






1、什么是计算机集群
计算机集群是由多台独立的计算机(节点)通过网络连接在一起,以共同完成任务的一种计算机系统结构。集群系统旨在提高性能、可用性和可扩展性。以下是计算机集群的一般结构和组成要素:
-
节点(Nodes): 集群中的每台独立计算机被称为节点。这些节点可以是普通的计算机服务器,具备处理能力、内存和存储等资源。
-
互联网络: 节点之间通过高速网络连接,通常使用以太网或者其他专用高性能网络。这使得节点能够相互通信和协同工作。
-
集群管理软件: 集群中的节点由集群管理软件进行管理和协调。这些软件负责分配任务、监控节点的状态、处理故障等。一些流行的集群管理软件包括Slurm、OpenStack、Kubernetes、Apache Hadoop等。
-
负载均衡器: 负载均衡器用于平衡集群中各个节点的负载,确保任务被均匀地分配到不同的节点上,从而提高整个集群的性能和效率。
-
存储系统: 集群通常需要共享存储,以便节点之间能够访问相同的数据。这可以通过网络附加存储(Network Attached Storage,NAS)或存储区域网络(Storage Area Network,SAN)实现。
-
冗余和容错机制: 为了提高可用性,集群通常包含冗余的组件和容错机制。这可以包括节点冗余、电源冗余、网络冗余等,以防止单点故障对整个集群的影响。
-
并行计算和分布式系统支持: 集群设计用于支持并行计算和分布式系统。任务可以分解为小的子任务,由不同节点并行处理,从而加速整个计算过程。
-
扩展性: 集群结构应该具有良好的可扩展性,允许根据需求添加新的节点,以满足不断增长的计算需求。
简单来说,计算机集群就是一个多台高性能计算机(2*24Core 3.0GHz Intel Xeon Gold 6248R,512GB)通过高速网络连接组成的机房。如下是一个名为白云一号的集群,它是由48个拥有2个英特尔至强Gold 6230R CPU、256G内存的计算机,2个拥有4个英特尔至强Gold 6248、1024G内存的计算机组成的集群。

2、什么是Slurm
在公共集群中使用SLURM作业调度系统进行任务的调度和管理。SLURM (Simple Linux Utility for Resource Management)是一种可用于大型计算节点集群的高度可伸缩和容错的集群管理器和作业调度系统,被世界范围内的超级计算机和计算集群广泛采用。在一个典型的集群环境中,Slurm的组件分为两部分:控制节点(Head Node)和计算节点(Compute Node)。
控制节点:
这是Slurm集群的主节点,负责整个集群的管理和协调。在控制节点上,需要安装Slurm的控制节点组件,包括slurmctld(Slurm Controller Daemon)和slurmd(Slurm Daemon)。slurmctld负责协调作业调度和资源管理,而slurmd则运行在每个计算节点上,负责接受和执行由控制节点分配的作业。
计算节点:
这是集群中实际执行计算任务的节点。在每个计算节点上,需要安装slurmd守护程序。这个守护程序通过与控制节点通信,接收作业分配和相应的任务信息,然后启动、监控和报告任务的执行。
一般来说,普通用户主要通过控制节点(Head Node)与Slurm集群进行交互。控制节点上通常安装有Slurm的客户端工具,用户可以使用这些工具提交作业、查询作业状态、获取有关集群资源的信息等。
在Slurm集群中,计算节点上的直接访问通常会受到限制,因为这些节点主要负责执行计算任务而不是用户交互。用户通过控制节点向Slurm系统提交任务,并通过控制节点的命令行界面或其他管理工具与集群进行交互。

3、Slurm常用命令
3.1、sinfo 查看节点与分区状态
$ sinfo PARTITION AVAIL TIMELIMIT NODES STATE NODELIST cpu* up infinite 1 down* n144 cpu* up infinite 168 alloc n[3-143,145-171]
| 关键词 | 含义 |
|
| 分区名,对节点的逻辑分组。不同的分区会设置不同权限、资源限制等。 |
|
| 可用状态: |
|
| 该分区的作业最大运行时长限制, |
|
| 节点数量 |
|
| 状态: |
|
| 节点列表 |
3.2、squeue 查看队列状态
