







用python爬取去哪儿游记攻略为十月假期做准备。。。爬虫之路,永无止境!
热热闹闹的开学季又来了,小伙伴们又可以在一起玩耍了,不对是在一起学习了,哈哈。

再过几周就是国庆假期,想想还是很激动的,我决定给大家做个游记爬虫,大家早做准备。。嘿嘿

代码操作展示:
今天目标地址:https://travel.qunar.com/place/
开发环境:
windows10
python3.6
开发工具:
pycharm
库:
tkinter、re、os、lxml、threading、xlwt、xlrd
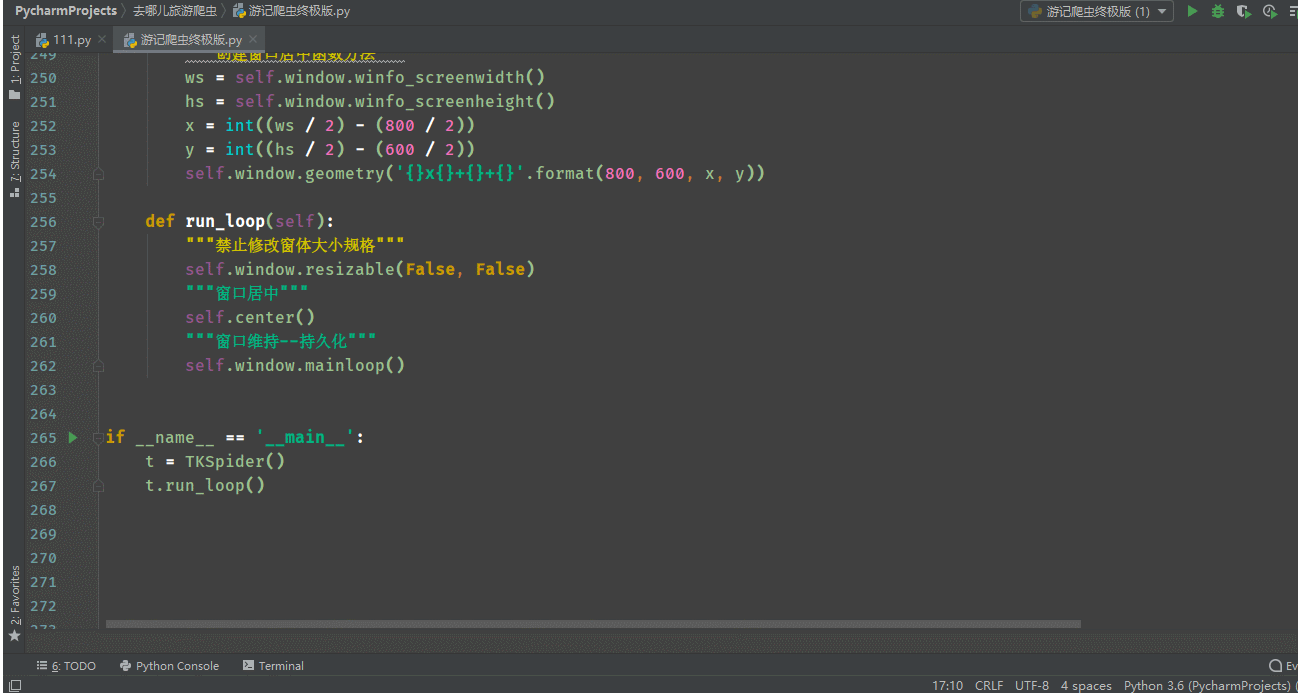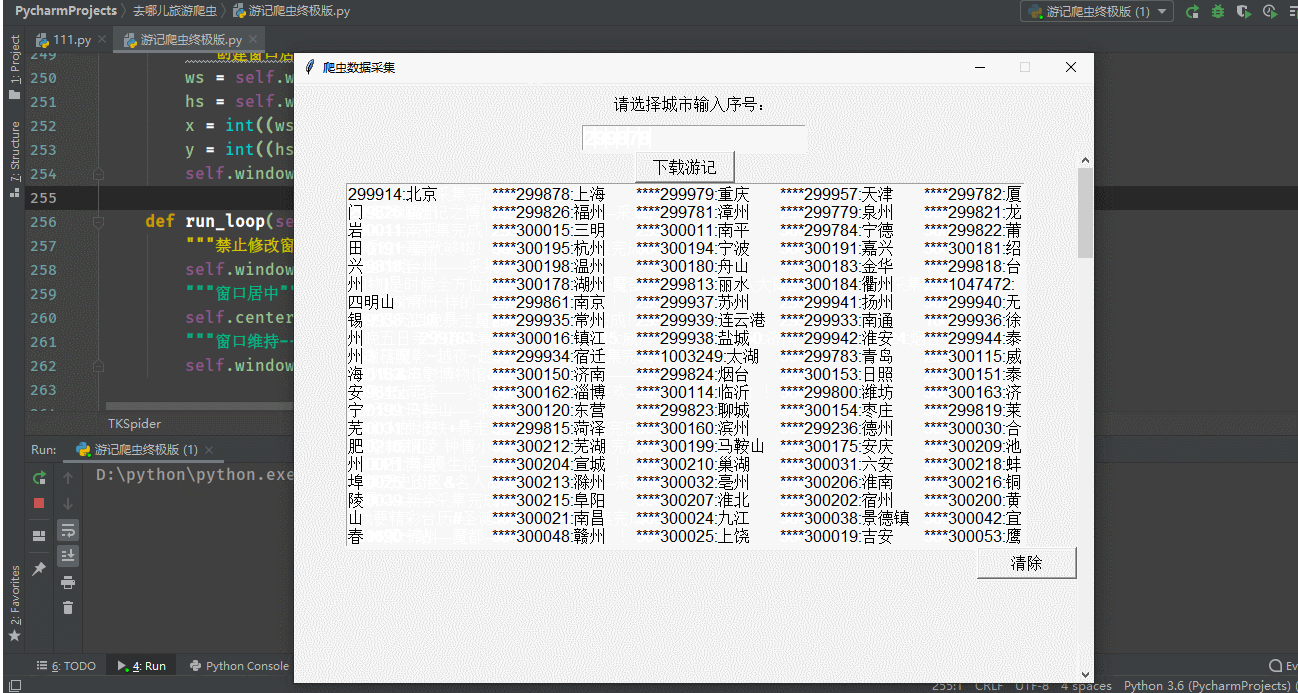