




一、背景意义
随着人们对情绪识别技术的需求日益增长,面部情绪识别作为一种重要的应用领域,已经在心理健康、教育、安防和人机交互等多个场景中展现出广泛的应用潜力。情绪识别技术能够帮助机器理解人类情感,改善人机交互体验,提高系统的智能化水平。在视频监控、客户服务和社交机器人等领域,实时识别和分析用户情绪,可以为相关决策提供有力支持。因此,构建高效且准确的面部情绪识别系统具有重要的理论研究和实际应用价值。
二、数据集
2.1数据采集
数据采集是制作人脸情绪识别检测数据集的第一步,旨在收集足够多样化的图像样本,以确保数据集的全面性和代表性。此过程的主要步骤包括:
-
实地拍摄:在不同的环境中对被试进行拍摄,记录多种情绪状态下的面部表情。拍摄时应确保获取不同性别、年龄段和种族的人脸图像,以增加数据集的多样性。每张图像应清晰展现情绪特征,如愤怒的紧绷眉头、快乐的微笑等。
-
利用公开数据集:查找并下载已有的公开人脸情绪识别数据集,如FER2013、CK+或AffectNet等。通过这些数据集,能够快速获得大量标注好的情绪图像,便于后续处理。
-
网络资源收集:通过社交媒体、图片分享网站或视频平台收集情绪表现的图像。可使用网络爬虫工具抓取包含人脸情绪的图像,但需遵循版权法律,确保数据的合法性。
-
数据存储:将收集到的图像按类别进行分类存储,确保每个情绪类别(如愤怒、厌恶、恐惧、快乐、中性、悲伤和惊讶)都能清晰区分,便于后续步骤中的清洗和标注。
数据清洗数据清洗的目的是提高数据集的质量,去除不符合标准的图像。清洗过程通常包括以下几个环节:
-
去重:运用图像哈希算法或计算机视觉算法检查数据集中是否存在重复图像,确保每张图像都是唯一的。
-
质量检查:对所有图像进行质量评估,剔除模糊、低分辨率或不相关的图像。确保每个样本能够清晰展现目标情绪特征,保证数据集的质量。
-
格式标准化:将所有图像统一为同一格式(如JPEG或PNG)和尺寸(如224x224像素),以便于后续的处理和模型训练。
-
标注完整性检查:检查每个情绪类别的数据样本数量,确保每个类别都包含足够的样本,以避免模型训练过程中的偏差。
2.2数据标注
数据标注是数据集制作中的关键步骤,主要目标是为每张图像中的面部表情添加情绪标签。标注过程包括以下几个步骤:
-
选择标注工具:选择适合的标注工具,如LabelImg,方便对图像进行准确的标注。
-
绘制边界框:逐一打开图像,使用矩形工具为每个面部表情绘制边界框,并标注相应的情绪类别,如“愤怒”、“快乐”等。
-
确保类别一致性:为每个目标选择正确的情绪类别,并记录这些信息,确保与数据集中定义的类别一致,以避免混淆。
-
保存标注数据:完成标注后,将标注结果保存为指定格式(如XML或TXT),以便于后续使用和模型训练。
-
标注质量审核:对标注结果进行复审,确保每个情绪都已被准确标注,避免漏标或误标。必要时,可以邀请其他人员进行交叉验证,以提高标注的准确性。
使用LabelImg进行人脸情绪识别数据集的标注过程相对复杂且工作量庞大。首先,启动LabelImg软件并选择目标图像文件夹,逐一打开每张图像,使用矩形工具为每个面部表情绘制边界框,包括愤怒、厌恶、恐惧、快乐、中性、悲伤和惊讶等情绪。同时,为每个框选择相应的情绪类别,并记录这些信息。标注完成后,保存每张图像的标注结果,确保数据的安全性和完整性。由于每张图像可能包含多个情绪表现,标注人员需要保持高度的专注,以避免漏标或误标。此外,标注过程中可能需要对图像进行多次调整和检查,因此这一过程不仅耗时耗力,还要求标注人员具备较强的观察力和专业知识,以确保数据集的标注质量符合训练需求。

情绪图片数据集中包含以下几种类别:
- 愤怒:表现出愤怒情绪的面部表情,通常伴有紧绷的眉头和嘴唇。
- 厌恶:表示对某种事物的不满或反感,面部表情通常会皱眉。
- 恐惧:反映出恐惧情绪的面部表情,眼睛睁大,嘴巴微张。
- 快乐:表现出幸福和愉悦的情绪,通常伴有微笑。
- 中性:没有明显情绪表现的面部表情,保持自然状态。
- 悲伤:表达出悲伤情绪的面部表情,通常眉头下垂,嘴角向下。
- 惊讶:表现出惊讶或意外的情绪,眼睛睁大,嘴巴微张。
2.3数据预处理
数据预处理是为模型训练做准备的重要步骤,主要包括以下几个方面:
-
数据增强:通过随机翻转、旋转、缩放、裁剪和颜色调整等方式对原始图像进行增强,增加数据集的多样性,提升模型的泛化能力。
-
归一化处理:对图像像素值进行归一化,将其缩放到[0, 1]或[-1, 1]的范围内,以加速模型训练的收敛速度。
-
划分数据集:将处理后的数据集划分为训练集、验证集和测试集,通常按照70%训练、20%验证、10%测试的比例进行分配,确保每个子集中的情绪分布一致。
-
格式转换:将图像和标注数据转换为适合所用深度学习框架的格式,例如,YOLO模型需要生成对应的TXT文件,记录每张图像中的目标信息。
标注格式:
- VOC格式 (XML)
- YOLO格式 (TXT)
yolo_dataset/
│
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ ├── ...
