







编号:2461602
项目+LW(说明书)+任务书(开题报告)
完整项目联系方式在文章最下面
关键技术
数据分析 - Hadoop + HIve
数据爬虫 - Selenium
数据清洗 - Pandas
数据库 - MySQL
后端 - Python | Flask
前端 - HTML | JS | CSS
可视化 - Echarts
部分内容展示
3 数据的采集
3.1采集页面分析
去哪儿网作为国内领先的旅游服务平台,提供了全国各地的丰富旅游景点信息。景点列表页面整洁明了,用户可依据个人喜好筛选和浏览。每个景点条目均包含景点名称、地理位置、评分、用户评论数及起始价格等关键信息,如图3.1所示。

图3.1 去哪网景区列表页面
网页结构分析是爬虫设计的关键步骤。通过审查元素功能,可以识别出用于标识景点信息的HTML元素,例如景点名称通过<h3>标签类名定义,评分和评论数量则包含在<span>或<div>等元素内。这些标识符在后续的数据采集中将被用于定位和提取所需数据,如图3.2所示。

图3.2 去哪儿列表网页结构分析
景区详情页面为用户提供了更为详细的信息,如用户评价、票价变动、开放时间等。这些数据对于分析用户偏好和旅游景点的热度有着不可或缺的作用如图3.3所示。
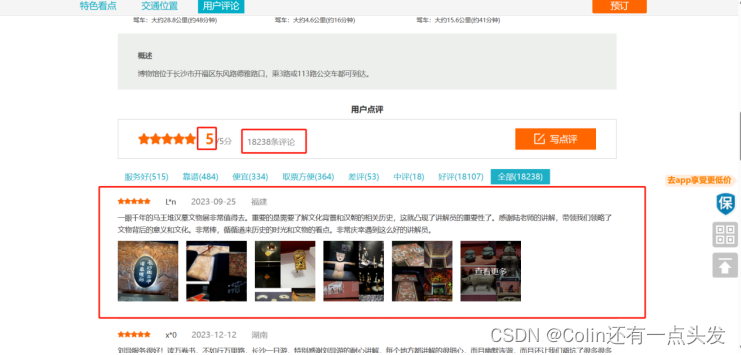
图3.3 景区详情页面
详细页面的结构分析进一步明确了如何提取用户评论和具体评分。例如,评论总数可能通过某个特定的类名聚合在一起,而详细的用户评论则分布在有序或无序列表的列表项(<span>)中。
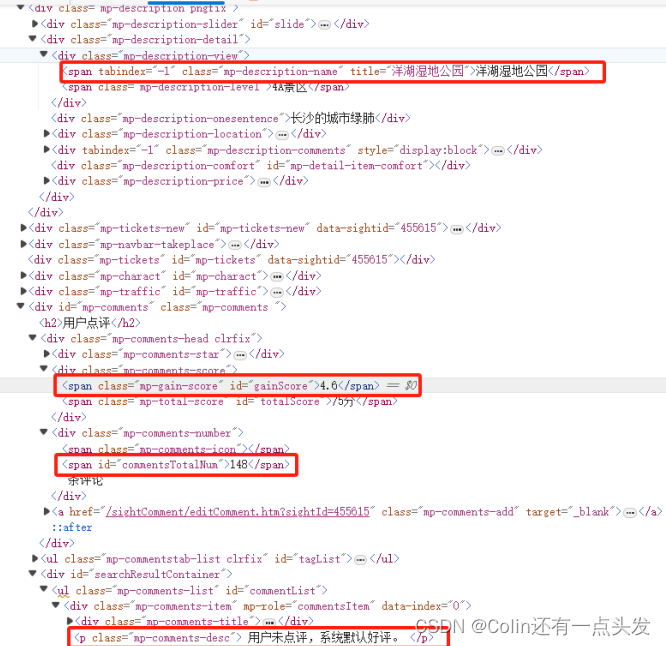
图3.4 景区详情网页结构分析
3.2 字段分析
在进行数据采集之前,通过对去哪儿网景点列表和景区详情页面的详细分析,我们可以确定需要爬取的数据字段。数据字段的确定对于后续数据的存储、查询以及分析至关重要。
通过网页数据分析,发现去哪儿网的页面结构规范,提供了丰富的信息,这使得自动化数据采集成为可能。在景点列表页面中,每个景点的信息均被整齐地组织在一定的HTML结构中,而景区详情页面则提供了深入的单个景点信息,包括用户的具体评价和评分。
在景点列表页面的数据字段分析中,我们识别出以下关键字段:
表3-1 景点列表字段
| 字段名称 | 描述 |
| title | 景点的标题或名称 |
| img | 景点的图片链接 |
| area | 景点所在地区或位置 |
| link | 景点详情页面的链接 |
| price | 景点的参考价格 |
| aaaa | 景区的官方等级评定 |
| jianjie | 景点的简要介绍或描述 |
