










Network内请求的提取及存储
一、前情回顾
上次的文章中讲到了BeautifulSoup模块,可以用来解析和提取数据。那么,我们下面一起来尝试爬取一些内容,比如五月天歌单
首先,我们需要知道爬取五月天的歌单需要选择拥有五月天歌曲版权的平台去找,因此这里选择了QQ音乐。但是爬取之前,我们应该先看一看QQ音乐的robots协议:1

可以看到,QQ音乐只是禁止了我们爬取playlist(播放列表)的信息,因此我们可以放心爬取。接下来按流程进行爬取:
首先还是用谷歌浏览器打开网页,右击,点击检查并找到歌名对应的位置:

下面,我们就编写代码实现爬取五月天的歌单:
import requests
from bs4 import BeautifulSoup as bs
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'}
# 定义请求头,模拟用户访问网页。后面会具体讲述
res=requests.get('https://y.qq.com/portal/search.html#page=1&searchid=1&remoteplace=txt.yqq.top&t=song&w=%E4%BA%94%E6%9C%88%E5%A4%A9',headers=headers,verify=False)
# 提取网页数据
# verify=False功能为关闭网页认证
music_message=bs(res.text,'html.parser')
# 解析提取到的数据
name=music_message.find_all('a',class_="js_song")
# 找到全部的歌曲名称
for i in name:
# 逐一打印歌曲名称
print(i)
虽然有一条警告,但是我们运行成功了。不过,什么都没有显示。为了检查是不是我们书写有问题,我们先查看一下提取到的数据:
import requests
from bs4 import BeautifulSoup as bs
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'}
res=requests.get('https://y.qq.com/portal/search.html#page=1&searchid=1&remoteplace=txt.yqq.top&t=song&w=%E4%BA%94%E6%9C%88%E5%A4%A9',headers=headers,verify=False)
# verify=False功能为关闭网页认证
music_message=bs(res.text,'html.parser')
print(music_message)
由于结果太长,这里不放了。可以看到的是,我们并没有看到完整的网页源代码,并且这部分代码中也没有出现歌单。也就是之前介绍的方法不是用于这个场景下了。
二、网站的深度解析
之前已经提到过,网页源代码和我们怕渠道的内容不一致,我们只爬到了一部分源代码。那么,下面就介绍没有被爬到的源代码,被隐藏到了什么地方
1.Network简介
首先,我们观察一下这里:

我们之前所看的都是这个Elements里的内容,但是接下来,我们需要点击Network进行对隐藏的源代码的找寻。首先点击Network然后刷新页面(Network 记录的是实时网络请求。在网页已经加载完成的情况下,不会显示内容):

首先,Name栏第一个是html文件,我们不妨点开看看:

点开后选择Responses进行观察。细心的小伙伴也许已经发现了,这里面的内容和我们刚刚爬取的一致。事实上,我们刚刚的方法所爬取的内容就是这个文件里的源代码。上篇文章中选择的网页,源代码全部都放在这个文件里,而这次的网页不同。这也就是为什么我们之前行之有效的方法在这里失灵的原因。
下面我们继续观察下面这一栏,这一栏记录着请求数量,流量和时间的消耗,这正是浏览器工作的原理:它总是在向服务器发起请求。当这些请求完成,服务器就会返回我们在 Elements 中看到的网页源代码。刚刚我们查看的html文件只是这67个请求里第一个请求。一般来说,都是这种第 1 个请求先启动了,其他的请求才会关联启动,一点点地将网页给填充起来。我们也得到了一个方法:以后爬取内容之前先看看Network里面的第一个请求的内容,如果不包含我们想要的内容,之前的方法就不再适用了。
为了成功抓取到歌曲清单。我们就需要找到能让服务器返回歌名的那一个请求,然后针对这个请求应用requests库,模拟这个请求。
那么如何找到这个被隐藏起来的请求呢?别急,下面我们一步步分析。先上图:

红框圈起来的是我们需要重点了解的内容。左上角的红圈是启用 Network 监控(一般浏览器默认是打开),灰色圆圈是清空面板上的信息。勾选框 Preserve log的作用是 “保留请求日志”,当我们需要爬取会发生跳转的网页时,要记得点亮它,否则当发生页面跳转的时候,记录会被清空。下面一行,是对请求进行分类查看。我们对常用的标题进行介绍:
| 标题 | 功能 |
|---|---|
| ALL | 查看全部请求 |
| Fetch/XHR | 查看 XHR或Fetch。后面会重点介绍 |
| JS 和 CSS | 前端代码,负责发起请求和页面实现 |
| Img | 仅查看图片 |
| Media | 仅查看媒体文件 |
| Font | 文字字体 |
| Doc | Document的缩写,第 1 个请求一般在这里,用于检查想要爬取的内容是否在第一个请求里十分方便 |
| Other | 其他 |
| WS以及Manifest | 与网络编程有关,在此先不做介绍 |
下面的一行红框是时间轴,可以仅作为了解:
| 标题 | 功能 |
|---|---|
| name | 名字 |
| status | 请求状态代码 |
| type | 请求类型,例如xhr |
| size | 数据大小 |
| time | 请求所花费时间 |
| waterfail | 描述每个请求的起止时间 |
对Network有了基本了解之后,便要开始寻找被隐藏起的源代码咯~
2.XHR类请求
在 Network 中,有一类非常重要的请求叫做XHR(完整表述为XHR and Fetch)。平时使用浏览器上网的时候,经常有这样的情况:地址栏里的网址没有发生变化,但网页内容却在不断变化。这就叫做Ajax技术。应用这种技术可以在不改变网址的情况下更改网页内容,省流又节约时间。这种技术在工作的时候,会创建一个 XHR(或是 Fetch)对象,然后利用 XHR 对象来实现服务器和浏览器之间传输数据。XHR与Fetch 并没有本质区别,只是 Fetch 出现得比 XHR 晚一些。
对比前面的功能表,我们想要找的歌单不在网页源代码里,而且也不是图片,不是媒体文件,自然只会是在XHR里。也就是说,我们应该会在Fetch/XHR选项下找到包含歌曲清单的文件。可以看到,这里一共包含了38个请求,那么如何去寻找歌单呢?最为简单有效的方法就是遍历。在遍历之前,先给大家介绍一下这个表头:

随意点开一个请求,就会出现类似的界面。那么这个表头都是什么意思,怎样查看我们要找的内容是不是在对应请求下呢?老规矩,先总结,再上图:
| 名称 | 含义 |
|---|---|
| Headers | 请求信息 |
| Preview | 预览 |
| Response | 原始信息 |
| Timing | 时间 |
这次,我们需要在Preview(预览)里查看。依次点击请求,我们发现了以下几种样式:

只有红框圈起的内容样式是我们想要的歌单的可能出处,至于为什么是这样的格式,我们后文为大家介绍。先依次点击小三角打开折叠的内容,寻找到歌名所在的请求:client_search(客户端搜索),如果可以阅读它们的名字,自然可以更快地找到对应的请求。
找到这个请求之后,可以点击Headers(请求信息)查看这个请求的详细内容,比如:

这里就提供了这个请求的网址和状态码,以及服务器的地址和端口、记录请求的来源。注意一下这个网址,“?”(也或是#)会将网址分成两个部,这两部分分别代表什么后面会提到。现在我们将整个网址复制下来去浏览器打开看看:

这真是一个令人绝望的页面。但是粗略看过去,这里面的汉字有歌曲名、专辑以及歌曲信息,是我们想要的内容。所以硬着头皮看看:这是一个列表和字典相互嵌套的结构,和我们在Response 里看到东西是一致的。原始信息看不明朗,那我们就去预览里看看:

可以很清楚的看到内容分级,和我们的python语言一样,针对字典元素而言,相同的缩进是同一级的元素。比如蓝框里,semantic键对应一个字典,下面是缩进更多的键和值,代表这些内容属于semantic对应的的值;黄色框里先是一个列表,而后更多缩进的一行是列表的0号位置元素是一个字典元素,而后的内容同篮框;红色框file键对应的值是字典,fnote、genre键对应的值是数字,grp键对应的值是列表,但这三个键对应的缩进相同,因此就代表它们是字典内的同一级元素。
理解了这些数据分级,我们就可以用查找字典和数字元素的方法找到我们想要的歌曲清单了。首先找到第一首歌曲名所在的位置:

如图,这里name键对应的值是我们想要的。想要让代码找到这里,就必须逐层找下去:首先找到data键对应的值,然后找到song键对应的值,紧接着找到list键对应的列表下标为0的元素,最后找到name键对应的元素。
下面,我们一起编写代码:
import requests
from bs4 import BeautifulSoup as bs
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'}
# 定义请求头,模拟用户访问网页。后面会具体讲述
url='https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=62296692487895216&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E4%BA%94%E6%9C%88%E5%A4%A9&g_tk_new_20200303=5381&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0'
res=requests.get(url=url,headers=headers,verify=False)
# 下载字典的数据
# verify=False功能为关闭网页认证
# 注:其实我们可以写成
# res=requests.get(url,headers,verify=False)
# 这种形式,但由于担心初学者记不住参数的位置,
# 本文都以上文未屏蔽代码的写法书写代码
print(type(res))
# 检查res的数据类型
music_message=bs(res.text,'html.parser')
# 解析数据
print(music_message)
# 输出为:<class 'requests.models.Response'>
# {"code":0,"data":{"keyword":"五月天"...}...}
写到这里,相信小伙伴们已经发现了这个尴尬的事情,我们之前解析的数据是网页的源代码,可以用find_all()函数等寻找想要的内容。而这里解析过的数据是一个字典,find_all()等函数不再能派上用场了。
3.json格式在爬虫中的应用
想要解决刚刚的问题,我们必须了解一个新的概念——json。json可以这样来理解:json 是用字符串的样式书写的列表或数组(也可以是列表和数组的嵌套)。举个例子:
i='1,2,3,4'
# i是一个字符串
i=[1,2,3,4]
# i是一个列表
i='[1,2,3,4]'
# i是用json格式写的字符串
这种特殊的写法决定了,json 能够有组织地存储信息。

一般来说,这三条占得越多,数据的结构越清晰;占得越少,数据的结构越混乱。之前学习过的 html,是通过标签、属性来实现分层和对应来使网页的结构清晰。json 则是另一种组织数据的格式,长得和 Python 中的列表 / 字典非常相像。它和 html 一样,常用来做网络数据传输。可是列表或字典,只有在python语言中才能被识别,所以直接将他们封装起来会导致其他编程语言不能够识别。因此,json格式就出现了。它用字符串(文本)的方式上传字典/列表,这样就变成了所有的语言都可以识别的最朴素的数据类型了。也因此,json 数据就能实现,跨平台,跨语言工作。
那么,又如何在json格式下找到想要的内容呢?首先,我们需要把它转化回列表/字典类型,然后就可以应用字典的键,列表的下标来找内容了。
3.1解析json
我们可以在requests库的官方文档中,找到requests库处理 json 数据的方法。将json解析之后,就可以按照对列表和字典的操作完成数据的读取了:
import requests
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'}
res=requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=62296692487895216&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E4%BA%94%E6%9C%88%E5%A4%A9&g_tk_new_20200303=5381&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0',headers=headers,verify=False)
# 以上内容和之前代码类似
json_music = res.json()
print(type(json_music))
# 检查解析后的数据类型
# 结果为:<class 'dict'>
可以看到,这样解析之后数据类型已经变成了字典。那么之后的操作就类似于依据字典的键取字典的值了(不太懂的小伙伴点击这里看看「字典的读取」部分的内容):
# 将这段代码附加在刚刚的代码后面即可
first=json_music['data']
# 找到data键对应的子字典
second=first['song']
# 找到song键对应的子字典
list_music=second['list']
# 找到list键对应的列表
# 以上内容可以写成:
# list_music=json_music['data']['song']['list']
for music in list_music:
# 依据下标对列表进行遍历,并打印歌曲名
print(music['name'])
# 结果为:<class 'dict'>
# 温柔
# 后来的我们
# 知足
# 突然好想你
# 拥抱
# 倔强
# 你不是真正的快乐
# 盛夏光年
# 干杯
# 离开地球表面
这样,我们就成功的把歌名拿到了。不过还有一点点遗憾需要解决,那就是我们虽然已经学会了把json格式的数据转化成列表/字典,但是我们还没有介绍如何将字典/列表转化为json的格式。
那么,让我们简单学习一下:
3.2dumps()与loads()
dumps()与loads()是json模块下的两个函数,其功能分别为:将字典/列表等类型编码成json格式的字符串和将json格式的字符串解码为字典等原有类型。
那么这两个函数的书写格式分别为:
import json
result=json.dumps(dic,ensure_ascii=False,indent=i)
下面来解释参数的意义:dic代表一个要转化成json类型的字典类型,当然也可以是其他类型,如字典、列表、字符串。ensure_ascii=False的目的是让转化为json格式之后,打印result的结果依然是输入的文字内容,而非其对应的二进制编码。indent=i的目的是转换为json格式后,以“ ,”为标志,进行换行并空出i个空格。下面我们举个栗子:
# 导入 json 模块
import json
dic = {"title": "寻找歌单","name":"五月天"}
list_=["title", "寻找五月天","name","五月天"]
str_ = '"title":"寻找歌单","name":"五月天"'
dic = json.dumps(dic,ensure_ascii=False,indent=4)
list_1 = json.dumps(list_,ensure_ascii=False,indent=4)
str_ = json.dumps(str_,ensure_ascii=False,indent=4)
list_2 = json.dumps(list_,ensure_ascii=False)
list_3 = json.dumps(list_)
print(dic,type(dic),list_1,type(list_1),str_,type(str_),\
list_2,type(list_2),list_3,type(list_3),sep='\n')
结果为:

得到的这个结果除了印证了我们刚才的介绍之外,也可以发现,所有通过dumps转化成json格式的数据,其类型最终都为< str>类型而并非< requests.models.Response>、< BeautifulSoup>类型。也就是说,接下来我们学习的loads()函数他能操作的类型也只是str。因此并不能应用在将网页上下载来的XHR类请求的内容直接还原成字典等类型。
下面给大家介绍loads()函数。这个函数可以将json格式下的str类型的数据还原成字典等原有格式。该函数的书写格式为:
import json
result = json.loads(str_)
参数str_代表一个str类型的数据。下面举例说明:
import json
old_dic='''{
"title": "寻找歌单",
"name": "五月天"
}'''
dic = json.loads(old_dic)
print(dic,type(dic),sep='\n')
# 结果为:{'title': '寻找歌单', 'name': '五月天'}
# <class 'dict'>
那么关于json的应用就先给大家普及这么多了。如果小伙伴想要深入了解可以到以下网站去拜访:
JSON 编码和解码器,dumps()与loads()的使用
4.什么是“带参数请求数据”
学习这节之前,我们先提出一个问题:上面爬取到的只有十首歌曲的歌名。如果我们想要拿到五月天的全部歌单,该如何操作呢?
打开网站,滑动到网页底部:

好像已经没有正常渠道翻阅更多的歌曲内容了,而客户端打开又没办法爬取。所以又要怎么做才能查找到其他的歌曲内容呢?
首先我们先换一个网站观察,给大家推荐豆瓣的“选电影”:

这个网页可以翻阅更多的电影,也就友好了很多。我们先照例尝试寻找包含有电影名称的XHR请求:
小提示:我们顺便介绍一个寻找包含电影名称的XHR请求的高效方法。观察这个界面:

这里的Name栏有四个XHR请求,然后我们点击加载更多按钮:

这里就出现了第五个请求了。这个请求里就包含了我们想找的电影信息哦~可以先记住这个请求的名字,方便之后的操作。不仅如此,我们将鼠标移动到可以点击的部分,旁边的Name栏都会有新的请求加载出来。这种方法非常好用的。
下面,我们开始尝试爬取电影名称:
import requests
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'}
res=requests.get('https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0',headers=headers,verify=False)
movies = res.json()
finds=movies['subjects']
for movie in finds:
# 依据下标对列表进行遍历,并打印电影名
print(movie['title'])
和之前的代码如出一辙,并且输出结果也一样,只包含了第一页的所有电影:

只有我们点击加载更多,才能看到更多的影片内容。显然,如果我们不断的手动翻页、找到新的请求、获取新的网址、然后调用爬虫爬取信息,过程也很繁琐。有没有更简单的方式呢?
这就要说到网页的结构了。老规矩,先观察:

左侧的图片是点击加载更多前后的包含影片名称的XHR请求内容,右面是其对应的网址。大家仔细看发现什么不同了吗?
下面,我们做一个关于这个网址的深度解析:
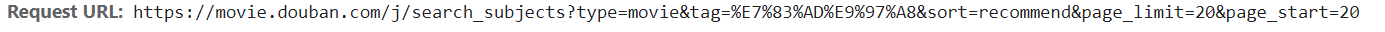
先看到这个网址,它是以“?”作为分隔。并且,大多数网站前半部分形如:https://xx.xx.xxx/xxx/xxx,这部分是我们所请求的地址,它会告诉服务器,我们想访问哪里;而后半部分,多形如:xx=xx&xx=xxxxxx&xx=xx&……,这我们的请求所附带的参数,它会告诉服务器,我们想要什么样的数据,并且数据之间用“&”连接。
上述图片中提到的不同就是page_start所对应的数字。这就为我们编写爬虫提供了一个理论的可能,假如我们可以改变这个参数所对应的值,是不是就能实现自动翻页了呢?这就涉及到带参数请求数据了。
怎样完成“带参数请求数据”
上文提到,只要想办法改掉page_start参数的值就好了。page_limit=20这个参数不难理解,代表了每加载一页,就显示20部电影,那么page_start参数应该也是以20为一个梯度。因此,对之前的代码加以完善:
import requests
for i in range(3):
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'}
res=requests.get('https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start='\
+str(i*20),headers=headers,verify=False)
# i*20必须要转换成字符串形式才能正常运行
# 注:如果不用字符串拼接的形式,Python会认为这是一段完整的字符串,不会进行修改i的值并计算
movies = res.json()
finds=movies['subjects']
for movie in finds:
# 依据下标对列表进行遍历,并打印电影名
print(movie['title'])
大家可以尝试运行一下,这样确实满足了我们的需求。但是直接这样修改连接参数还是比较麻烦,代码也太长,不够优雅。不要小看代码简介的威力,于大型项目来说,简洁的代码会很大程度的缩减维护的难度。
在解决这个问题之前,我们先观察一下这个网址的特色:
首先,我们点击Headers下General和Query String Parameters(以下简称QSP)前面的三角进行一个对比,不难发现,整个网址“?”后面的内容是:
type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=20
而QSP的内容是:

是不是前面的内容就是后面的内容用“&”连接起来的结果呢?也许会有小伙伴提出疑问,type对应的内容不一样呀…
那请看下面这段代码:
str_='热门'
print(str_.encode('utf-8'))
# 输出为:b'\xe7\x83\xad\xe9\x97\xa8'
这串东东也只是“热门”的utf-8的编码而已。
那么简化代码就可以从QSP入手。事实上,requests 模块里的 requests.get() 提供了一个参数叫 params,可以让我们用字典的形式,把参数传进去:

没有看懂的小伙伴也没有关系,下面我们一起来简化代码:
import requests
url='https://movie.douban.com/j/search_subjects'
# 标记请求地址
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'}
for i in range(3):
p={'type': 'movie',
'tag': '热门',
'sort': 'recommend',
'page_limit': '20',
'page_start': str(i*20)}
# 标记附带参数
res=requests.get(url=url,params=p,headers=headers,verify=False)
movies = res.json()
finds=movies['subjects']
for movie in finds:
# 依据下标对列表进行遍历,并打印电影名
print(movie['title'])
运行这段代码,观察结果:

这样一来,我们就成功的爬取到了自己想要的全部内容了。其实,我们也可以通过改变page_limit这个参数改变每一页显示的电影数量。如果仅设置其为60,相当于现在一夜就能显示之前三页的内容,也就可以一口气爬取原来三页的内容。请大家自行尝试。
说了这么多,还有一个疑问没有解决,那就是这个headers是什么意思。我们先观察一下Request Headers(请求头):

看看这里user-agent(用户代理)的信息,是不是也和我们代码里的headers字典里的内容很像呀?其实,user-agent记录的就是我的电脑系统信息和浏览器(谷歌浏览器)。在其之前,还有origin(源头)和 referer(引用来源),记录了这个请求最初的起源的页面,referer会比origin携带的信息更多些。我们也可以看看官方文档:

如果不修改user-agent,当我们使用爬虫爬取内容时,其会默认为python,这样会被很多服务器识别出来,可能会造成无法爬取的结果,而对于爬取某些特定信息,也要求你注明请求的来源,即 origin 或 referer 的内容。处理这些的方法也很简单,只要将这些内容封装到一个字典里就好了,例如:
import requests
url = 'https://pagead2.googlesyndication.com/getconfig/sodar'
headers = {
# 伪装请求头
'origin': 'https://movie.douban.com',
# 请求来源
'referer': 'https://movie.douban.com/explore',
# 请求来源
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4595.0 Safari/537.36'
# 标记请求从什么设备,什么浏览器上发出
}
p={...}
res=requests.get(url=url, params=p, headers=headers, verify=False)
...
三、再战五月天
上面我们已经详细解析了网站,现在,我们来继续最开始的问题,怎么才能爬取五月天的全部歌名。当然,给大家的例子里,只爬取前三页的信息,学会的小伙伴可以自己尝试。
首先看到“#”后面的信息:page=1&searchid=1&remoteplace=txt.yqq.top&t=song&w=五月天
依照刚才讲的内容,凭直觉这里好像改变page就能够完成翻页。但需要注意的是,一定要用谷歌浏览器打开,否则附带参数可能会不太一样:

果然成功翻到了下一页,并且还出现了个惊喜,蓝色框圈出来了翻页过程中多出的那个XHR请求,正是之前我们采用遍历的方法寻找的包含歌单的请求。那这种方法寻找歌曲名岂不也是一个高效的方法~
回归正题,既然改变page可以拿到下一页的歌曲名,我们的代码就可以着手了:
import requests
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
headers = {
'referer': 'https://y.qq.com/portal/search.html',
# 请求来源
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
# 标记了请求从什么设备,什么浏览器上发出
}
for x in range(3):
params = {
'ct': '24',
'qqmusic_ver': '1298',
'new_json': '1',
'remoteplace': 'sizer.yqq.lyric_next',
'searchid': '94267071827046963',
'aggr': '1',
'cr': '1',
'catZhida': '1',
'lossless': '0',
'sem': '1',
't': '7',
'p': str(x + 1),
'n': '10',
'w': '五月天',
'g_tk': '1714057807',
'loginUin': '0',
'hostUin': '0',
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'utf-8',
'notice': '0',
'platform': 'yqq.json',
'needNewCode': '0'
}
# 下载该网页,赋值给 res
res = requests.get(url, params=params, headers=headers)
# 使用json来解析res.text
jsonres = res.json()
# 一层一层地取字典,获取歌词的列表
list_lyric = jsonres['data']['lyric']['list']
# list_lyric 是一个列表,lyric 是它里面的元素
for lyric in list_lyric:
# 以 content 为键,查找歌名
print(lyric['title'])
看看运行结果:

OK,满足了。那么下面,我们再做一个尝试,看看能不能爬取五月天歌曲的歌词:

找到了歌词的位置,我们可以进行爬取了:
import requests
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
headers = {
# 请求来源
'referer': 'https://y.qq.com/portal/search.html',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
for x in range(3):
params = {
'ct': '24',
'qqmusic_ver': '1298',
'new_json': '1',
'remoteplace': 'sizer.yqq.lyric_next',
'searchid': '94267071827046963',
'aggr': '1',
'cr': '1',
'catZhida': '1',
'lossless': '0',
'sem': '1',
't': '7',
'p': str(x + 1),
'n': '10',
'w': '五月天',
'g_tk': '1714057807',
'loginUin': '0',
'hostUin': '0',
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'utf-8',
'notice': '0',
'platform': 'yqq.json',
'needNewCode': '0'
}
# 下载该网页,赋值给 res
res = requests.get(url, params=params, headers=headers)
# 使用 json 来解析 res.text
jsonres = res.json()
# 一层一层地取字典,获取歌词的列表
list_lyric = jsonres['data']['lyric']['list']
这部分的代码和之前相似,不做过多介绍了(ps:本节后面的代码也都需要拼接到这段后面)。下面我们尝试打印出来:
for lyric in list_lyric:
# 以 content 为键,查找歌词
print(lyric['content'])
看看结果:

内容是正确了,但是太乱了,我们希望爬取的内容能够正常换行。
1.split()方法
split()方法可以将字符串进行切片,结果存放到一个数组里。我们使用split()方法,最多有2个参数,使用方法如下:
# 假设str_是一个字符串
str_.spilt('定义以某字符为切片点','替换数量')
# 没有第一个参数则默认以空格或\n为切片点
# 将其删除并进行切片(如果二者都有都会删除)
# 没有第二个参数,替换全部的内容
详细的介绍大家可以参考Python split()方法。
知道了这种方法,我们对刚才的代码修改一下:
for lyric in list_lyric:
# 以 content 为键,查找歌词
con=lyric['content'].split()
for i in con:
print(i)
看看运行结果:

换行是对了,可是为什么还是有\n呢?那么我们插入print函数看看问题出在哪:
for lyric in list_lyric:
# 以 content 为键,查找歌词
con=lyric['content'].split()
print(con)

看,我们刚刚看到的\n在字符串中实际上是\n。想要得到我们预期的结果是必须要去掉\n。可见切片的方法还是比较麻烦的。
2.replace()方法
通过切片的方式,我们发现我们看到的\n实际上是\n。那么如果我们把这个字符串中的\n替换成\n,那么所有的问题不就都解决了吗~
下面我们就介绍一个可以替换内容的方法——replace():
res=str_.replace('需要被替换的内容','用于替换的内容')
# 假设str_是一个字符串
那么通过这个方法是不是可以把\n替换成\n从而得到我们需要的结果呢?尝试修改一下刚刚代码:
for lyric in list_lyric:
# 以 content 为键,查找歌词
print(lyric['content'].replace('\\n','\n'))
看看结果:

非常完美。这节的内容到此就结束了,希望大家学懂这两个非常实用的方法。
四、存储爬到的数据
之前的内容针对爬取网站有了更深入的介绍,相信大家已经能够融会贯通。接下来我们处理爬取到的内容如何存储的问题。
看过我之前内容的小伙伴应该熟悉读写以下两种格式的文件:.txt和.csv。实际上,这两种格式都可以用记事本打开,.txt文件是纯文字的文本,而.csv是文字间以“ ,”隔开的文本。当然也可以用Excel打开,表格内存放以逗号连接的文字内容:
import csv
con=[['姓名','成绩','年龄'],['张三',73,18],['李四',82,16],['王五',96,17],['赵六',68,19]]
with open("test.csv", 'w+', encoding='utf-8-sig',newline='') as test:
writer = csv.writer(test)
for i in con:
writer.writerow(i)
test.seek(0)
read = csv.reader(test)
for a in read:
print(a)
# 结果为:['姓名', '成绩', '年龄']
# ['张三', '73', '18']
# ['李四', '82', '16']
# ['王五', '96', '17']
# ['赵六', '68', '19']
下面我们分别以记事本和和Excel文档打开:

至于具体的操作大家可以参考我的博客编码译码与文件操作以及python的模块调用。
这节的重点在于操作.xlsx文件。这种文件需要用Excel文档打开,并且比.csv格式拥有更多的功能,也需要用到不同的模块。操作.xlsx文件则需要借助 openpyxl 模块,这个模块并非python自带,所以需要我们自行安装。安装过程详见爬虫相关环境搭建。
学习.xlsx文件的读写之前,先来了解一下这种格式文件的基本结构。一个 Excel 文档也称为一个工作薄(workbook),每个工作薄里可以有多个工作表(wordsheet),当前打开的工作表又叫活动表:

每个工作表里有行和列,通常我们会用列数+行数描述一个单元格(cell),如上图中的A1。
清楚了基础知识,我们来说一下.xlsx文件的读写。.xlsx文件的读写都明显区别于.txt文档和.csv文档。我们先说先说写入:
import openpyxl
wb= openpyxl.Workbook()
# 利用 openpyxl.Workbook() 函数创建新的 workbook(工作薄)对象,
# 即创建新的空的.xlsx文件
sheet = wb.active
# wb.active 为获取这个工作薄的活动表,通常是第一个工作簿
sheet.title = '练习文档'
# 用 .title 给工作表重命名。
# 现在第一个工作表的名称就会由原来默认的 “sheet1” 改为 "练习文档"
sheet['A1'] = '单元格A1'
# 向单个单元格写入数据。
# 写入数据后指针会自动跳转到下一行等待我们继续写入内容
score1 = ['math', 95]
# 创建列表,准备写入
sheet.append(score1)
# 将刚刚的列表内容写入新的一行
con=[['姓名','成绩','年龄'],['张三',73,18],['李四',82,16]]
for i in con:
sheet.append(i)
# 继续写入二维列表
wb.save('test.xlsx')
# 保存修改的.xlsx文件,并将其命名为“test”
wb.close()
# 关闭 Excel
那么穿插着代码,我们已经学过了.xlsx文件如何写入了,接下来介绍如何读取.xlsx文件的内容。首先我们需要打开文件,这个过程要用到 openpyxl 中的 load_workbook 方法:
wb=openpyxl.load_workbook('文件名.xlsx')
这句代码可以打开我们刚刚创建好的test.xlsx文件,打开文件之后我们才可以查看里面的内容。
紧接着我们需要打开工作表:
sheet = wb['工作表名称']
打开练习文档以后,我们就可以读取里面的内容了。值得注意的一点是,这里的内容可以理解为以二维列表存储的,但是我们可以直接以列+行的形式寻找到特定单元格内的元素。但是如果我们想要遍历,依然需要两个for循环:
A1_value = sheet['想读取的单元格'].value
# 查看单元格的内容
for con in sheet:
for i in con:
print(i,end=' ')
print()
# 遍历整个工作表
我们把这些内容整理起来,查看一下刚刚新建的文档吧:
from openpyxl import load_workbook
wb = load_workbook(filename='test.xlsx', read_only=True)
ws = wb['练习文档']
A1_value = ws['A1'].value
print(A1_value)
print('--------------------')
for row in ws.rows:
for cell in row:
print(cell.value,end=' ')
print()
# Close the workbook after reading
wb.close()
# 结果为:单元格A1
# --------------------
# 单元格A1 None None
# math 95 None
# 姓名 成绩 年龄
# 张三 73 18
# 李四 82 16
相信大家已经看懂了。只是这里介绍的方法是最简单的一部分。如果想深入了解,大家可以查看官网进行学习。
接下来,我们实战一下,来存储另一位歌手——河图的歌单和专辑信息:
import requests
import openpyxl
con=[['歌曲名','专辑名']]
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
headers = {
'referer': 'https://y.qq.com/',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
for x in range(3):
params = {
'ct': '24',
'qqmusic_ver': '1298',
'new_json': '1',
'remoteplace': 'txt.yqq.song',
'searchid': '55102789769710202',
't': '0',
'aggr': '1',
'cr': '1',
'catZhida': '1',
'lossless': '0',
'flag_qc': '0',
'p': str(x + 1),
'n': '10',
'w': '河图',
'g_tk_new_20200303': '5381',
'g_tk': '5381',
'loginUin': '0',
'hostUin': '0',
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'utf-8',
'notice': '0',
'platform': 'yqq.json',
'needNewCode': '0',
}
res = requests.get(url, params=params, headers=headers)
jsonres = res.json()
list_lyric = jsonres['data']['song']['list']
# 以上代码来自于上文
for lyric in list_lyric:
con.append([lyric['name'],lyric['album']['name']])
# 将歌曲名与专辑名存入二维列表
wb = openpyxl.Workbook()
# 利用 openpyxl.Workbook() 函数创建新的 workbook(工作薄)对象,
# 即创建新的空的.xlsx文件
sheet = wb.active
# wb.active为获取这个工作薄的活动表,通常是第一个工作簿
sheet.title = '河图专栏'
# 将工作簿重新命名
for write in con:
sheet.append(write)
# 写入歌曲信息
wb.save('河图.xlsx')
# 保存修改的.xlsx文件,并将其命名为“河图”
wb.close()
# 关闭 Excel
运行一下试试,看是否满足我们的要求:

很棒!是不是像个自己点个赞呢~
这次的学习就到这里了,我是有理想的打工人,日后还会带给大家更好的作品,期待和大家共同进步~
查看robots协议只需要在对应官网后面加入robots.txt即可。 ↩︎















 2060
2060











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