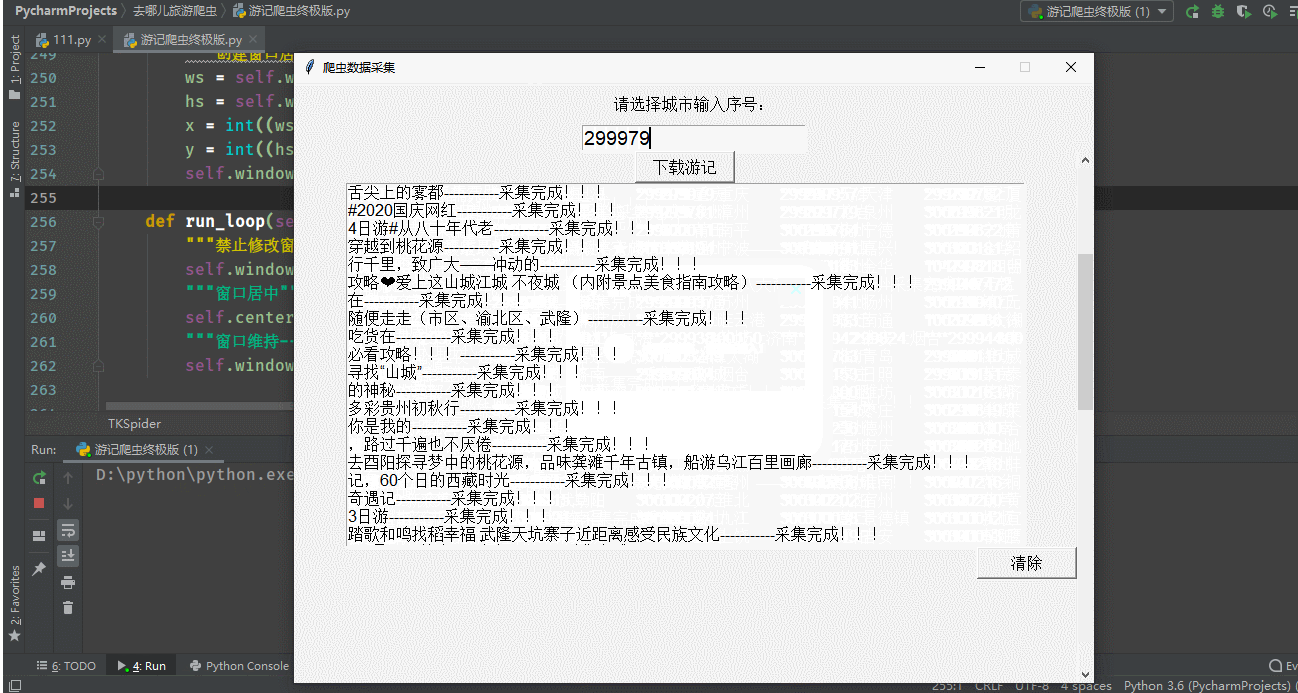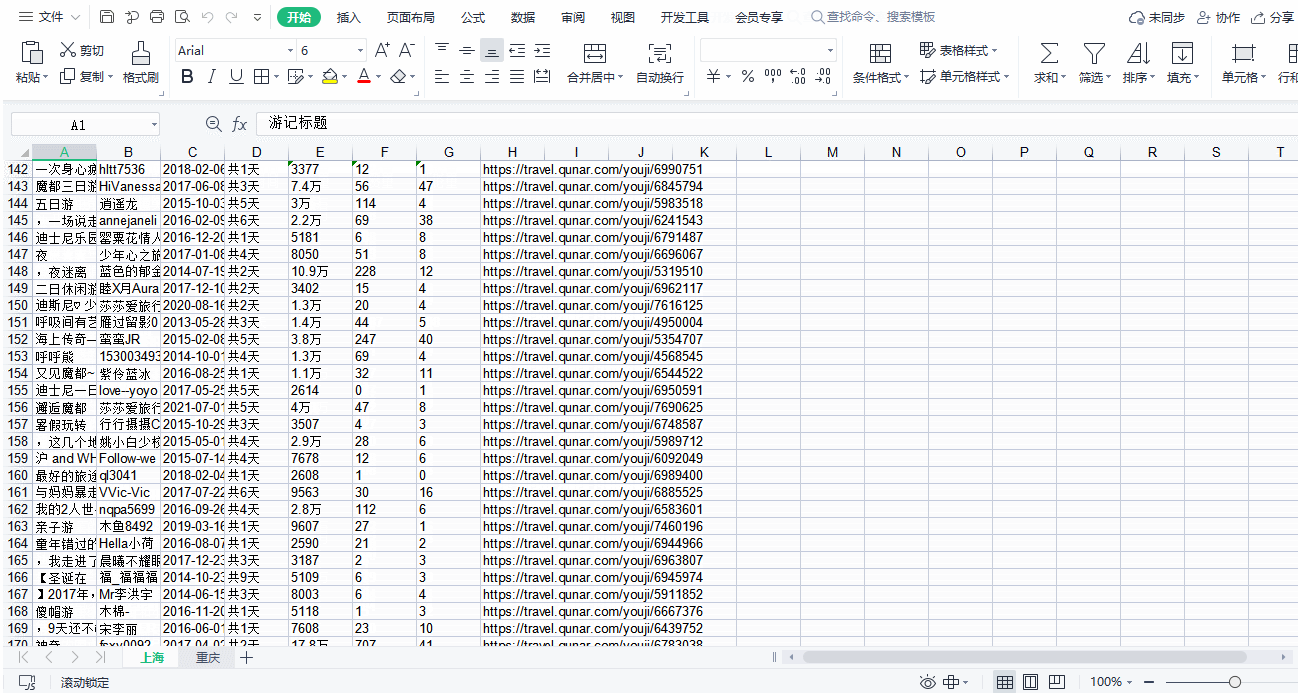
1.首先先将全国所有的城市名称和id拿到
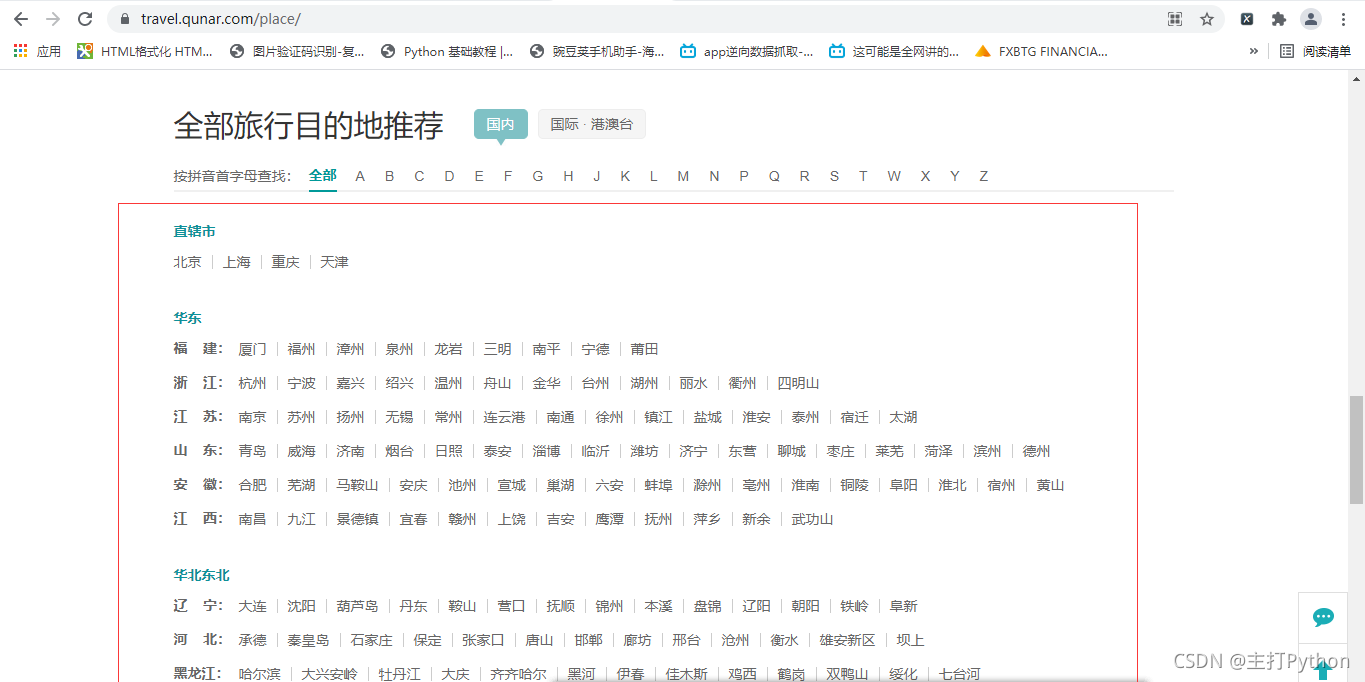
2.右击检查,进行抓包,找到数据所在的包
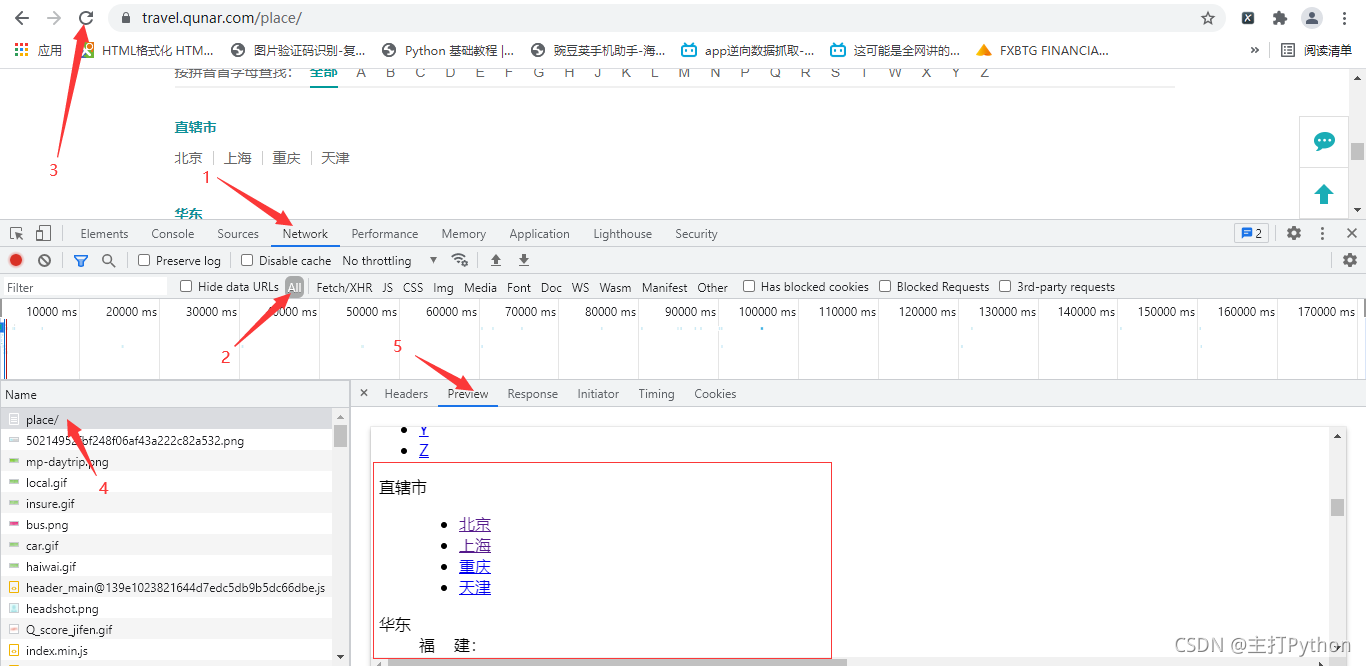
3.发送请求,获取响应,解析响应
# 发送请求,获取响应,解析响应
response = session.get(self.start_url, headers=self.headers).html