表3-2 景点详情字段
| 字段名称 | 描述 |
| title | 景点的标题或名称 |
| score | 用户对景点的评分 |
| comments_num | 景点的用户评论数量 |
| detail | 用户对景点的详细评论 |
3.2 采集关键代码
在数据采集过程中,我们使用了Selenium WebDriver来自动化与旅游网站的浏览器交互,以便从中爬取数据。通过配置ChromeOptions和WebDriver,确保了忽略SSL证书错误,并且使浏览器的自动化操作对网站来说不可检测。
代码的第一部分通过循环遍历旅游网站的每个页面,收集列表中每个景点的数据。对于每个景点,提取以下详细信息:
- 图片源地址(img标签的src属性)
- 标题
- 地址
- 景点详细页面的链接(a标签的href属性)
- 价格
- 景点等级(例如4A, 5A)
- 简介
这些数据随后被写入data1.csv。

图3.5 景点爬取
option = ChromeOptions()
option.add_argument('--ignore-certificate-errors')
option.add_argument('--ignore-ssl-errors')
option.add_experimental_option('excludeSwitches', ['enable-automation', 'enable-logging'])
driver = webdriver.Chrome(options=option)
driver.implicitly_wait(10) # 页面加载最长等待时间
page = 1 # 设置页数
time.sleep(1)
while page < 44:
url = "https://piao.qunar.com/ticket/list.htm?keyword=%E9%95%BF%E6%B2%99®ion=null&from=mps_search_suggest&page={}".format(page)
driver.get(url)
print("当前页数:", page)
driver.implicitly_wait(10) # 页面加载数据10秒
divs = driver.find_elements(By.XPATH,"//body/div[3]/div[2]/div[1]/div[3]/div[1]/div")
print(divs)
for div in divs:
try:
img = div.find_element(By.XPATH, "./div/div[1]/div/a/img").get_attribute('src')
