







记录一下做分布式作业的过程
一、 jdk安装
(一) 打开命令行
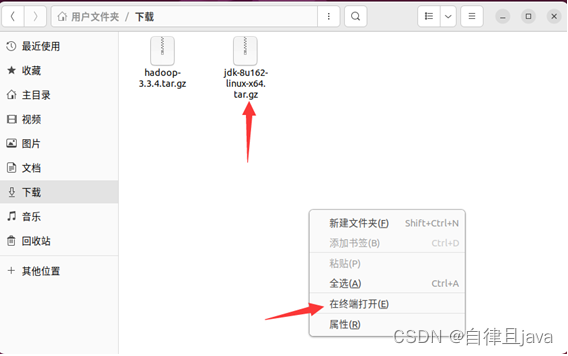
在jdk-8u162-linux-x64.tar.gz所在的文件夹下右键,在终端打开
(二) 解压缩
输入命令
tar xvzf jdk-8u162-linux-x64.tar.gz

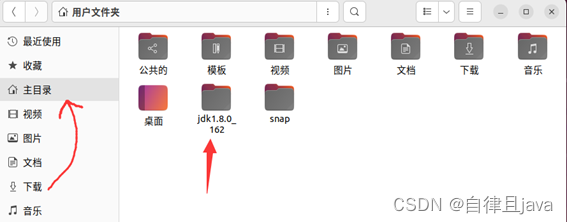
此时可以看到文件夹下面有一个jdk1.8.0_162文件夹,我们将这个文件夹移动到主目录下,直接拖拽即可。
二、 hadoop安装
(一) 打开命令行
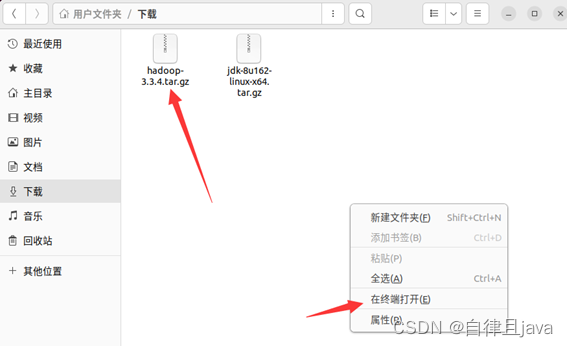
在hadoop-3.3.4.tar.gz所在的文件夹下右键,在终端中打开
(二) 解压缩
输入命令
tar xvzf hadoop-3.3.4.tar.gz

