









随着 Stable Diffusion 的不断进化,越来越多的开发者加入到插件开发的行列中。大家都知道网上虽然教程多,但非常碎片,一个个学习和查阅真的非常耗时,感觉每天都在烧脑。如果你是 SD 小白或者是小懒猫,又想快速上手使用 Stable Diffusion 插件,那么这篇文章就非常适合你了!因为这是以设计师日常应用的角度出发,从推荐指数、易上手程度、使用频率三个维度来测评。
一、前方高能
1. prompt-all-in-one 提示词翻译补全(自动翻译)
推荐指数:☆☆☆☆☆
易上手程度:☆☆☆☆☆
使用频率:☆☆☆☆☆
能做什么:prompt-all-in-one 提示词翻译补全可以帮助英文不好的用户,快速弥补英文短板。其中包含,中文输入自动转英文、自动保存使用描述词、描述词历史记录、快速修改权重、收藏常用描述词、翻译接口可以多种选择、一键粘贴删除描述词等。
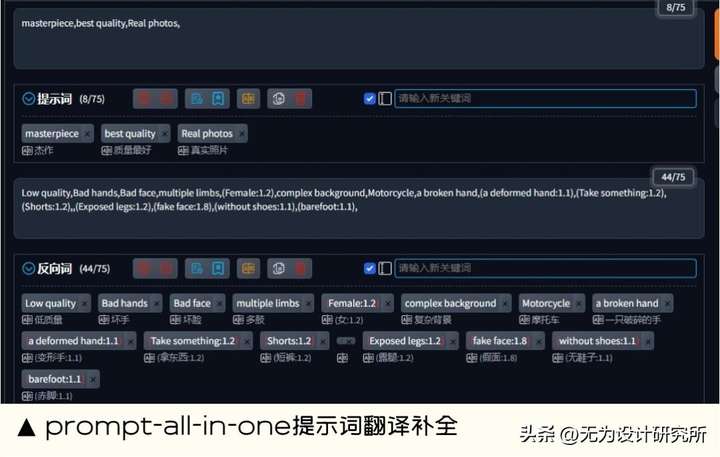
扩展地址: https://github.com/Physton/sd-webui-prompt-all-in-one
2. SixGod 提示词插件
推荐指数:☆☆☆☆
易上手程度:☆☆☆☆☆
使用频率:☆☆☆☆
能做什么:SixGod 提示词插件可以帮助用户快速生成逼真、有创意的图像。其中包含,清空正向提示词”和“清空负向提示词、提示词起手式包含人物、服饰、人物发型等各个维度的提示词、一键清除正面提示词与负面提示词、随机灵感关键词、提示词分类组合随机、动态随机语法等。