│ │
│ └── labels/
│ ├── image1.txt
│ ├── image2.txt
│ ├── ...
│
└── test...
└── valid...
voc_dataset/
│
├── train/
│ ├───├
│ │ ├── image1.xml
│ │ ├── image2.xml
│ │ ├── ...
│ │
│ └───├
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── ...
│
└── test...
└── valid...三、模型训练
3.1理论技术
CNN在面部情绪识别中的优势主要体现在其出色的特征提取能力和较高的准确率。由于CNN能够通过多个卷积层提取高层次的特征,模型能够有效区分不同的情绪表情(如愤怒、快乐和悲伤),即使在复杂的背景下也能保持较高的识别准确率。此外,CNN的参数共享机制显著降低了模型的复杂度,使得训练过程更加高效且不易过拟合。这些特性使CNN成为面部情绪识别任务的首选算法,尤其是在具有大量标注数据的情况下。

长短期记忆网络(LSTM)是一种特殊的递归神经网络(RNN),适用于处理时序数据。LSTM通过引入记忆单元和三个门控机制(输入门、遗忘门和输出门),有效地捕捉时间序列中的长期依赖关系。在面部情绪识别任务中,LSTM可以结合时间信息,分析面部表情的变化趋势。每个时间步的输入可以是图像序列中的某一帧,LSTM通过记忆单元存储历史信息,从而更好地识别情绪变化,尤其在视频数据中表现出色。
LSTM在情绪识别中的优势体现在其对时间序列数据的处理能力。与传统的RNN相比,LSTM能够有效克服梯度消失问题,保持较长时间的信息。这使得LSTM在分析连续的面部表情变化时,能够更精准地捕捉到情绪的细微变化,如在愤怒到快乐的转变过程。结合LSTM的动态特性,系统可以在实时情绪识别应用中表现出更高的准确性。此外,LSTM的可扩展性也使其能够与其他深度学习模型(如CNN)结合,形成更强大的混合模型。
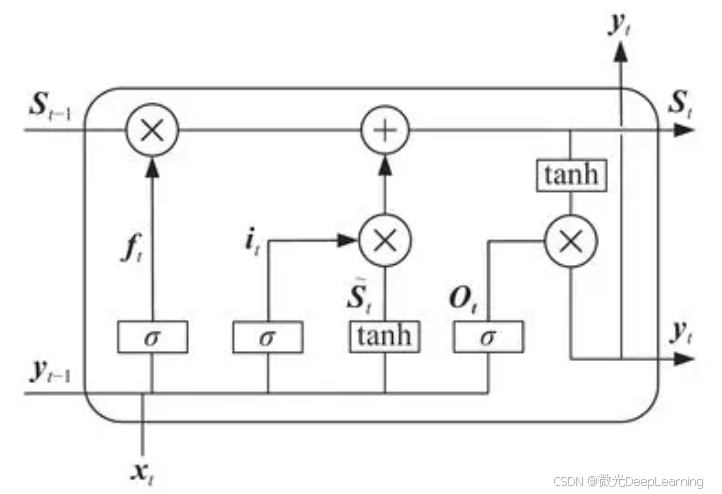
结合CNN和LSTM的优点,可以构建一个改进的算法模型,例如CNN-LSTM模型。在这一模型中,首先使用CNN对输入的面部图像序列进行特征提取,捕捉每一帧图像中的局部特征。然后,将提取到的特征序列输入LSTM,以分析特征随时间的变化,识别情绪状态的动态变化。这种结合不仅能够充分利用CNN在空间特征提取方面的优势,还能发挥LSTM在时间序列分析中的强大能力,从而提升面部情绪识别的准确性和鲁棒性。
3.2模型训练
1. 数据集预处理
在实施YOLO项目之前,首先需准备和划分数据集。数据集应包含多种类型的面部情绪图像,以确保样本的多样性和代表性。可以通过拍摄或网络爬虫等方式收集样本。将数据集随机划分为训练集、验证集和测试集,通常推荐的比例为70%训练、20%验证、10%测试。以下是数据集划分的示例代码:
import os
import random
import shutil
# 定义数据集路径
dataset_path = 'path/to/emotion_dataset'
images = os.listdir(dataset_path)
# 随机划分数据集
random.shuffle(images)
train_split = int(len(images) * 0.7)
val_split = int(len(images) * 0.9)
train_images = images[:train_split]
val_images = images[train_split:val_split]
test_images = images[val_split:]
# 创建新的目录以存放划分后的数据集
os.makedirs('train', exist_ok=True)
os.makedirs('val', exist_ok=True)
os.makedirs('test', exist_ok=True)
for image in train_images:
shutil.copy(os.path.join(dataset_path, image), 'train/')
for image in val_images:
shutil.copy(os.path.join(dataset_path, image), 'val/')
for image in test_images:
shutil.copy(os.path.join(dataset_path, image), 'test/')
数据标注是YOLO项目中的关键环节,准确标注直接影响模型的训练效果。使用LabelImg等标注工具为每张图像中的情绪进行标注,通常采用矩形框的方式。为每个框选择相应的类别,并记录位置信息。以下是标注过程的简要步骤:
- 启动LabelImg,选择需要标注的图像文件夹。
- 逐一打开图像,使用矩形工具绘制边界框。
- 输入类别名称(如“愤怒”、“快乐”等)并保存标注。
- 确保每个情绪均被标注,避免遗漏。
2. 模型训练
在完成数据准备后,需要配置YOLO模型。首先,准备模型的配置文件(如yolov5s.yaml),设置网络参数、学习率和批量大小等。创建数据描述文件(如data.yaml),指定训练和验证数据集路径及类别数。例如,data.yaml文件内容如下:
train: train
val: val
nc: 7 # 目标类别数量(愤怒、厌恶、恐惧、快乐、中性、悲伤、惊讶)
names: ['anger', 'disgust', 'fear', 'happiness', 'neutral', 'sadness', 'surprise']
模型配置完成后,可以开始训练YOLO模型。使用命令行运行YOLO训练命令,模型将开始处理训练数据。训练过程中监控损失值和准确率,以确保模型逐步收敛。以下是训练的示例命令:
python train.py --img 640 --batch 16 --epochs 50 --data data.yaml --weights yolov5s.pt
在训练过程中,可以根据需要调整学习率和其他超参数。例如,使用命令行参数设置学习率:
python train.py --img 640 --batch 16 --epochs 50 --data data.yaml --weights yolov5s.pt --hyp hyp.scratch.yaml
在hyp.scratch.yaml文件中,可以自定义学习率、动量、权重衰减等超参数:
# hyperparameters
lr0: 0.01 # 初始学习率
lrf: 0.1 # 最终学习率
momentum: 0.937 # 动量
weight_decay: 0.0005 # 权重衰减
3. 模型测试与评估
完成训练后,对模型进行测试和评估是检验其性能的关键步骤。使用测试集中的图像,利用训练好的YOLO模型进行目标检测,生成检测结果并进行可视化。可以使用OpenCV对检测结果进行绘制,显示边界框和类别标签。以下是测试和可视化的示例代码:
import cv2
import torch
# 加载训练好的模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='runs/train/exp/weights/best.pt')
# 进行检测
img = 'test/test_image.jpg'
results = model(img)
# 可视化检测结果
results.show() # 显示结果
results.save('output/') # 保存结果到指定目录
四、总结
通过自制数据集和深度学习算法构建一个高效的人脸情绪识别系统。首先,通过精细标注和合理划分数据集,为模型训练提供丰富的样本支持。结合卷积神经网络(CNN)和长短期记忆网络(LSTM),构建了改进的CNN-LSTM模型,以提升情绪识别的准确率和鲁棒性。最终,通过对测试结果的分析,验证了所构建模型的有效性,为人机交互及相关应用提供了可靠的技术保障。

















 7670
7670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