$ squeue JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 8628 cpu vasp_cpu yangx17 PD 0:00 2 (QOSMaxNodePerUserLimit) 8629 cpu vasp_cpu yangx17 PD 0:00 2 (QOSMaxNodePerUserLimit) 8630 cpu vasp_cpu yangx17 PD 0:00 2 (QOSMaxNodePerUserLimit) 8636 cpu vasp_cpu mab2019 PD 0:00 4 (Resources) 8637 cpu vasp lizhenhu PD 0:00 1 (Priority) 5042 cpu HICE_WAC xum17 R 16-22:28:14 4 n[114-117] 5044 cpu LICE_WAC xum17 R 16-22:21:58 4 n[29,41-43] 5519 cpu c zhaosy16 R 14-22:00:21 5 n[93-95,165-166] 5783 cpu c liangt20 R 13-20:54:50 5 n[30-32,156-157]squeue -u ${USER} # 查看指定用户的作业
| 关键词 | 含义 |
|
| 作业的id号,每个成功提交的任务都会有唯一的id |
|
| 分区名 |
|
| 作业名称,默认为提交脚本的名称 |
|
| 用户名,提交该作业的用户名 |
|
| 作业状态: |
|
| 作业运行时间 |
|
| 作业占节点数 |
|
| 作业所占节点列表,如果是排队状态的任务,则会给出排队原因 |
3.3、scancel 取消作业
scancel <JOBID>
3.4、sacct 查看历史作业信息
此命令提供有关已提交作业的有用信息。
Column Description
JobID 作业编号
JobName 任务名称
Partition 它正在运行或排队等待 SLURM 队列的哪个分区
Account 它在哪个帐户/组上运行
AllocCPUS 分配/请求的 CPU 数量
State ExitCode 工作状态或退出代码
3.5、salloc 分配资源
集群的计算节点默认不允许用户直接登录,对需要交互式处理的程序,在登录到集群后,使用salloc命令分配节点,然后再ssh到分配的节点上进行处理:
用法: salloc [选项...] [命令 [参数...]]
并行运行选项:
-A, --account=name 将任务计费到指定账户
-b, --begin=time 推迟任务直到 HH:MM MM/DD/YY
--bell 当任务分配时响铃终端
--bb=<spec> 爆发缓冲区规格
--bbf=<file_name> 爆发缓冲区规格文件
-c, --cpus-per-task=ncpus 每个任务需要的 CPU 核心数量
--comment=name 任意注释
--cpu-freq=min[-max[:gov]] 请求的 CPU 频率(和调度器)
--delay-boot=mins 推迟引导以获得所需的节点特性
-d, --dependency=type:jobid 推迟任务,直到 jobid 上的条件满足
--deadline=time 如果在此截止时间之前没有结束,则移除任务(start > (deadline - time[-min]))
-D, --chdir=path 更改工作目录
--get-user-env 由 Moab 使用,请参见 srun 手册。
--gid=group_id 以指定的组 ID 运行任务(仅限 root 用户)
--gres=list 所需的通用资源
--gres-flags=opts 与 GRES 管理相关的标志
-H, --hold 以保持状态提交任务
-I, --immediate[=secs] 如果资源在“secs”内不可用,则退出
-J, --job-name=jobname 任务的名称
-k, --no-kill 在节点故障时不要终止任务
-K, --kill-command[=signal] 发送终止任务的信号
-L, --licenses=names 所需的许可证,逗号分隔