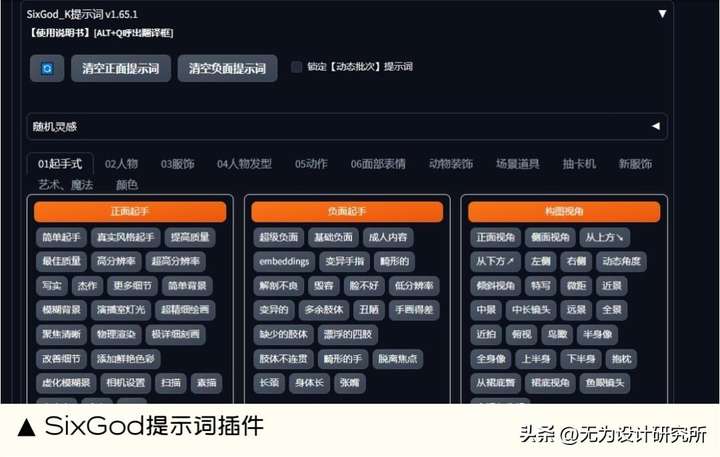
扩展地址: https://github.com/thisjam/sd-webui-oldsix-prompt
3. After Detailer 人脸及手部修复插件
推荐指数:☆☆☆☆☆
易上手程度:☆☆☆☆☆
使用频率:☆☆☆☆
能做什么:After Detailer 是一款强大的图像编辑工具,可用于修复和编辑图像。自动修复图像中的瑕疵 ,无论是 2D 还是真实的人脸及手部都可以通过识别面部/人物/手部并自动对其进行 mask 和重绘的工具,可以通过调整参数去改变识别的对象和识别区域的大小及位置等。
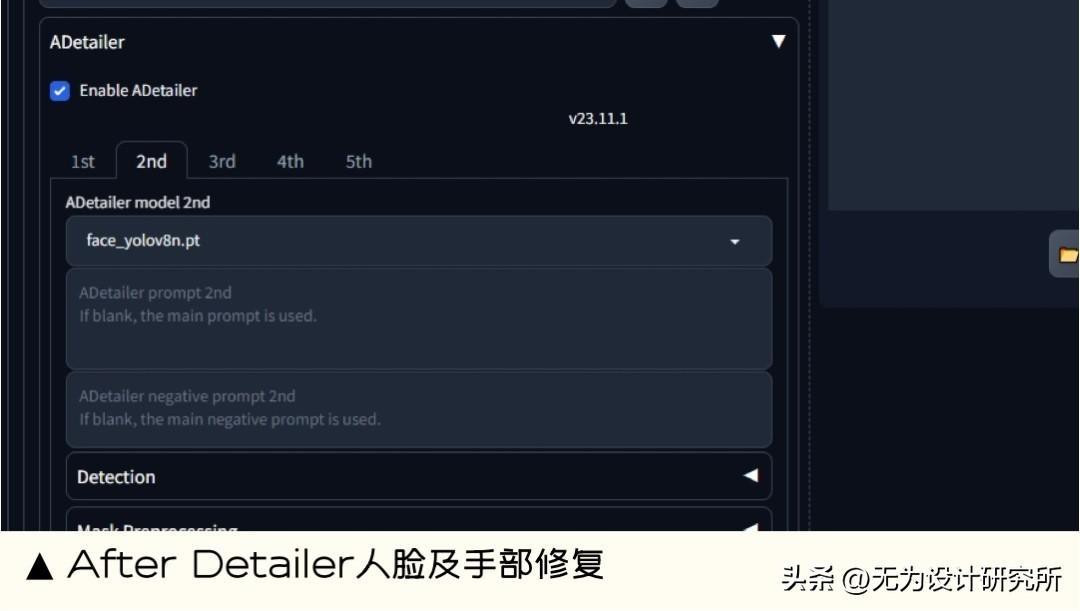
扩展地址: https://github.com/Bing-su/adetailer
4. Tagger 提示词反推
推荐指数:☆☆☆
易上手程度:☆☆☆☆☆
使用频率:☆☆
能做什么:Tagger 提示词反推可以从任意图片中提取。帮助理解图像的内容、创建创意图像、分析图像数据。
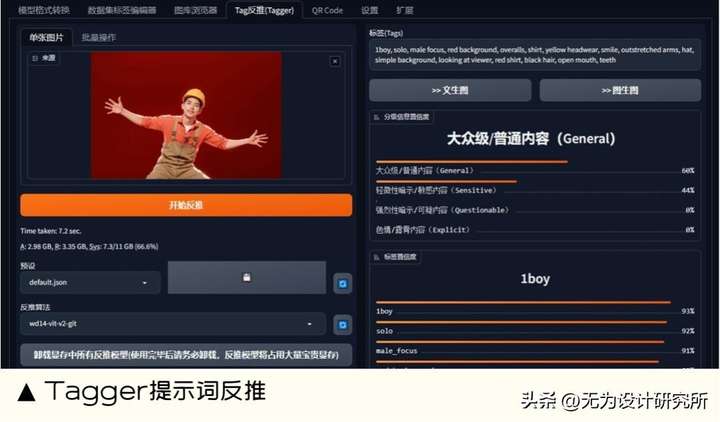
扩展地址: https://github.com/pythongosssComfyUI-WD14-Tagger?tab=readme-ov-file
5. Inpaint Anything 蒙版换装换脸