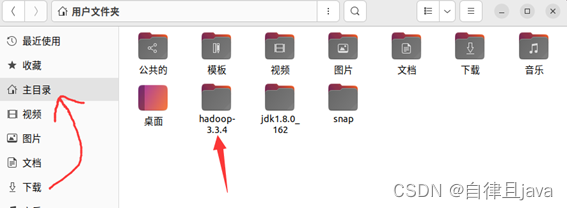
此时可以看到文件夹下面有一个hadoop-3.3.4文件夹,我们将这个文件夹移动到主目录下,直接拖拽即可。
(三) 配置java环境
打开hadoop-3.3.4文件夹,打开etc文件夹,打开hadoop文件夹,找到hadoop-env.sh文件
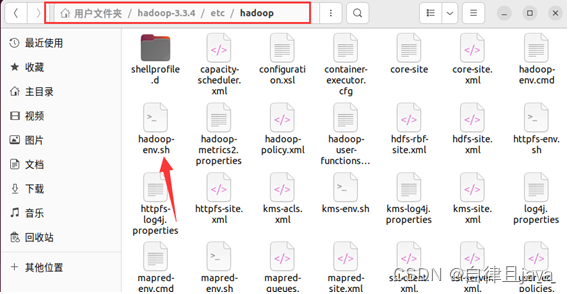
双击打开hadoop-env.sh文件,在文件末尾输入
# set to the root of your Java installation
export JAVA_HOME=/home/xiaojia/jdk1.8.0_162
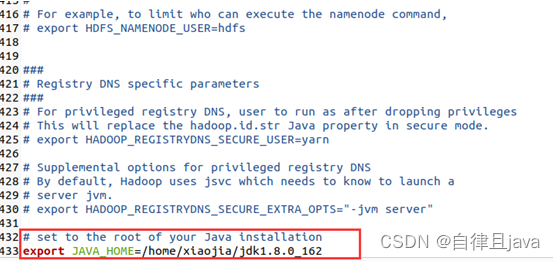
保存退出。
(四) 查看hadoop脚本的使用文档
输入命令切换到hadoop-3.3.4文件夹下
cd ~/hadoop-3.3.4
输入命令查看使用文档
bin/hadoop
三、 伪分布式模式
Hadoop也可以以伪分布式模式运行在单节点上,其中每个Hadoop守护进程运行在单独的Java进程中。
(一) 配置core-site.xml文件
输入命令
vim /home/xiaojia/hadoop-3.3.4/etc/hadoop/core-site.xml
在打开文件中按i进行编辑,输入如下配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
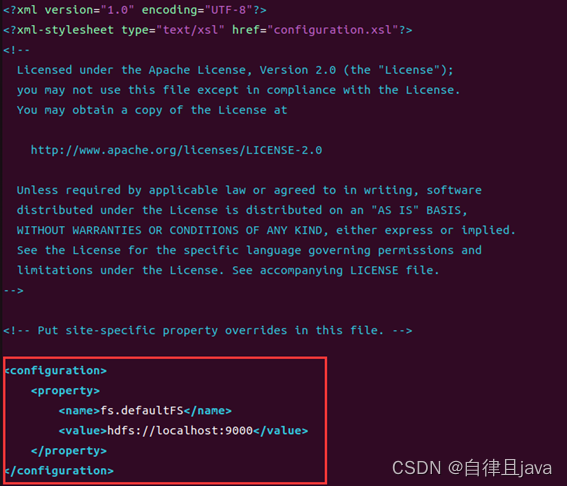
按ESC键,然后按shift + : ,然后输入wq保存退出。
(二) 配置hdfs-site.xml文件
该文件表示HDFS中每个文件有1个备份
输入命令
vim /home/xiaojia/hadoop-3.3.4/etc/hadoop/hdfs-site.xml
在打开的文件中按i进行编辑,输入如下配置
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
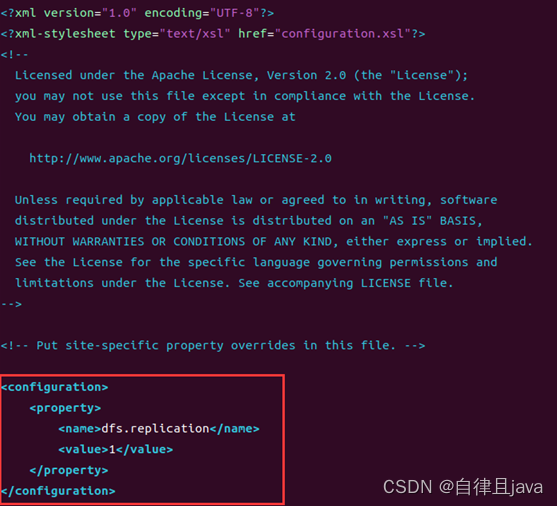
按ESC键,然后按shift + : ,然后输入wq保存退出。
(三) 设置 SSH免密码登录
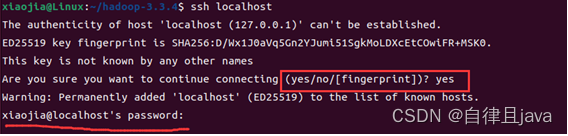
1. 看ssh本地登录是否需要密码
输入命令
ssh localhost
查看ssh本地登录是否需要密码,发现需要密码
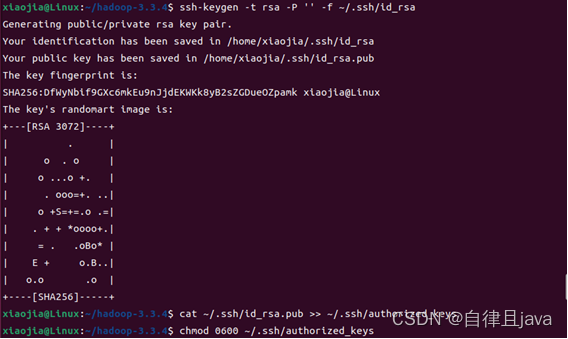
2. 设置ssh免密登录
输入命令
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
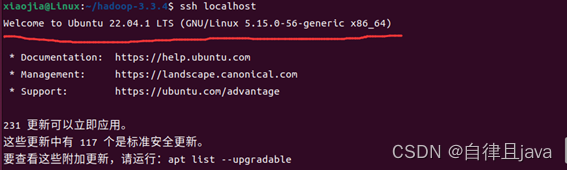
3. 再次查看ssh本地登录是否需要密码
输入命令
ssh localhost
查看ssh本地登录是否需要密码,已经不再需要密码。
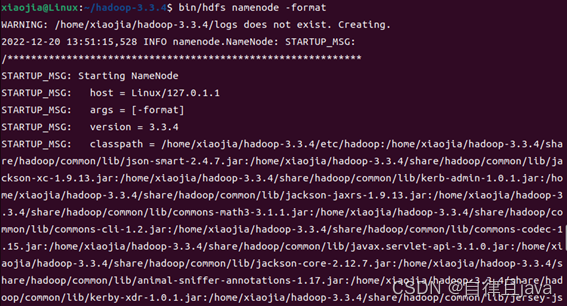
(四) 格式化文件系统
输入命令切换目录
cd /home/xiaojia/hadoop-3.3.4