# 提取所有目的地(城市)的url
city_url_list = response.xpath(
'//*[@id="js_destination_recommend"]/div[2]/div[1]/div[2]/dl/dd/div/ul/li/a/@href')
city_id_list = [''.join(re.findall(r'-cs(.*?)-', i)) for i in city_url_list]
# 提取所有的城市名称
city_name_list = response.xpath(
'//*[@id="js_destination_recommend"]/div[2]/div[1]/div[2]/dl/dd/div/ul/li/a/text()')
4.随机点一个城市,进入该城市,查看游记攻略,本文选的是上海
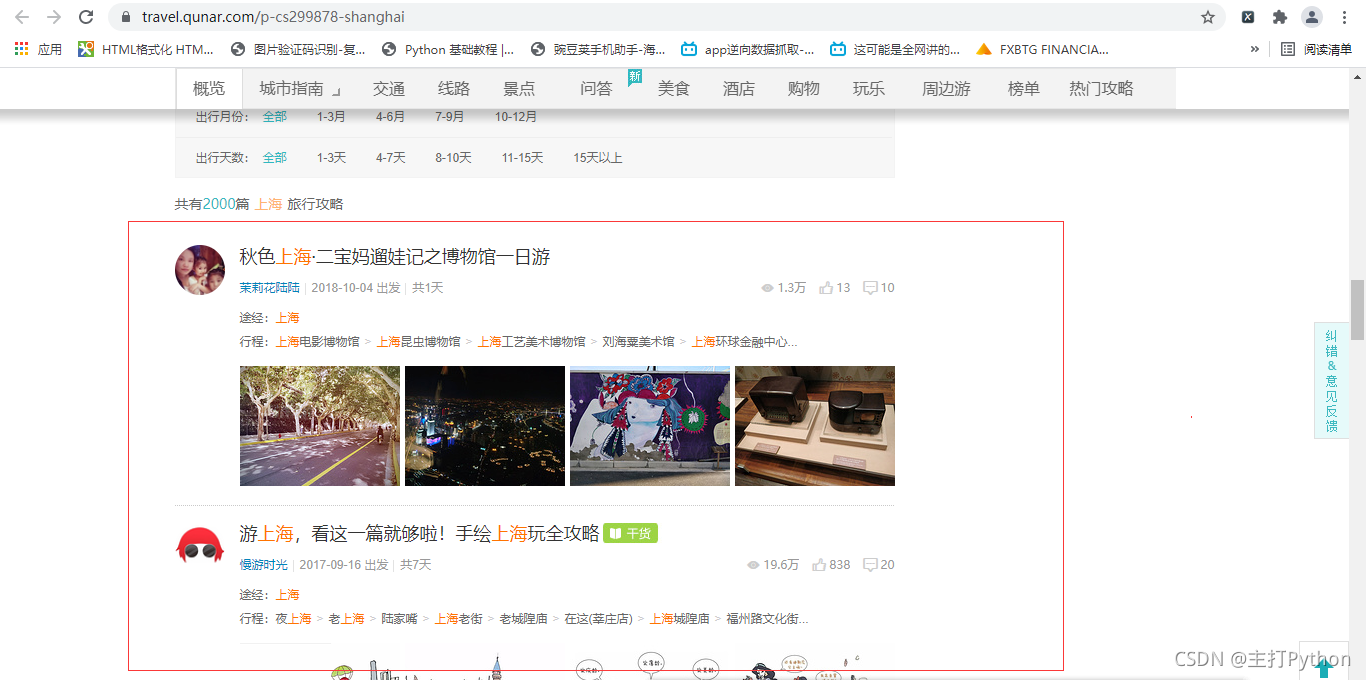
5.进行抓包,查找需要的信息
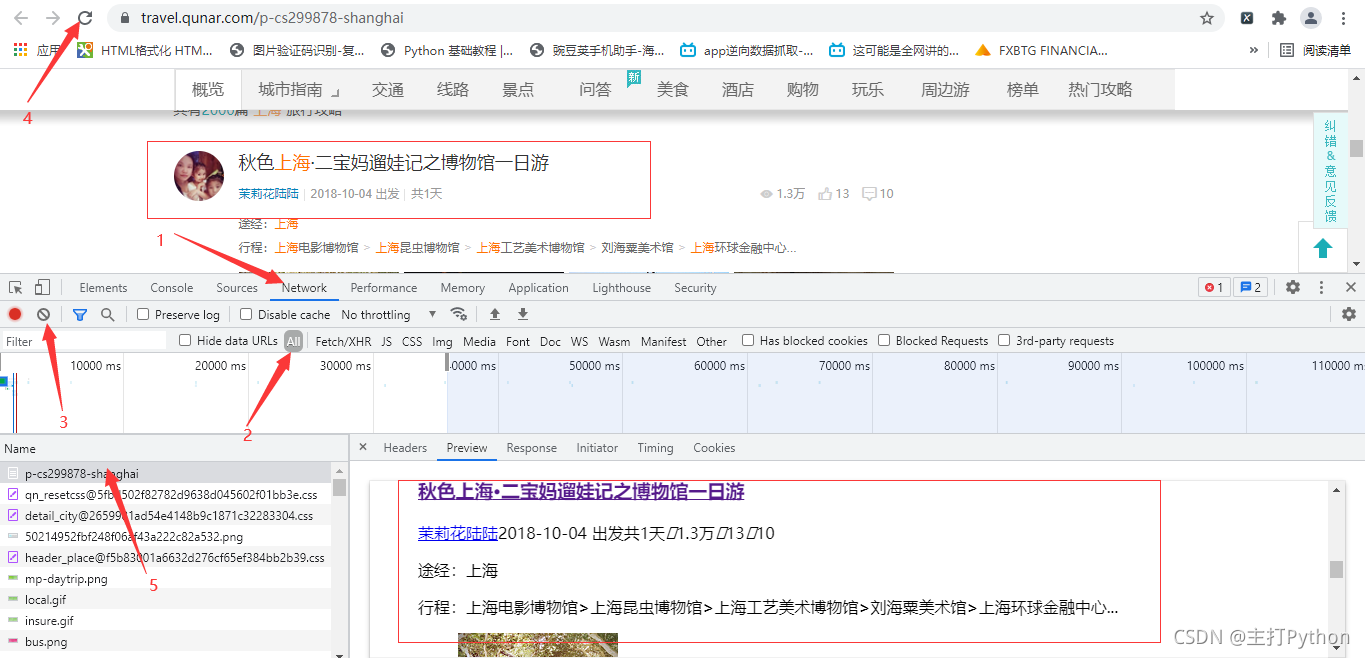
# 提取游记作者
author_list = html.xpath('//span[@class="user_name"]/a/text()')
# 出发时间
date_list = html.xpath('//span[@class="date"]/text()')
# 游玩时间
days_list = html.xpath('//span[@class="days"]/text()')