推荐指数:☆☆☆☆
易上手程度:☆☆☆
使用频率:☆☆
能做什么:Inpaint Anything 是一款强大的图像编辑工具,可用于删除和替换图像中的任何内容。它使用人工智能来自动识别和修复图像中的缺陷,无需使用遮罩。删除图像中的不需要的对象或瑕疵、修复图像中的损坏、替换图像中的对象或背景、创建创意图像效果。
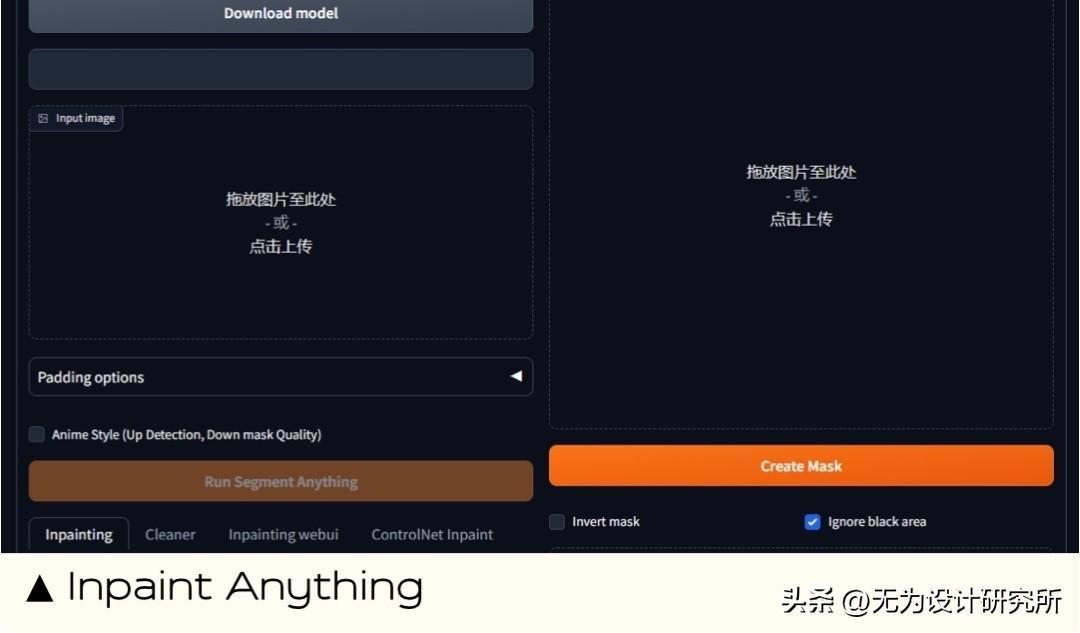
扩展地址: https://github.com/Uminosachi/sd-webui-inpaint-anything
6. Segment Anything 识别分割图片中的物体
推荐指数:☆☆☆
易上手程度:☆☆
使用频率:☆
能做什么:Segment Anything 是一款强大的图像分割工具,可用于自动识别和分割图像中的不同对象。类似于 controlnet 中的 SEG 语义分割,但 Segment Anything 是功能更强大、准确性更高、易用性也更高的图像分割工具, 但学习成本更高。
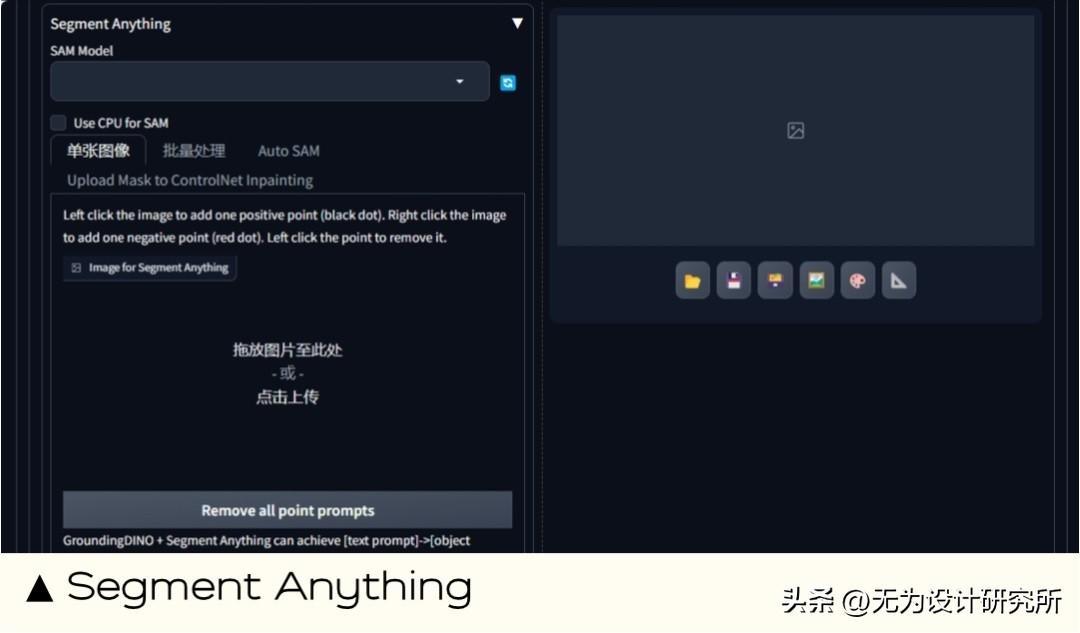
扩展地址: https://github.com/facebookresearch/segment-anything.git
7. ultimate SD upscale 图片放大
推荐指数:☆☆☆☆
易上手程度:☆☆☆☆
使用频率:☆☆☆☆
