






Redis
6379
常用命令:
查看key的生存时间(ttl)、获取所有的Key(keys *)、删除key命令(Del)
String类数据类型的使用
增:添加数据(set)、添加多个数据(mset)、添加数据时指定过期时间(setex)
SETNX key value :如果key不存在,则创建并赋值
- 时间复杂度: 0(1)
- 返回值:设置成功,返回1;设置失败,返回0。
127.0.0.1:6379> ttl num #查看key为‘num’的数据的过期时间,默认数据永不过期。
(integer) -1 #-1代表永不过期
127.0.0.1:6379> setex university 5 NEU #设置key为‘university’,value为‘NEU’的数据过期时间为5秒
OK
删:删除数据(del)
改:追加字符串(append)、自增(incr)、自减(decr)、增加指定值(incrby)
查:获取数据(get)、查询多个数据(mget) 、strlen返回字符串长度(strlen)
String类型是最常用的数据类型,value值表面上是字符串,实际上可以为字符串、整型和浮点型,Redis能够自动识别。
使用场景
- 计数器
- 统计多单位数量
- 粉丝数
- 对象缓存存储
Hash数据类型的使用
增:添加数据(hset)、添加多条数据(hmset)、不存在元素则添加(hsetnx)
删:删除特定的key对应的value(hdel)
改:给特定的key值对应value增加数值(hincrby)
查:获取hash的所有字段(hgetall)、获取特定的key值对应value(hget)、获取hash表长度(hlen)、查看hash中是否存在特定的key值对应的数据(hexists)、查看hash表所有key值(hkeys)、查看hash表所有value值(hvals)。
使用场景
- 适合存储对象类数据。
List数据类型的使用
增:左增 (lpush)、 右增(rpush)、前插入(linsert key before pivot insertValue)、后插入(linsert key after pivot insertValue)、获取最后元素加入新的列表(rpoplpush oldList newList)
删:按值删除 (lrem key count value)
改:更改值(lset key index newValue)
查:按索引范围查 (lrange key start stop) 、按索引查(lindex key index)、从左边弹出(lpop)、从右边弹出(rpop)
长度相关:获取长度(llen)、按索引截取保留部分(ltrim key start stop)
使用场景
- 消息排队
消息队列 ( Lpush Rpop)
栈 (Lpush Lpop)
Set数据类型的使用
增:添加元素(zadd)
删:删除指定元素(srem key data)、随机删除元素(spop)
改:移动指定元素到新集合(smove oldSet newSet data)
查:查看所有元素(smembers)、查看某一元素是否存在(sismember)、查看长度(scard)
集合操作:差集(sdiff set1 set2)(set1有的,set2没有)、交集(sinter set1 set2)、并集(sunion set1 set2)
使用场景
- set数据类型集合操作非常方便,可以求交集、并集和差集
- A与B的差集与B与A的差集不一定相同
- 交集可用于求共同关注,共同好友,共同爱好等需求
zSet数据类型的使用
增:添加数据(zadd)
删:删除数据(zrem)
查: 按从大到小的顺序(zrevrange)排列、按从小到大的顺序排列(zrangebyscore)、查看元素个数(zcard)、查询值在指定区间的个数(zcount key min max)
127.0.0.1:6379> zadd myzset 1 one 2 two 3 three #添加一个key为myzset的有序集合,one赋予1分,two赋予2分,three赋予3分
(integer) 3
127.0.0.1:6379> zrange myzset 0 -1 #查看myzset的所有元素
1) "one"
2) "two"
3) "three"
127.0.0.1:6379> zrangebyscore myzset -inf +inf #让myzset中元素从小到大排序
1) "one"
2) "two"
3) "three"
127.0.0.1:6379> zrange myzset 0 -1
1) "one"
2) "two"
3) "three"
127.0.0.1:6379> zrevrange myzset 0 -1 #myzset中元素从大到小排序
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> zrem myzset one #移除myzset中的元素one
(integer) 1
