






背景:ansible脚本批量部署60台节点,脚本没跑几步有一台节点就开始报错,试过多次,都是同一个节点报同一个错

偶尔还抛出这个错误
 1、以为root密码过期,单独ssh root@ip mkdir /tmp/hehe.log, 正常
1、以为root密码过期,单独ssh root@ip mkdir /tmp/hehe.log, 正常
2、有问题的节点磁盘满了,/tmp目录装不下
3、/root/.ansible目录没权限,修改ansible.cfg配置文件中remote_tmp的配置项
4、跑ansible的时候线程是--forks 50 将线程数改小
5、使用remote_user: root的方式sudo提权去跑ansible脚本
6、以为是脏数据,将/root/.ansible和/tmp下ansible目录全部删除
7、以为是缓存问题,累积错误次数太多,使用--flush-cache跑,报错依旧
8、还以为是ansible、openssh版本问题
后面查看有问题节点的message日志,发现只要ansible主机点跑脚本,就会出现如下报错

于是重启服务器,在如下页面按e进入编辑模式
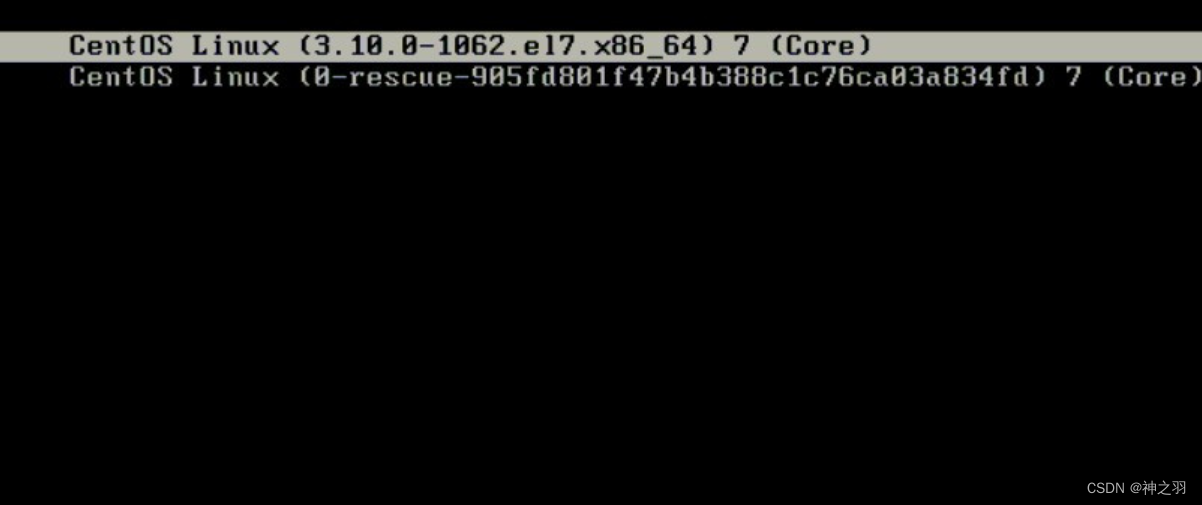
在linux16这一行末尾添加init=/bin/sh,然后按ctrl+x
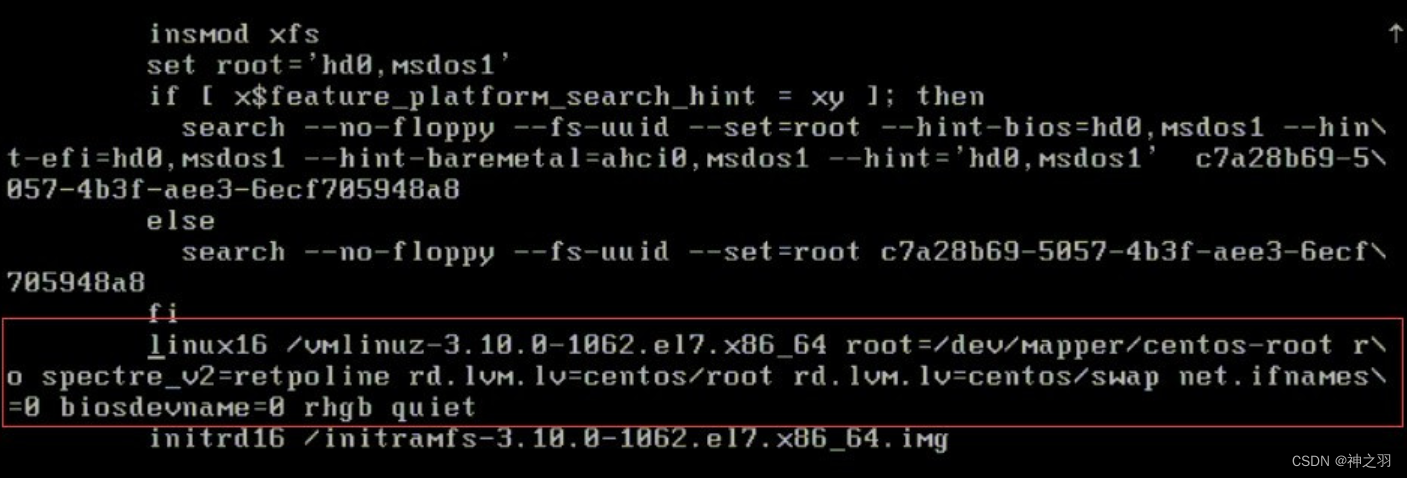
最后执行xfs_repair -d /dev/dm-0,注意得加上-d。最后重启服务器
总结:如果没啥好办法就多看看message日志吧















 2496
2496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