输入命令格式化文件系统
bin/hdfs namenode -format
(五) 启动NameNode和DataNode守护进程
输入命令
sbin/start-dfs.sh

(六) 在浏览器中问http://localhost:9870/
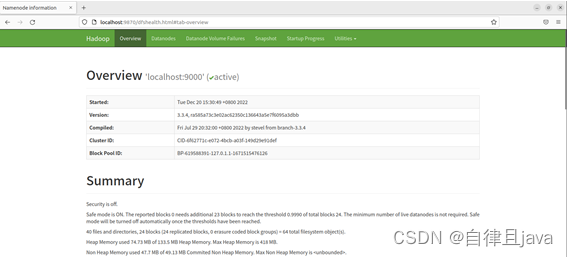
(七) 创建执行MapReduce任务所需的HDFS目录:
输入命令
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/myHadoop

(八) 将输入文件复制到分布式文件系统:
输入命令
bin/hdfs dfs -mkdir input
报错
mkdir: `hdfs://localhost:9000/user/xiaojia': No such file or directory

输入命令
bin/hdfs dfs -mkdir -p input
bin/hdfs dfs -put etc/hadoop/*.xml input

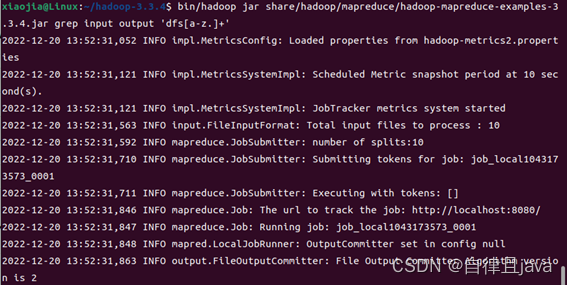
(九) 运行hadoop examples
输入命令
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar grep input output 'dfs[a-z.]+'
(十) 查看grep结果
1. 本地文件系统查看
输入命令
bin/hdfs dfs -get output output
cat output/*

2. 分布式文件系统上查看
输入命令
bin/hdfs dfs -cat output/*

3. 网页端输出
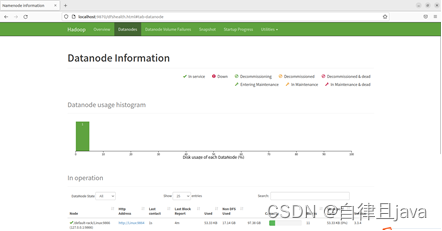
(十一) 停止集群
输入命令
sbin/stop-dfs.sh