127.0.0.1:6379> zrevrange myzset 0 -1
1) "three"
2) "two"
127.0.0.1:6379> zcard myzset #统计myzset中元素的个数
(integer) 2
127.0.0.1:6379> zcount myzset 1 1 #统计myzset中值为1的个数
(integer) 0
127.0.0.1:6379> zcount myzset 1 2
(integer) 1
使用场景
- 排序:存储班级成绩表,工资表排序
- 普通消息:1 重要消息:2 -->带权重进行判断
- 排行榜应用实现,取top N。
事务
redis事务命令
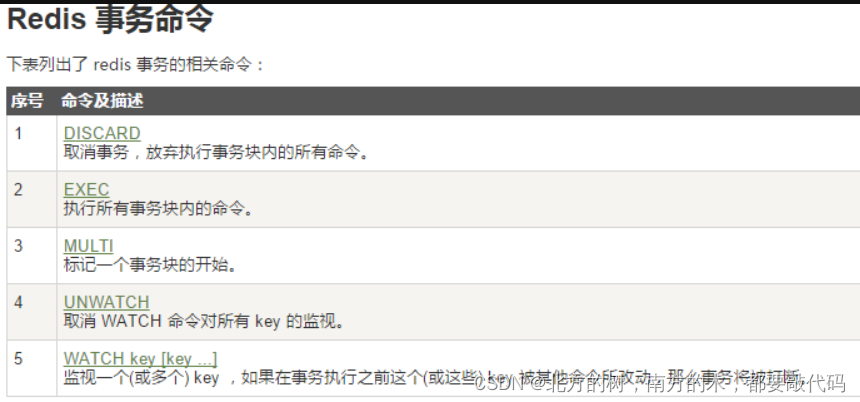
redis事务的本质:一组命令的集合。一个事务中的所有命令都会被序列化,在事务执行过程中,所有命令都会被顺序执行。
一次性,顺序性,排他性的执行一些列的命令
mutle-------队列 set set set 执行--------exec
redis事务没有隔离级别的概念
redis单条命令保证原子性,事务不保证原子性
redis事务:
开启事务(mutle)
命令入队(...)
执行事务(exec)

取消事务 DISCARD --事务队列中的命令都不会被执行
锁
悲观锁:
乐观锁:
redis监视 watch命令
我们知道当命令在队列中时,是没有执行命令,这个时候如果有别的线程修改对应的队列中命令字段对应的数据值,就无法保证隔离性。但是使用WATCH机制可以保证,WATCH机制的原理是通过在命令入队之前,监控对应的键是否修改,如果修改,那么在EXEC执行时就会异常。
![[图片]](https://img-blog.csdnimg.cn/b91ba1c9f833483d851b9cd1433b2071.png)
具体就是EXEC值执行发现WATCH监听的数据有修改,就是放弃执行。但是如果没有WTCH机制,exec队列中命令也会读取最新的值,但是这样其实没有办法保证隔离性。
![[图片]](https://img-blog.csdnimg.cn/882ff37d5a044725928f850268c2cdcb.png)
测试多线程修改值,使用WATCH可以当做redis的乐观锁操作。
如果修改失败,获取最新值
![[图片]](https://img-blog.csdnimg.cn/c7b90b28f5ed4373a66b35eefb4766b7.png)
持久化
快照
持久化,在规定时间内,执行了多少次操作,会持久化到文件.rdb.aof
redis是内存数据库,如果没有持久化,数据就会断电即失
如何实现持久化----rdb aof
RDB
在指定的时间内将内存中的数据集快照写入磁盘,恢复时是将快照文件直接读到内存里
redis会fork一个子进程来进行持久化,会先将数据写入一个临时文件,持久化结束后,再把这个临时文件替换到上一次写好的持久化好的文件。整个过程中主线程不会进行IO操作,性能较高。最后一次持久化可能会造成数据丢失。
rdb保存的文件是dump.rdb
在主从复制中,rdb就是备用,放在从机上。
触发rdb机制
-
在配置文件中,save满足规则,会自动触发
![[图片]](https://img-blog.csdnimg.cn/2ed6408379bd42f9894666510ec5eb24.png)
-
执行flushall命令,也会触发
-
退出redis,也会产生rdb文件
触发后,备份就自动生成一个dump.rdb文件
rdb优点
- 适合大规模的数据恢复
- 对数据的完整性要求不高
rdb缺点
- 需要一定的时间间隔进行操作,如果系统突然宕机,最后一次的数据可能会丢失
- fork子线程需要额外的内存空间
AOF
用日志的形式来记录每个写操作,将redis执行过的所有指令记录下来(读操作不记录),只追加文件不修改修改文件。redis恢复的时候会根据日志文件把指令从头到尾执行一次来恢复数据。
aof保存的是appendonly.aof文件
AOF优点
在配置文件中
![[图片]](https://img-blog.csdnimg.cn/59562f9c99a047269419bf65748cd687.png)
- appendfsync always : 每一次修改都同步,数据的完整性更高
- appendfsync everysec: 每秒同步一次,可能会丢失一秒的数据
- appendfsync no: 从不同步,效率最高
AOF缺点
- 数据恢复的效率 :aof的文件要比rdb文件大很多,数据恢复起来也要慢很多
- 运行效率: aof运行效率也要比rdb慢很多,所以redis默认配置使用rdb持久化
redis发布订阅
发布订阅模式的基本命令
Psubscribe 命令订阅一个或多个符合给定模式的频道。每个模式以 * 作为匹配符,比如 it* 匹配所有以 it 开头的频道( it.news 、 it.blog 、 it.tweets )
Psubscribe 命令基本语法如下:
PSUBSCRIBE pattern [pattern ...]