title = div.find_element(By.XPATH, './div/div[2]/h3/a').text
area = div.find_element(By.XPATH, './div/div[2]/div/p/span').text
link = div.find_element(By.XPATH, './div/div[2]/h3/a').get_attribute('href')
try:
price = div.find_element(By.XPATH, './div/div[3]/table/tbody/tr[1]/td/span/em').text
except:
price = "无"
try:
aaaa = div.find_element(By.XPATH, './div/div[2]/div/div[1]/span[1]').text
except:
aaaa = "无"
try:
jianjie = div.find_element(By.XPATH, './div/div[2]/div/div[2]').text
except:
jianjie = "无"
with open("data1.csv", "a+", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
writer.writerow([title,img,area,link,price,aaaa,jianjie])
except Exception as e:
print("获取信息失败:", e)
page += 1
time.sleep(5)
driver.close() # 关闭Chrome 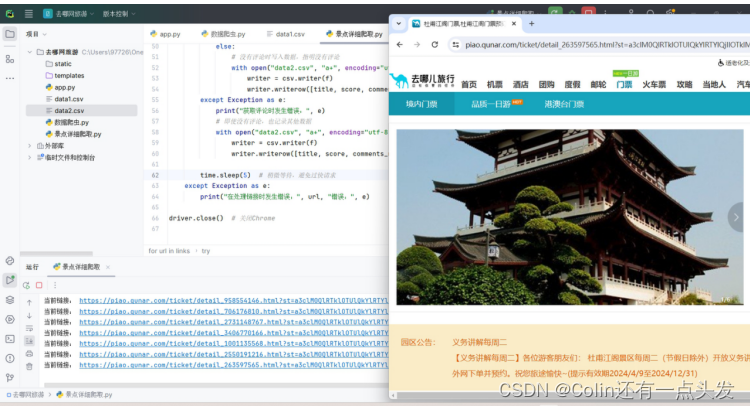
图3.6 景区详情爬取
第二部分的代码读取data1.csv中的链接,然后从每个景点的详细页面中爬取信息。这里,代码提取了标题、评分、评论数以及评论的实际文本。如果没有评论,它会记录“暂无评论”。所有这些信息都存储在data2.csv。
option = ChromeOptions()
option.add_argument('--ignore-certificate-errors')
option.add_argument('--ignore-ssl-errors')
option.add_experimental_option('excludeSwitches', ['enable-automation', 'enable-logging'])