-M, --clusters=names 逗号分隔的要发出命令的群集列表。默认为当前群集。'all' 的名称将在所有群集上运行。注意:SlurmDBD 必须启动。
-m, --distribution=type 进程到节点的分布方法(类型 = block|cyclic|arbitrary)
--mail-type=type 在状态更改时通知:BEGIN、END、FAIL 或 ALL
--mail-user=user 为作业状态更改发送电子邮件通知的用户
--mcs-label=mcs 如果使用 mcs 插件 mcs/group,则为 mcs 标签
-n, --ntasks=N 所需的处理器数量
--nice[=value] 按照 value 减小调度优先级
--no-bell 不要响铃终端
--ntasks-per-node=n 在每个节点上调用的任务数量
-N, --nodes=N 要运行的节点数(N = min[-max])
-O, --overcommit 超额分配资源
--power=flags 电源管理选项
--priority=value 将作业的优先级设置为 value
--profile=value 启用 acct_gather_profile 以获取详细数据,value 是 all 或 none 或 energy、lustre、network 或 task 的任意组合
-p, --partition=partition 请求的分区
-q, --qos=qos 服务质量
-Q, --quiet 安静模式(抑制信息消息)
--reboot 在启动作业之前重新启动计算节点
-s, --oversubscribe 与其他作业一起超额分配资源
--signal=[B:]num[@time] 在 time 秒内发送信号限时
--spread-job 将作业分布在尽可能多的节点上
--switches=max-switches{@max-time-to-wait} 最佳交换机和最大等待时间的最佳选择
-S, --core-spec=cores 保留核心的数量
--thread-spec=threads 保留线程的数量
-t, --time=minutes 时间限制
--time-min=minutes 最小时间限制(如果不同)
--uid=user_id 以指定的用户 ID 运行任务(仅限 root 用户)
--use-min-nodes 如果给出节点计数的范
示例:
示例1、
salloc -p free -n 16
# 在名为free的分区申请16核CPU资源
示例2、
salloc -p free -comment=myProject
# 在free分区中请一个cpu计算节点,使用my Project项目账户扣费
示例3、
salloc -p fat -N1 -n6 -q low -t 2:00:00
# 在名为fat的分区指定分配一个节点,申请6核CPU资源
#
-q选项指定队列#
low,表示将任务提交到名为low的队列中#
-t选项指定任务的时间限制,这里是2:00:00,表示任务将在 2 小时内运行示例4、
salloc -p GPU -N1 -n6 --gres=gpu:1 -q low -t 24:00:00
# 在名为GPU的分区指定分配一个节点,申请6核CPU资源
#
--gres选项指定通用资源,这里是gpu:1,表示任务需要使用 1 个 GPU示例5、
salloc -p fat -N2 --ntasks-per-node=12 -q low -t 2:00:00
# 在名为fat的分区指定分配两个节点
# 这里申请两个节点,每个节点12个进程,每个进程一个核心
计算完成后,使用exit命令推出节点,注意需要exit两次,第一次exit是从计算节点退出到登录节点,第二次exit是释放所申请的资源。
3.6、sbatch 提交批处理作业
可以通过将程序执行命令放入作业提交脚本,并通过sbatch命令作业提交的方式在集群中进行计算。
常见提交作业参数参考:
| 参数 | 说明 |
|
| 设定作业名称 |
|
| 设定作业需要的节点数。如果没有指定,默认分配足够的节点来满足 |
|
| 设定每个节点上的任务数。要和``–nodes=<n>``同时配合使用。 |
|
| 设定最多启动的任务数。 |
|
| 设定每个任务所需要的CPU核数。如果没有指定,默认为每个任务分配一个CPU核。一般运行OpenMP等多线程程序时需要,普通MPI程序不需要。 |