Redis Pubsub 命令用于查看订阅与发布系统状态,它由数个不同格式的子命令组成。
PUBSUB <subcommand> [argument [argument ...]]
Publish 命令用于将信息发送到指定的频道。
Publish 命令基本语法如下:
PUBLISH channel message
Punsubscribe 命令用于退订所有给定模式的频道。
Punsubscribe 命令基本语法如下:
PUNSUBSCRIBE [pattern [pattern ...]]
Subscribe 命令用于订阅给定的一个或多个频道的信息。
Subscribe 命令基本语法如下:
SUBSCRIBE channel [channel ...]
Unsubscribe 命令用于退订给定的一个或多个频道的信息。
Unsubscribe 命令基本语法如下:
UNSUBSCRIBE channel [channel ...]
![[图片]](https://img-blog.csdnimg.cn/89f183a092e24338bad507027ab16dd8.png)
发布订阅模式的实现原理
Redis通过PUBLISH、SUBSCRIBE和PSUBSCRIBE等命令实现了发布和订阅功能。
通过SUBSCRIBE命令订阅某个频道后,redis-server里面维护了一个字典,字典的键就是一个个channel,而字典的值则是一个链表,链表中保存了所有订阅这个channel的客户端。SUBSCRIBE命令的关键,就是将客户端添加到指定channel的订阅链表中。
通过PUBLISH命令向订阅者发送信息,redis-server会使用给定的频道作为键,在他所维护的channel字典中查找记录订阅该频道的所有客户端的链表,通过遍历这个链表,来将信息发布给所有的订阅者
Pub/Sub 底层存储结构
订阅 Channel
在 Redis 的底层结构中,客户端和频道的订阅关系是通过一个字典加链表的结构保存的,形式如下
![[图片]](https://img-blog.csdnimg.cn/706f2f5b803c4679bf1a9ccd23900100.png)
使用场景
- 实时消息系统
- 实时聊天(群聊)
- 订阅,关注系统
发布订阅系统在我们日常的工作中经常会使用到,这种场景大部分情况我们都是使用消息队列,常用的消息队列有 Kafka,RocketMQ,RabbitMQ,每一种消息队列都有其特性,很多时候我们可能不需要独立部署相应的消息队列,只是简单的使用,而且数据量也不会太大,这种情况下,我们就可以使用 Redis 的 Pub/Sub 模型。
主从复制
指将一台redis服务器上的数据,复制到其他redis服务器上。前者称为主节点(Master),后者称为从节点(Slave)。数据的复制是单向的,只能由主节点到从节点。Master以写为主,Slave以读为主。
默认情况下,每台Redis服务器都是主节点。
主节点可以有多个从节点,一个从节点只能有一个主节点。
主从复制的作用
- 数据冗余(备份)
- 故障恢复
- 负载均衡
- 高可用(集群)基石:主从复制是哨兵和集群能够实施的基础。
这个模式可以保证多台服务器的数据一致性,且主从服务器之间采用的是「读写分离」的方式。
主服务器可以进行读写操作,当发生写操作时自动将写操作同步给从服务器,而从服务器一般是只读,并接受主服务器同步过来写操作命令,然后执行这条命令。
![[图片]](https://img-blog.csdnimg.cn/98f02ddaeac74733aabb27a5e632a258.png)
也就是说,所有的数据修改只在主服务器上进行,然后将最新的数据同步给从服务器,这样就使得主从服务器的数据是一致的。
主从复制共有三种模式:全量复制、基于长连接的命令传播、增量复制。
主从服务器第一次同步的时候,就是采用全量复制,此时主服务器会两个耗时的地方,分别是生成 RDB 文件和传输 RDB 文件。从节点发送一个命令,与主节点建立连接。主节点将生成的rdb文件发送给从节点,从节点丢弃掉自己旧的rdb文件加载新的rdb文件读取数据。在此期间主节点将新的写命令放到缓冲区中,从节点rdb文件加载完成后,主节点将缓冲区中新的命令发给从节点,完成主从节点数据一致。
第一次同步完成后,主从服务器都会维护着一个长连接,主服务器在接收到写操作命令后,就会通过这个连接将写命令传播给从服务器,来保证主从服务器的数据一致性。
如果遇到网络断开,增量复制就可以上场了,也就是只会把网络断开期间主服务器接收到的写操作命令,同步给从服务器。
哨兵模式
哨兵(Sentinel)机制,它的作用是实现主从节点故障转移。它会监测主节点是否存活,如果发现主节点挂了,它就会选举一个从节点切换为主节点,并且把新主节点的相关信息通知给从节点和客户端。
为什么要有哨兵机制?