四、 选做内容
(一) 配置mapred-site.xml文件
输入命令
vim /home/xiaojia/hadoop-3.3.4/etc/hadoop/mapred-site.xml
在打开的文件中按i进行编辑,输入如下配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
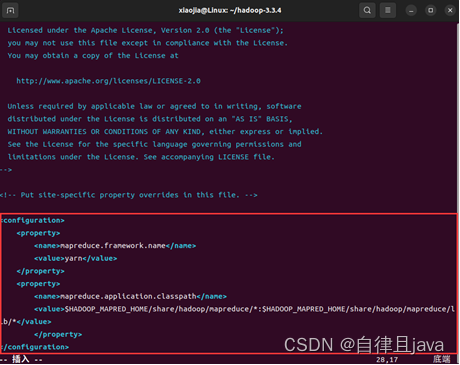
按ESC键,然后按shift + : ,然后输入wq保存退出。
(二) 配置yarn-site.xml文件
输入命令
vim /home/xiaojia/hadoop-3.3.4/etc/hadoop/yarn-site.xml
在打开的文件中按i进行编辑,输入如下配置
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED</value>
</property>
<!-- Site specific YARN configuration properties -->
</configuration>
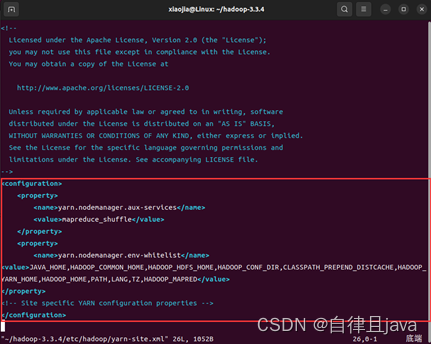
按ESC键,然后按shift + : ,然后输入wq保存退出。
(三) 启动ResourceManager和NodeManager守护进程
输入命令
sbin/start-yarn.sh

(四) 在浏览器中访问http://localhost:8088/
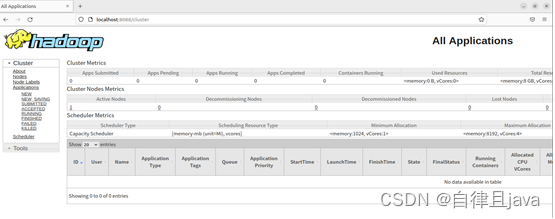
(五) 运行hadoop examples
输入命令
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar grep input output 'dfs[a-z.]+'
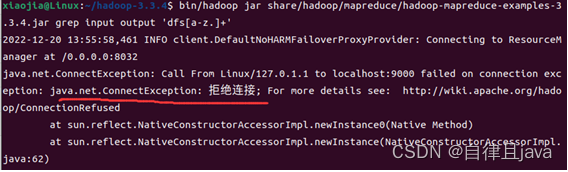
拒绝连接,输入命令
sbin/start-dfs.sh

再次输入命令
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar grep input output 'dfs[a-z.]+'
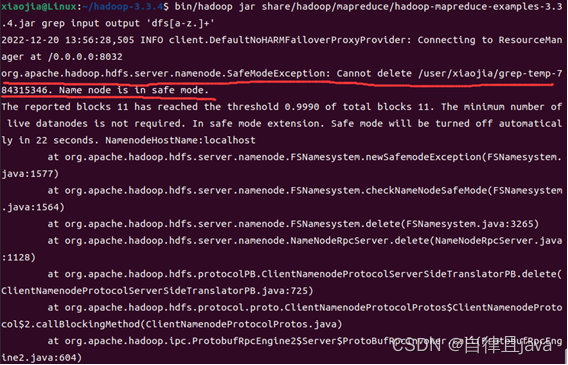
hdfs开启了安全模式,关闭即可,输入命令
hadoop dfsadmin -safemode leave

Hadoop未找到命令,输入命令
vim ~/.bashrc
打开文件按i添加内容
export PATH=$PATH:/home/xiaojia/hadoop-3.3.4/sbin:/home/xiaojia/hadoop-3.3.4/bin
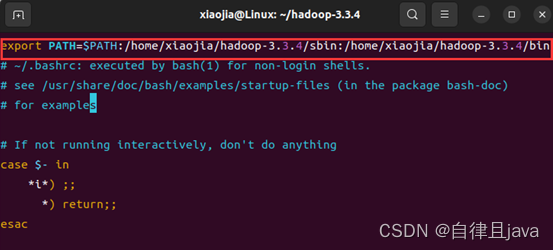
按ESC键,然后按shift + : ,然后输入wq保存退出。
输入命令重新执行。
source ~/.bashrc
输入命令
hadoop dfsadmin -safemode leave