|
| 指定从哪个项目扣费,注意要将 |
Slurm更多声明参数如下
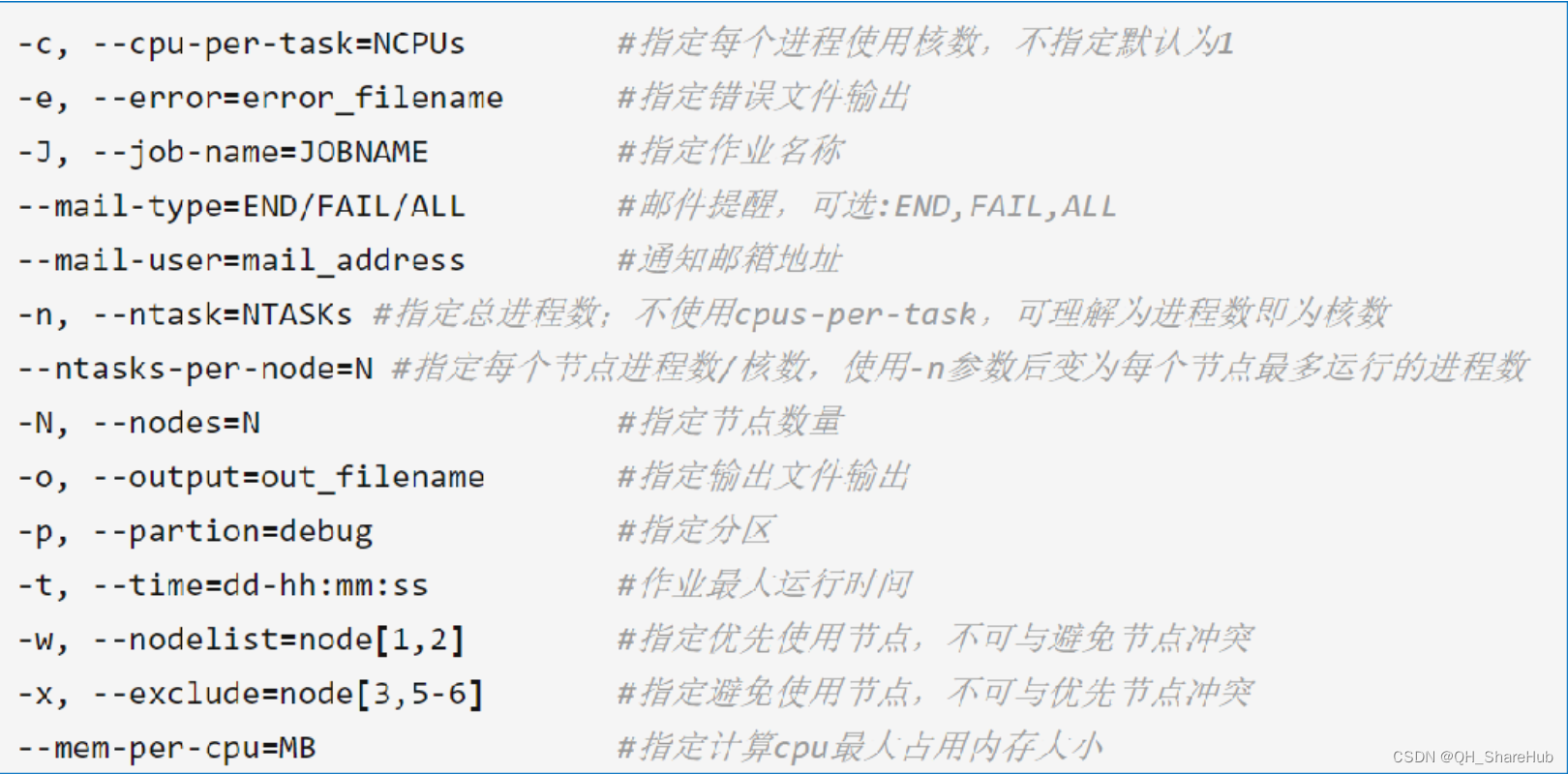
Slurm脚本实例:Job.sh
###SBATCH参数以#开头,非注释! ### 表示这是一个bash脚本,名为joob.sh #!/bin/bash ### 设置该作业的作业名(必选) #SBATCH --job-name=JOBNAME ### 设置分区名(必选) #SBATCH --partition=free ### 指定该作业需要2个节点数(必选) #SBATCH --nodes=2 ### 每个节点所运行的进程数为1(可选) #SBATCH --ntasks-per-node=1 ### 每个任务进程需要的cpu核数,针对多线程任务,默认1(可选) #SBATCH --cpus-per-task=12 ### 作业最大的运行时间,超过时间后作业资源会被SLURM回收 # 时间格式:天-小时:分钟:秒 #SBATCH --time=2:00:00 ### 指定从哪个项目扣费。如果没有这条参数,则从个人账户扣费 #SBATCH --comment=TestProject ### 程序的执行命令 Rscript ./mytest.R
Tips:
1、以
#SBATCH开头的命令表示这些是需要slurm系统处理的参数。2、通过sbatch job.sh命令提交批处理作业,系统会返回作业编号(JOBID)
3、通过squeue(或者squeue --user=$USER仅查看自己作业)查看作业运行状态
4、作业执行完成后,默认会把程序输出文件放到同目录下的slurm-JOBID.out文件中
3.7、scontrol 系统控制
用于与 Slurm 控制守护进程(slurmctld)进行交互,以及查询和管理集群的状态。
# 查询集群状态
scontrol show nodes# 查询作业信息
scontrol show jobs# 暂停/恢复节点
scontrol update nodename=node01 state=drain reason="maintenance"
scontrol update nodename=node01 state=resume# 取消作业
scontrol cancel job_id# 修改作业属性
scontrol update jobid=12345 priority=100# 更改节点分区
scontrol update nodename=node01 partition=high-priority# 查询 QOS 信息
scontrol show qos
3.8、srun 执行作业
# 1. 启动并行程序,使用2个节点和4个任务
srun -N2 -n4 ./my_parallel_program# 2. 在指定分区中运行4个任务,每个节点上运行2个任务
srun -p partition_name -n4 --ntasks-per-node=2 ./my_program arg1 arg2# 3. 指定CPU核心数和内存
srun --cpus-per-task=2 --mem=4G ./my_program# 4. 指定GPU数量
srun --gres=gpu:2 ./my_gpu_program# 5. 依赖关系,仅当作业ID为12345的作业成功完成后,才运行当前任务
srun --dependency=afterok:12345 ./my_program# 6. 使用MPI并行编程时,通过指定配置文件来启动多个并行任务
srun --multi-prog my_mpi_config_file# 7. 启动一个交互式Bash shell,分配1个节点和1个任务
srun -N1 -n1 -p interactive --pty bash# 8. 分配1个节点和1个任务后,执行特定的命令
srun -N1 -n1 my_command
详细参考:
快速入门:Slurm资源管理与作业调度系统_slurm sbatch-CSDN博客
Slurm 作业调度系统使用指南 - 知乎 (zhihu.com)
















 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