在 Redis 的主从架构中,由于主从模式是读写分离的,如果主节点(master)挂了,那么将没有主节点来服务客户端的写操作请求,也没有主节点给从节点(slave)进行数据同步了。
这时如果要恢复服务的话,需要人工介入,选择一个「从节点」切换为「主节点」,然后让其他从节点指向新的主节点,同时还需要通知上游那些连接 Redis 主节点的客户端,将其配置中的主节点 IP 地址更新为「新主节点」的 IP 地址。
手动操作太繁琐了,希望能有一个机制,比如要是有一个节点能监控「主节点」的状态。当发现主节点挂了,它自动将一个「从节点」切换为「主节点」的话,那么可以节省我们很多事情。
哨兵机制是如何工作的?
哨兵其实是一个运行在特殊模式下的 Redis 进程,所以它也是一个节点。从“哨兵”这个名字也可以看得出来,它相当于是“观察者节点”,观察的对象是主从节点。在它观察到有异常的状况下,会做出一些“动作”,来修复异常状态。
哨兵节点主要负责三件事情:监控、选主、通知。
哨兵节点通过 Redis 的发布者/订阅者机制,哨兵之间可以相互感知,相互连接,然后组成哨兵集群,同时哨兵又通过 INFO 命令,在主节点里获得了所有从节点连接信息,于是就能和从节点建立连接,并进行监控了。
1、第一轮投票:判断主节点下线
当哨兵集群中的某个哨兵判定主节点下线(主观下线)后,就会向其他哨兵发起命令,其他哨兵收到这个命令后,就会根据自身和主节点的网络状况,做出赞成投票或者拒绝投票的响应。
当这个哨兵的赞同票数达到哨兵配置文件中的 quorum 配置项设定的值后,这时主节点就会被该哨兵标记为「客观下线」。
2、第二轮投票:选出哨兵 leader
某个哨兵判定主节点客观下线后,该哨兵就会发起投票,告诉其他哨兵,它想成为 leader,想成为 leader 的哨兵节点,要满足两个条件:
- 第一,拿到半数以上的赞成票;
- 第二,拿到的票数同时还需要大于等于哨兵配置文件中的 quorum 值。
3、由哨兵 leader 进行主从故障转移
选举出了哨兵 leader 后,就可以进行主从故障转移的过程了。该操作包含以下四个步骤: - 第一步:在已下线主节点(旧主节点)属下的所有「从节点」里面,挑选出一个从节点,并将其转换为主节点,选择的规则:
- 过滤掉已经离线的从节点;
- 过滤掉历史网络连接状态不好的从节点;
- 将剩下的从节点,进行三轮考察:优先级、复制进度、ID 号。在每一轮考察过程中,如果找到了一个胜出的从节点,就将其作为新主节点。
- 第二步:让已下线主节点属下的所有「从节点」修改复制目标,修改为复制「新主节点」;
- 第三步:将新主节点的 IP 地址和信息,通过「发布者/订阅者机制」通知给客户端;
- 第四步:继续监视旧主节点,当这个旧主节点重新上线时,将它设置为新主节点的从节点















 21万+
21万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









