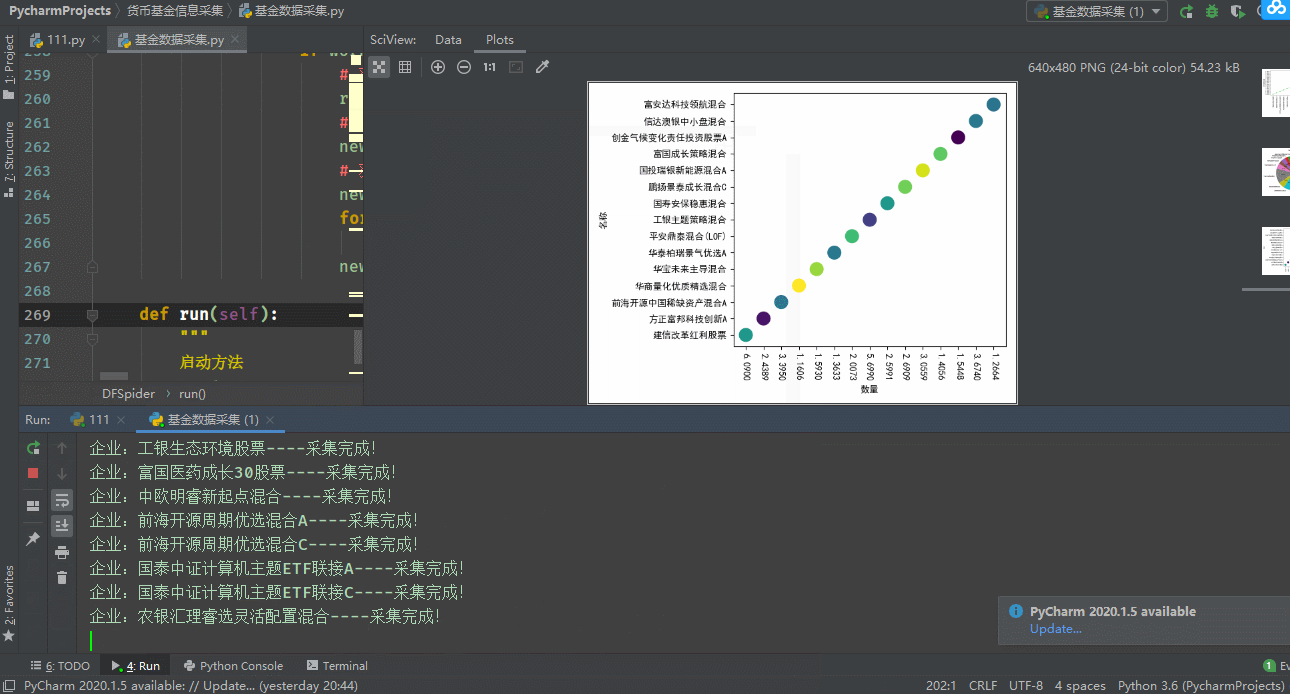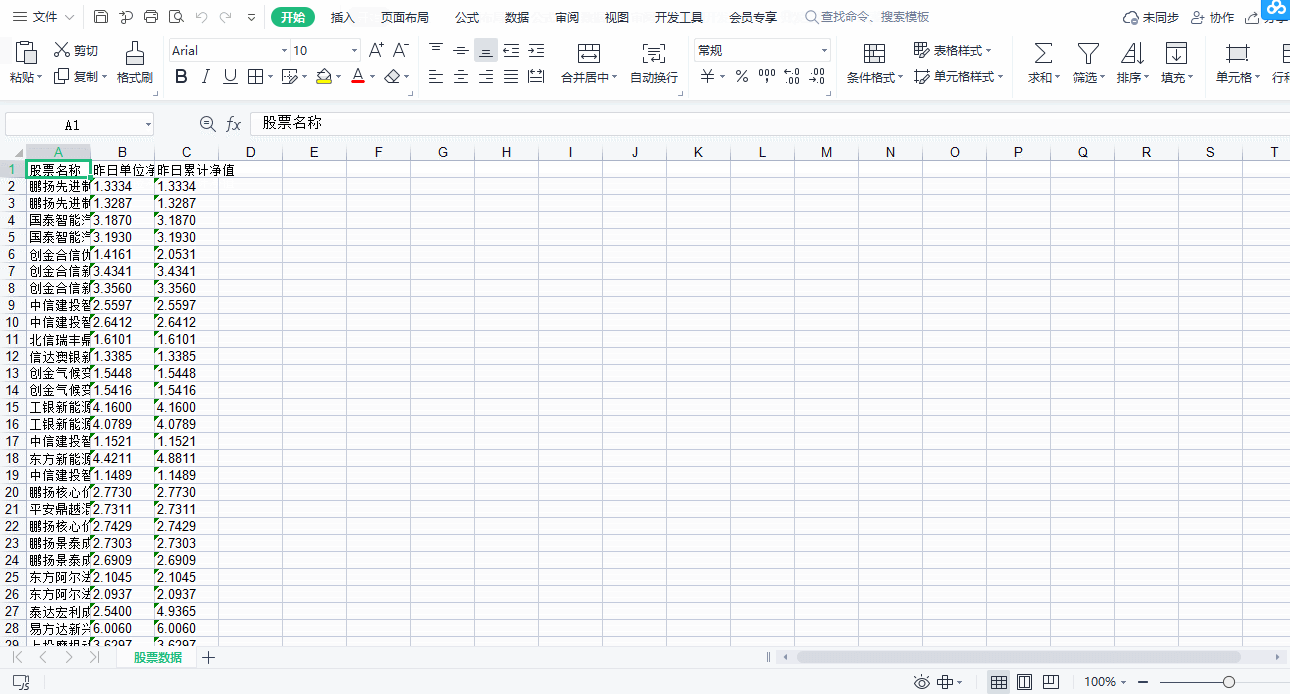
将数据保存到表格,先将数据遍历
# 遍历解析3个列表数据
for a, b, c in zip(name_list, num_1_list, num_2_list):
# 构造保存的excel字典数据
dict_data = {
# 会根据该字典的key值创建工作簿的sheet名
'股票数据': [a, b, c]
}
"""调用解析保存excel表格方法"""
self.parse_save_excel(dict_data)
生成四种简单可视化
先将数据打包一下
def parse_img_four_func(self, index_list, name_list, num_1_list, num_2_list):
"""
解析生成四张分析图
:param index_list: 随机数据的下标
:param name_list: 股票名称列表
:param num_1_list: 昨日单位净值列表
:param num_2_list: 昨日累计净值列表
:return:
"""
title_list = [] # 名称
qy_num_1 = [] # 单位净值
qy_num_2 = [] # 累计净值
for index_num in index_list:
# 企业名称列表
title_list.append(name_list[index_num])
# 昨日单位净值列表
qy_num_1.append(num_1_list[index_num])
# 昨日累计净值列表
qy_num_2.append(num_2_list[index_num])
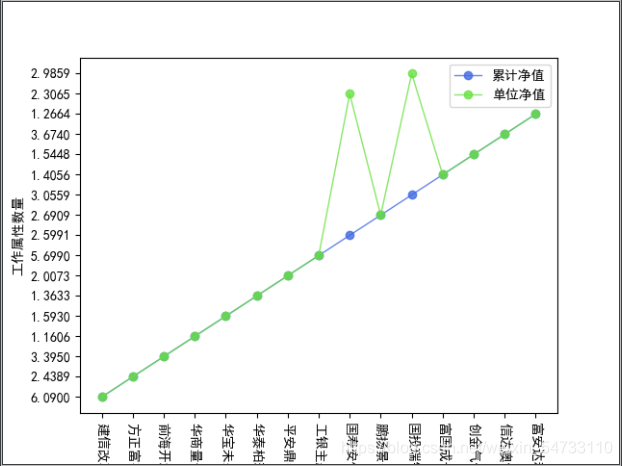
生成折线图