再次输入命令
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar grep input output 'dfs[a-z.]+'
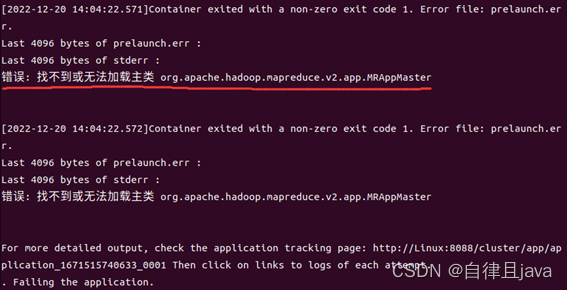
找不到或无法加载主类,输入命令
hadoop classpath
保存返回的地址
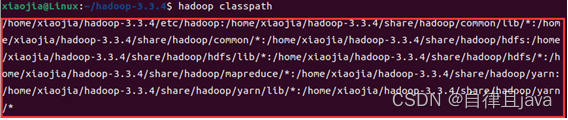
输入命令
vim /home/xiaojia/hadoop-3.3.4/etc/hadoop/yarn-site.xml
打开yarn-site.xml文件,按i输入以下内容
<configuration>
<property>
<name>yarn.application.classpath</name>
<value>输入刚才返回的Hadoop classpath路径</value>
</property>
</configuration>
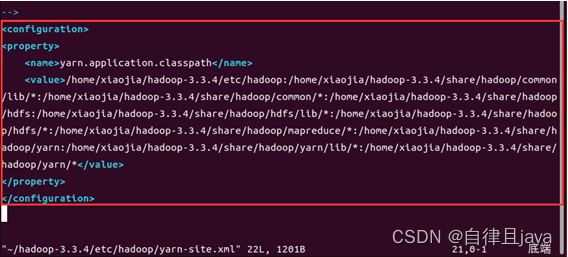
再次输入命令
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar grep input output 'dfs[a-z.]+'
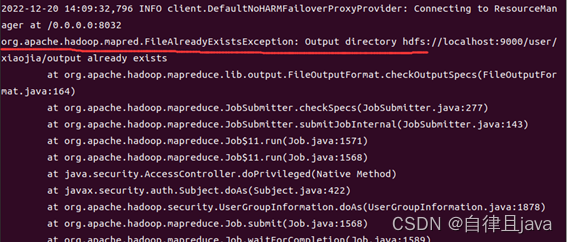
文件夹已存在,删除文件夹,输入命令
sudo rm -rf output/

再次输入命令
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar grep input output 'dfs[a-z.]+'
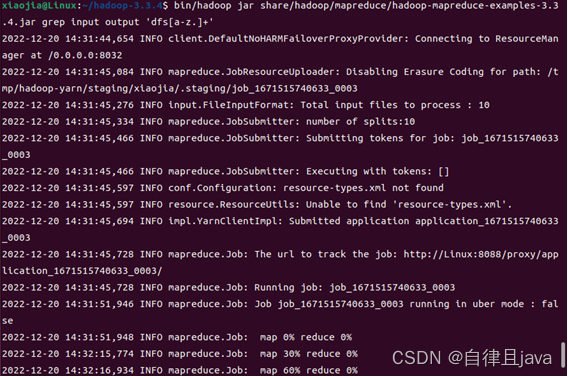
(六) 查看grep结果
1. 本地文件系统查看
输入命令
bin/hdfs dfs -get output output
cat output/*

2. 分布式文件系统上查看
输入命令
bin/hdfs dfs -cat output/*

3. 网页端输出
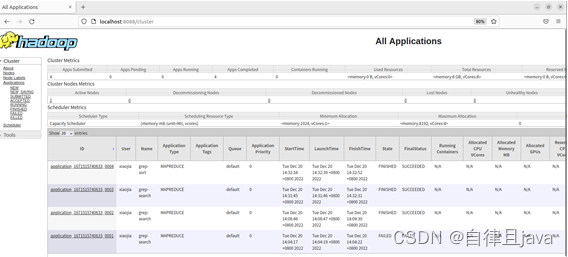
(七) 停止集群
输入命令
sbin/stop-yarn.sh

输入命令
sbin/stop-dfs.sh
















 154
154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