能做什么:Ultimate SD Upscale 是一款强大的图像超分辨率工具,可用于将低分辨率图像提升到高分辨率、减少噪声和模糊。Ultimate SD Upscale 使用的超分辨率模型是基于深度学习的,因此具有较高的准确性。
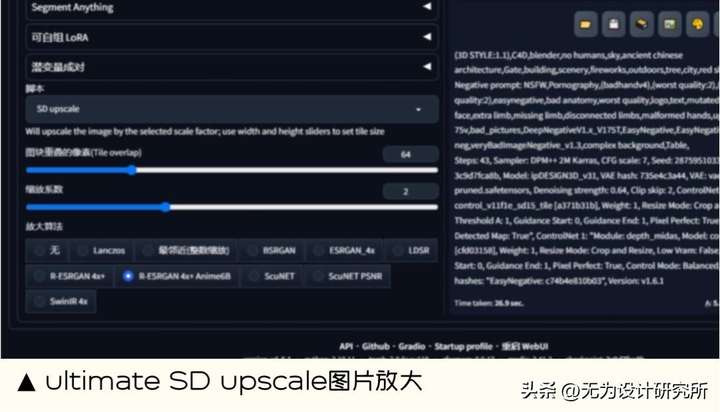
扩展地址: https://github.com/Coyote-A/ultimate-upscale-for-automatic1111.git
8. Tiled Diffusion
推荐指数:☆☆☆
易上手程度:☆☆
使用频率:☆☆☆
能做什么:Tiled Diffusion 同样是图像超分辨率、修复图像瑕疵的工具。Tiled Diffusion 适合小显存,速度更快,细节添加更可控,也不容易崩坏。
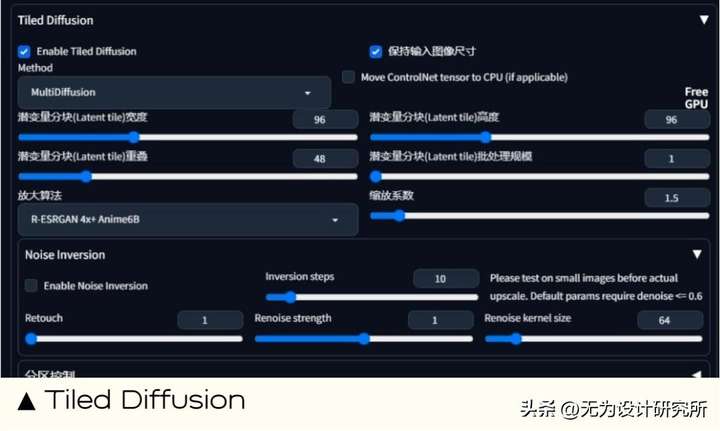
扩展地址: https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
本人用 Ultimate SD Upscale 最多,因为它相对更有发挥空间。而 Tiled Diffusion 是可以让图片看起来更逼真。、
10. Additional Networks
推荐指数:☆☆
易上手程度:☆
使用频率:☆
能做什么:Additional Networks 是一个由 Google AI 开发的插件,可用于模型中添加额外的 LoRA,也可帮我们控制多个 LoRA 模型生成混合风格的图像,从而提升图片的独创性。

