







一、深度学习概述
大数据造就了人工智能
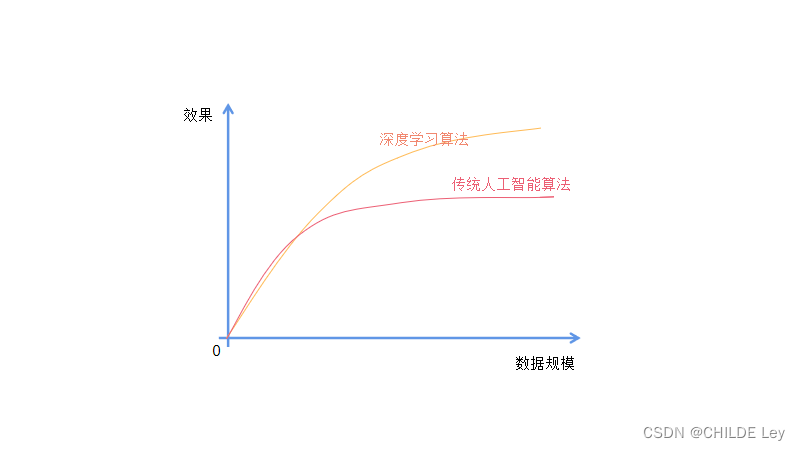
(一)常规应用场景
图像分类(计算机视觉核心任务)
图片表示为数组:
300*100*3,长*宽*3
3个三色通道,300*100个像素点
像素点取值范围(0,255)
值越大,亮度越高
挑战
照射角度
光照强度
形状改变
部分遮蔽
背景混入
无人驾驶
(二)常规套路
- 收集数据
- 训练分类器
- 测试评估
(三)KNN算法
按照距离近的k个样本的类别的概率判断该样本的分类
流程:
- 计算数据集中所有点到当前点的距离
- 按距离一次排序
- 去当前点距离最小的k个点
- 确定前k个点所在类别出现的概率
- 返回前k个点出现频率最高的类别作为当前点的预测分类
问题:训练时间复杂度为0,分类加时间复杂度为O(n)
经典数据集:CIFAR-10
(四)超参数
1. 范数
曼哈顿距离——L1范数
欧几里得距离——L2范数
2.如何找到最好的参数——交叉验证
测试集只能最终使用。
对训练集进一步切分得到验证集,用于调节参数
二、先导知识
权重系数存在的意义:
减少背景对对图片判别的影响
(一)线性分类
每个类别的得分:f(x,w)=Wx (+ b)
案例:
32323的图片=》(拉伸为30721的列向量) * (103072的权重系数)=》10个类别的得分
权重系数的正负反映该特征对类别判断的贡献
(二)损失函数
SVM
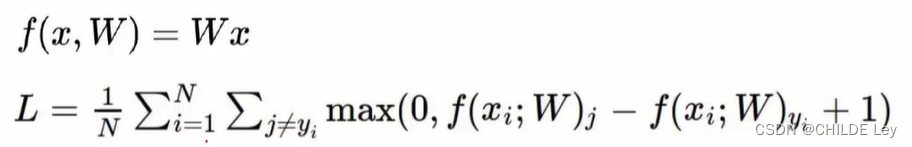
案例:

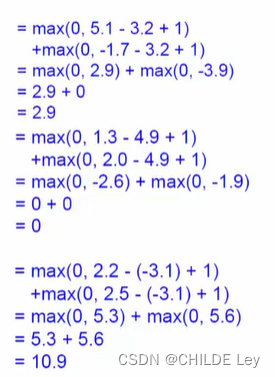
损失值越大,分类效果越不好
小于0则认为没有损失
区分度不大
正则化惩罚项
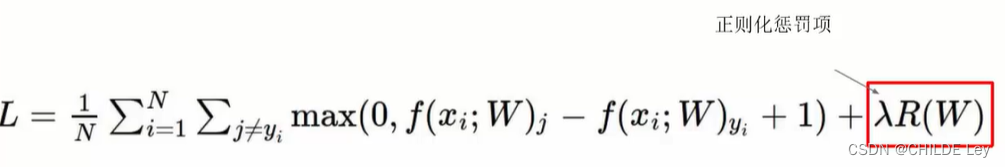
惩罚权重系数,惩罚项值越大,效果越不好
softmax
Sigmoid=1/(1+e^-x)
求出样本属于某类别的概率
softmax的输出是归一化的分类概率
先映射,再归一化,
损失函数: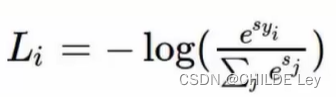
错的类别接近0,对的类别接近1——log函数作为损失函数
损失值永远存在
(三)最优化问题——反向传播
链式求导
三、神经网络
(一)整体架构
输入层、隐藏层、输出层组成网络
中间值维权重的计算结果
每一层相当于矩阵
参数
w1、w2、w3大小
(二)激活函数
Sigmoid=1/(1+e^-x)
存在梯度消失现象,所以淘汰
ReLU max(0,x)
解决梯度消失问题
(三)实例展示
神经元个数越多,拟合效果越好,可能过拟合
(四)过拟合解决方案
正则化惩罚项,防止过拟合
泛化能力决定神经网络的能力
神经元越多,越能表达复杂的模型
- 数据预处理,范围(0,255)
- 权重初始化,非零值。随机取值or高斯取值法
- b零值初始化
解决过拟合——DROP-OUT
训练神经网络时,每次迭代,随机选择部分神经元更新
减小计算量,防止过拟合















 1295
1295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









