







目录
1. grep 作用
文本搜索工具,根据用户指定的“模式”(过滤条件),对目标文本逐行进行匹配,并打印输出匹配到的行。
模式:由正则表达式的元字符串及文本字符串所编写的过滤条件
2. grep 完整语法结构
grep [options] [pattern] file
命令 参数 匹配模式 文件数据
- 上述语法结构中,经常可配合下面的参数一起使用
| 常用参数 | 解释 |
|---|---|
| -i | 忽略大小写 |
| -o | 仅显示匹配到目标字符串 |
| -v | 显示不能被匹配到的字符串(反转) |
| -E | 支持使用扩展的正则表达式字符串 |
| -q | 静默模式,不输出任何信息 |
3. grep常用的参数总结
| 常用参数 | 解释 |
|---|---|
| -v | 排除匹配结果 |
| -n | 显示匹配行与行号 |
| -i | 不区分大小写 |
| -c | 只统计匹配行数 |
| -E | 使用egrep命令 |
| -o | 只输出匹配内容 |
| -w | 只输出过滤的单词 |
| -F | 不适用正则表达式 |
| -l | 列出包含匹配项的文件名 |
| -L | 列出不包含匹配项的文件名 |
4. grep中常用正则表达式
4.1 基本常用正则表达式汇总
| 表达式 | 解释 |
|---|---|
| ^ | 用于模式最左侧,如 “^yu” 即匹配以yu开头的单词 |
| $ | 用于模式最右侧,如 “yu$” 即匹配以yu结尾的单词 |
| ^$ | 组合符,表示空行 |
| . | 匹配任意一个且只有一个字符,不能匹配空行 |
| | | 使用egrep命令 |
| * | 重匹配前一个字符连续出现0次或1次以上 |
| .* | 匹配任意字符 |
| ^.* | 组合符,匹配任意多个字符开头的内容 |
| .*$ | 组合符,匹配任意多个字符结尾的内容 |
| [abc] | 匹配 [] 内集合中的任意一个字符,a或b或c,也可以写成 [ac] |
| [^abc] | 匹配除了 ^后面的任意一个字符,a或b或c,[]内 ^ 表示取反操作 |
4.2 案例演示
- 准备文件names.txt
vim names.txt
#填入一下内容
I am god
I like watching the World Cup
我是神,你不能。。。。。
hello World
Hi,sarry
智商250
#这是注释行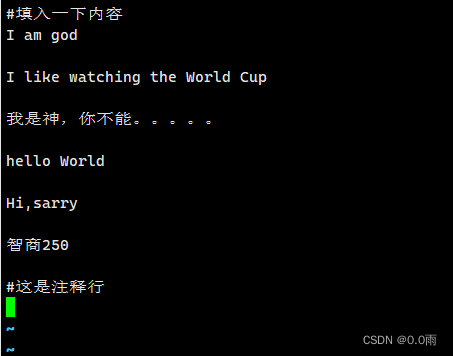
- 注:文本直接复制进去会有换行符号,需要在编辑器里面删除空行重新换行
4.2.1 过滤非空的行
grep '^$' names.txt -v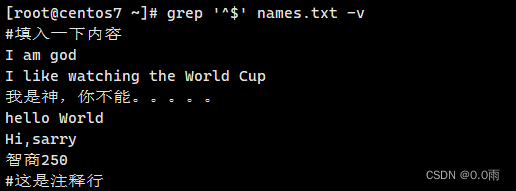
4.2.2 找出names.txt中的未注释行,并过滤空行
grep "^#" names.txt -v | grep "^$" -v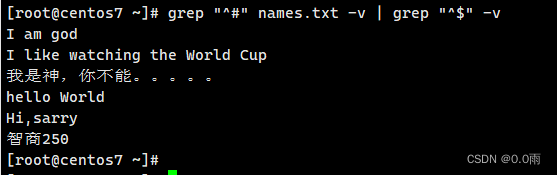
4.2.3 输出以h开头的行,不区分大小写
grep -i "^h" names.txt 
4.2.4 输出以"。"结尾的行
grep -n "。$" names.txt 
4.2.5 匹配文本中至少包含一个 am 的
grep -i ".am" names.txt
4.2.6 匹配文本中包含数字的行
- 考察对 [abc] 类似的用法
- [a-z] 匹配所有小写单个字母
- [A-Z] 匹配所有大写单个字母
- [a-zA-Z] 匹配所有单个大小写字母
- [0-9] 匹配所有单个数字
- [0-9a-zA-Z] 匹配所有数字和字母
grep "[0-9]" names.txt
4.3 扩展正则表达式使用
| 表达式 | 解释说明 |
|---|---|
| + | 表示匹配前一个字符一次或多次 |
| ? | 表示匹配前一个字符0次或1次 |
| () | 将一个或多个字符捆绑在一起,当作整体进行处理 |
| {n,m} | 匹配目标字符,最少n次,最多m次 |
| {n,m} | 匹配目标字符,最少n次,上不封顶 |
| > | 匹配位于 目标字符开头的字符串,即截止到 < 前面的字符为止,精确匹配 |
| < | 匹配位于 目标字符结尾的字符串,即截止到 > 前面的字符为止,精确匹配 |
4.4 案例演示
4.4.1 筛选前一个字符包含e的的文本行
grep -E 'e+' names.txt















 1090
1090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