driver = webdriver.Chrome(options=option)
driver.implicitly_wait(10) # 页面加载最长等待时间
links_df = pd.read_csv('data1.csv')
links = links_df['link'].tolist()
with open("data2.csv", "w", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
writer.writerow(['title', 'score', 'comments_num', 'detail'])
for url in links:
driver.get(url)
print("当前链接:", url)
try:
title = driver.find_element(By.XPATH, '//span[@class="mp-description-name"]').text
score = driver.find_element(By.XPATH, '//*[@id="gainScore"]').text
try:
comments_num = driver.find_element(By.XPATH, '//*[@class="mp-comments-number"]').text
except:
comments_num = "暂无评论数"
try:
comments = driver.find_elements(By.XPATH, '//*[@id="commentList"]/div[@mp-role="commentsItem"]')
if comments:
for comment in comments:
detail = comment.text # 获取评论文本
with open("data2.csv", "a+", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
writer.writerow([title, score, comments_num, detail])
else:
with open("data2.csv", "a+", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
writer.writerow([title, score, comments_num, "暂无评论"])
except Exception as e:
print("获取评论时发生错误:", e)
with open("data2.csv", "a+", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
writer.writerow([title, score, comments_num, "暂无评论"])
time.sleep(5) # 稍微等待,避免过快请求
except Exception as e:
print("在处理链接时发生错误:", url, "错误:", e)
driver.close() # 关闭Chrome 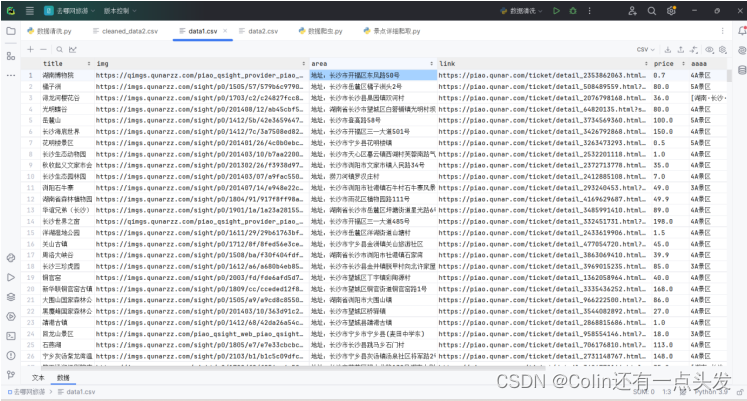
图3.7 数据展示
图3.7数据展示部分将展示带有采集数据的CSV文件截图,提供了一个清晰结构化的数据视图,这些数据准备进一步处理或分析。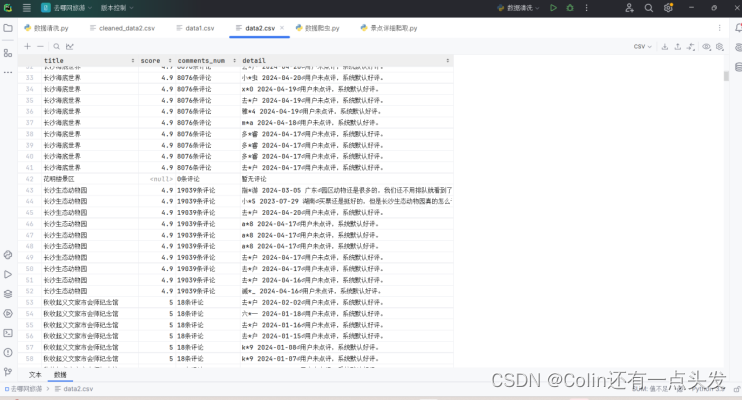
图3.8展示了data2.csv的内容,展示了评论的详细信息,这对于情感分析或进一步的定性研究非常有用。
部分运行截图
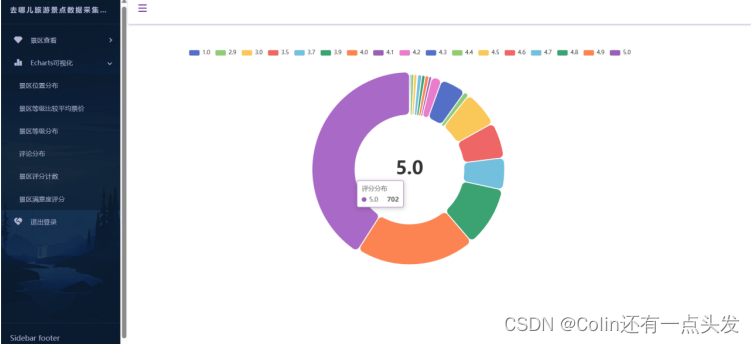
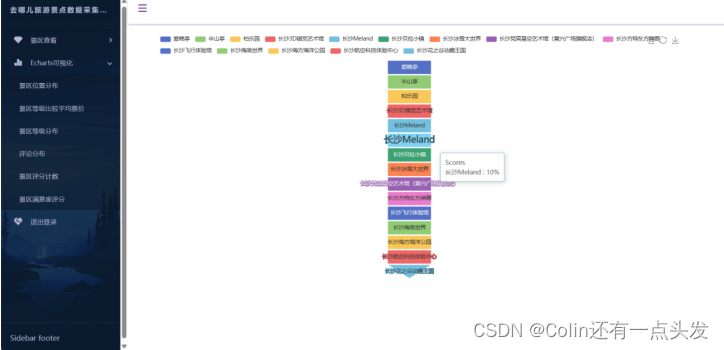
数据分析
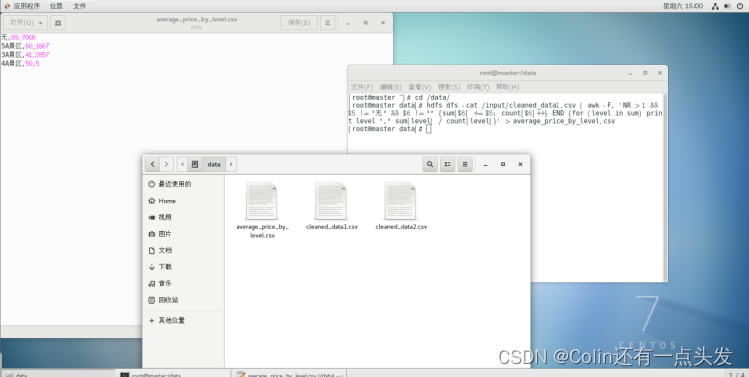
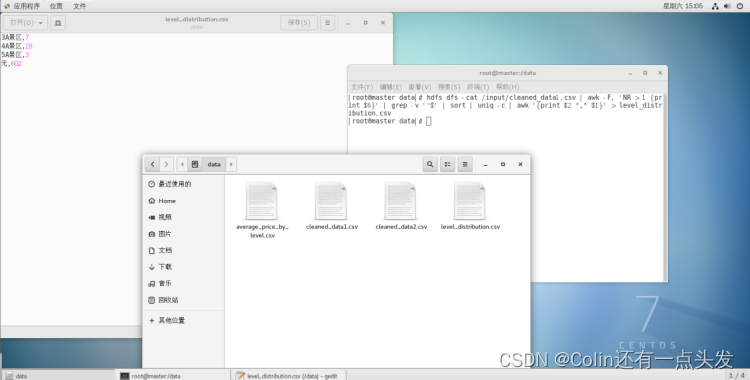
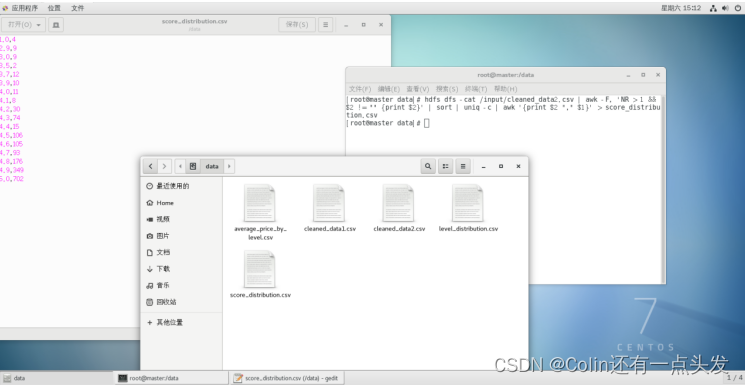
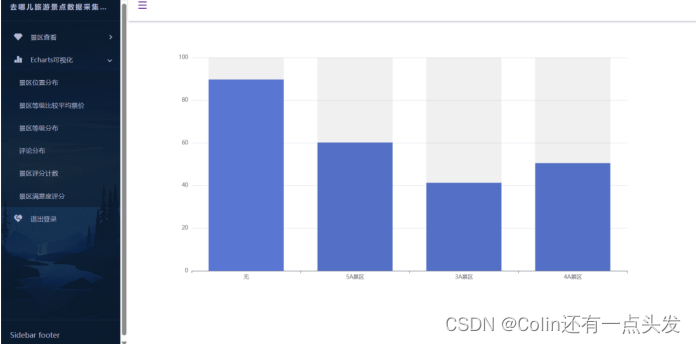
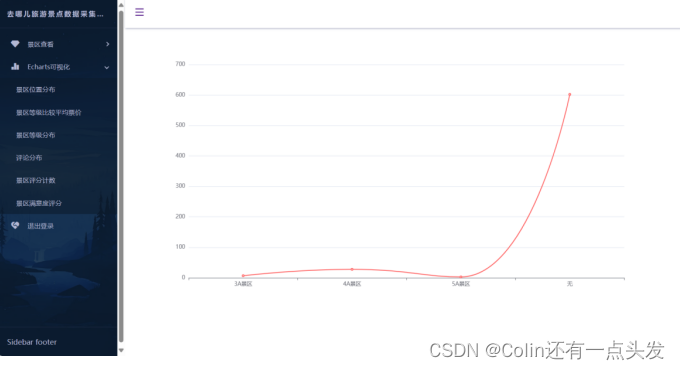
数据可视化


在当今的数字化时代,信息技术和大数据已成为推动现代服务业发展的关键因素。旅游业作为服务业的重要组成部分,正面临着从传统模式向现代智能服务转变的挑战与机遇。消费者越来越依赖于互联网来计划和预订他们的旅行体验,他们希望通过点击鼠标或触摸屏幕,即可获取全面、实时的旅游信息。因此,旅游信息的数字化展示和实时更新成为了提高游客满意度、吸引更多游客的重要途径。
本项目旨在通过技术手段,特别是爬虫技术,系统地收集和分析旅游网站上的数据。这些数据不仅包括景点的基本信息和游客的评价,还包括票价、人流量等经营分析数据。通过对这些数据的深入挖掘,我们可以为旅游经营者提供决策支持,为游客提供个性化的旅游推荐。
V - WeiDaPang_T
Q - 977266623
















 2667
2667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