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# plot中参数的含义分别是横轴值,纵轴值,线的形状,颜色,透明度,线的宽度和标签
plt.plot(title_list, qy_num_2, 'ro-', color='#4169E1', alpha=0.8, linewidth=1, label='累计净值')
plt.plot(title_list, qy_num_1, 'ro-', color='#69e141', alpha=0.8, linewidth=1, label='单位净值')
# 显示标签,如果不加这句,即使在plot中加了label='一些数字'的参数,最终还是不会显示标签
plt.legend(loc="upper right")
plt.xticks(rotation=270)
plt.xlabel('地点数量')
plt.ylabel('工作属性数量')
plt.savefig('根据净值生成折线图.png')
plt.show()
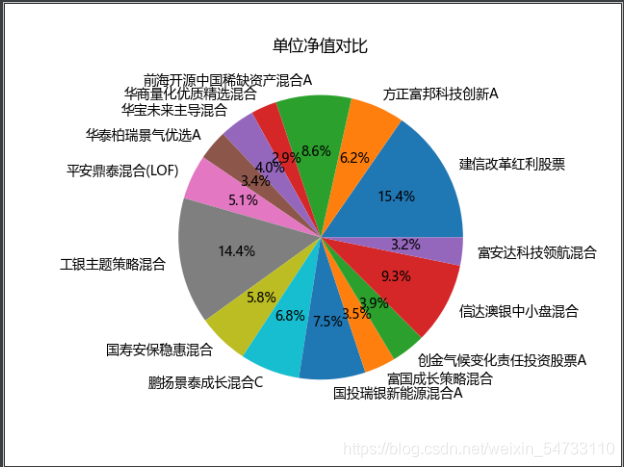
生成饼图
addr_dict_key = title_list
addr_dict_value = qy_num_1
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
plt.pie(addr_dict_value, labels=addr_dict_key, autopct='%1.1f%%')
plt.title(f'单位净值对比')
plt.savefig(f'单位净值对比-饼图')
plt.show()
生成散点图
# 这两行代码解决 plt 中文显示的问题
plt 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
































 到【灌水乐园】发言
到【灌水乐园】发言