扩展地址: https://github.com/kohya-ss/sd-webui-additional-networks.git
11. Image-recognition 图片信息识别
推荐指数:☆☆☆
易上手程度:☆☆☆☆☆
使用频率:☆☆☆☆
能做什么:sd-webui-图片信息识别是一个由 Google AI 开发的开源插件,可基于图片识别模型、图片中的物体、场景、人物等信息,并将其输出为文本。
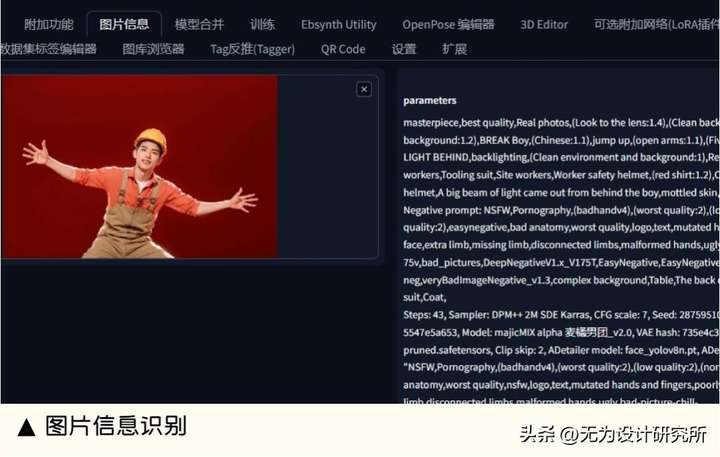
扩展地址: https://github.com/google/sd-webui-image-recognition
12. Openpose Editor 姿态编辑
推荐指数:☆☆☆☆☆
易上手程度:☆☆☆☆☆
使用频率:☆☆☆☆☆
能做什么:识别图片中的人物姿态,可以根据需求随意调整人物的姿势,例如武术、手托腮、人物复杂姿态。
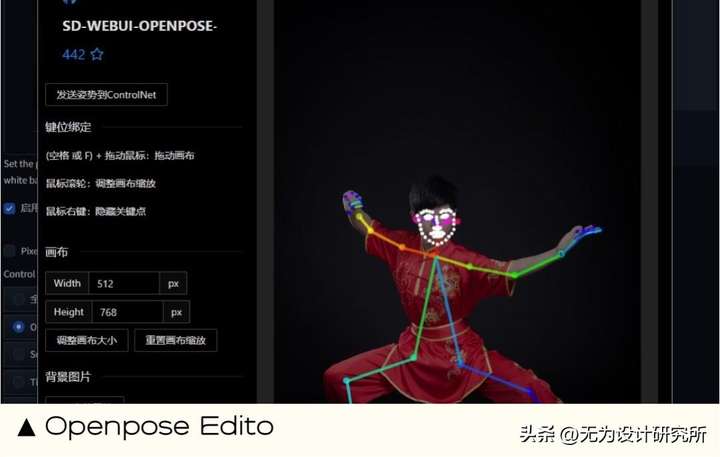
13. DWpose 手部修复
推荐指数:☆☆☆☆
易上手程度:☆☆☆☆☆
使用频率:☆☆☆☆
能做什么:普通 OpenPose 模型的强化版,对手部动态识别有更好的理解能力,对复杂的穿插关系的姿态识别表现出众。
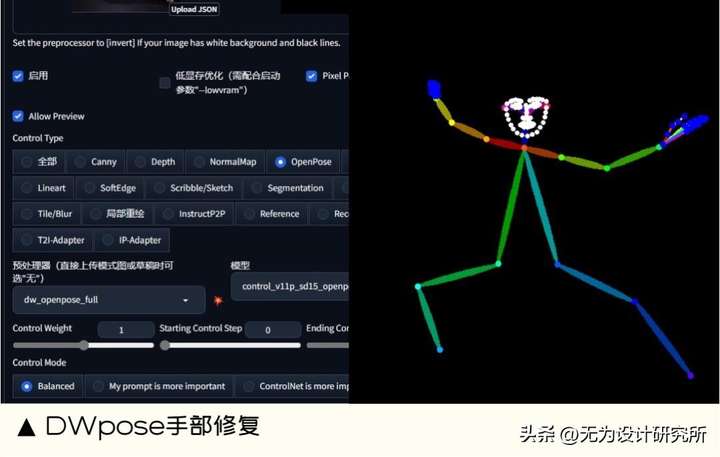
扩展地址: https://github.com/IDEA-Research/DWPose