# 阅读量
read_list = html.xpath('//span[@class="icon_view"]/span/text()')
# 点赞量
like_count_list = html.xpath('//span[@class="icon_love"]/span/text()')
# 评论量
icon_list = html.xpath('//span[@class="icon_comment"]/span/text()')
# 游记地址
text_url_list = html.xpath('//h3[@class="tit"]/a/@href')
6.进行翻页抓包,第二页为异步加载
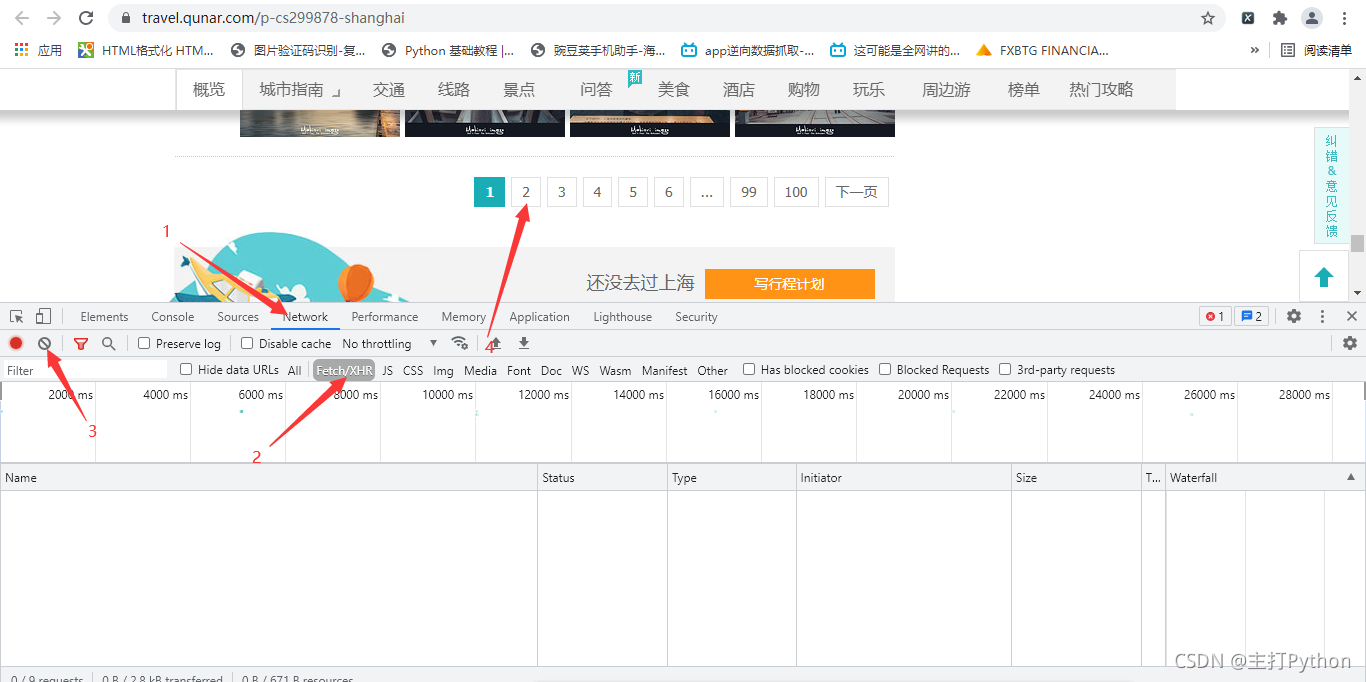
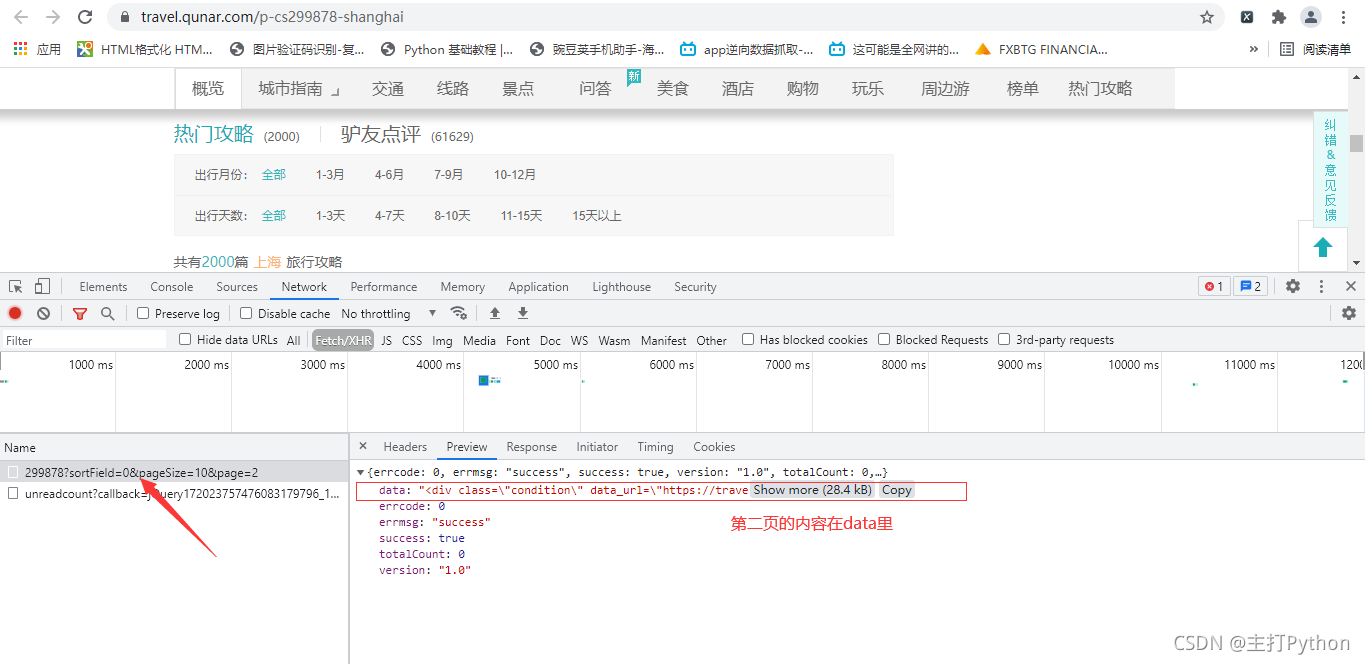
7.在上一张图中点击Headers,获取游记攻略的请求地址
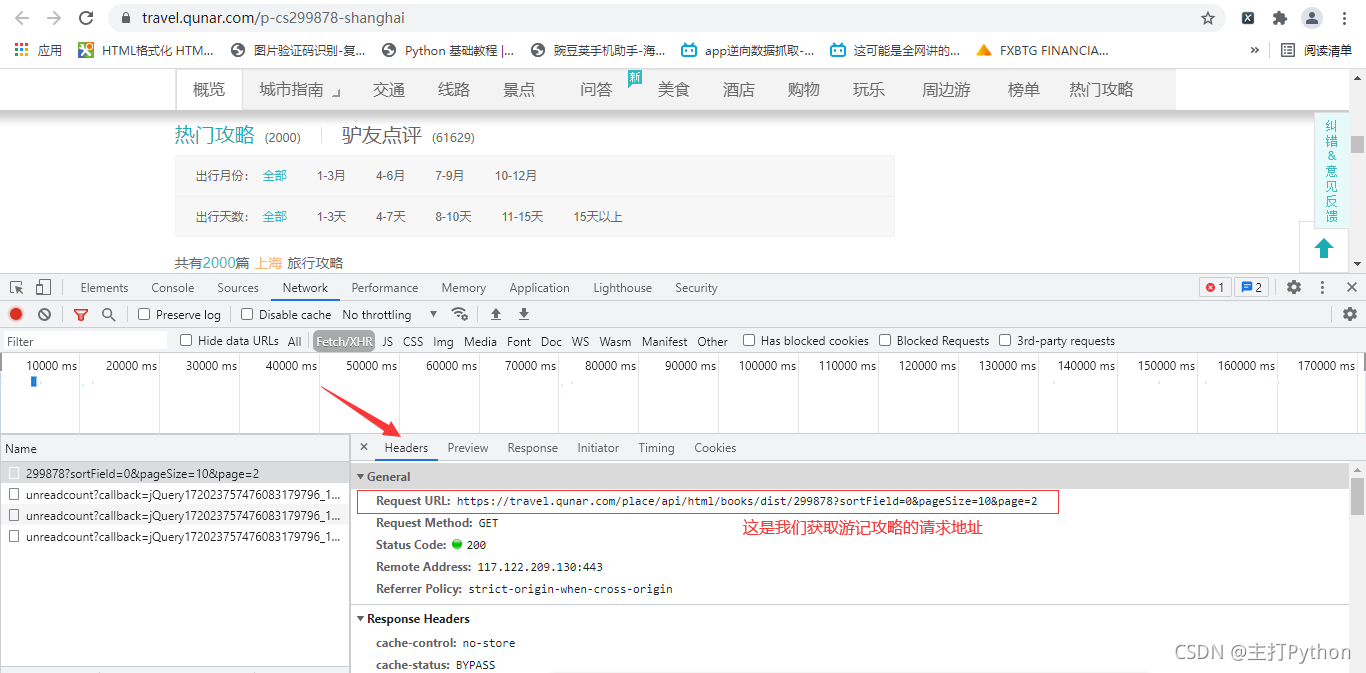
这样思路是不是清晰一点,来观察一下请求地址https://travel.qunar.com/place/api/html/books/dist/299878?sortField=0&pageSize=10&page=2
其中299878是上海城市的id page是页数
源码展示:
# !/usr/bin/nev python
# -*-coding:utf8-*-
import tkinter as tk
import re
from lxml import etree
import tkinter.messagebox as msgbox
from requests_html import HTMLSession
from threading import Thread
import os, xlwt, xlrd
from xlutils.copy import copy
session = HTMLSession()
class TKSpider(object):
def __init__(self):
# 定义循环条件
self.is_running = True
# 定义起始的页码
self.start_page = 1
"""定义可视化窗口,并设置窗口和主题大小布局"""
self.window = tk.Tk()
self.window.title('爬虫数据采集')
self.window.geometry('1000x800')
"""创建label_user按钮,与说明书"""
self.label_user = tk.Label(self.window, text='请选择城市输入序号:', font=('Arial', 12) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 484
484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