14. IP-Adaper
推荐指数:☆☆☆
易上手程度:☆☆☆☆☆
使用频率:☆☆
能做什么:IP-Adapter 是腾讯的另一个实验室 Tencent AI Lab 研发的控图模型。名称中的 IP 指的是 Image Prompt 图像提示,它和 T2I-Adapter 一样是一款小型模型,用于风格迁移、可理解为垫图。

扩展地址: https://github.com/tencent-ailab/IP-Adapter ;https://ip-adapter.github.io/
15. Recolor 重新上色
推荐指数:☆☆☆☆
易上手程度:☆☆☆☆☆
使用频率:☆
能做什么:Recolor 是给图片填充颜色,非常适合修复一些黑白老旧照片和去过色的图片。
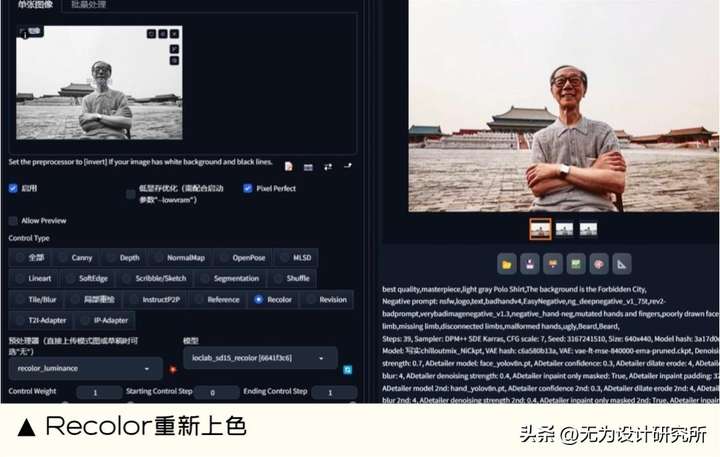
16. T2I-Adapter 文生图适配器
推荐指数:☆☆☆☆
易上手程度:☆
使用频率:☆☆
能做什么:T2I-Adapter 由腾讯 ARC 实验室和北大视觉信息智能学习实验室联合研发的一款小型模型,它的作用是为各类文生图模型提供额外的控制引导,同时又不会影响原有模型的拓展和生成能力。T2I-Adapter 的特点是体积小,参数级只有 77M,但对图像的控制效果不错。
扩展地址: https://huggingface.co/TencentARC/T2I-Adapter/tree/main/models
总体而言,Stable Diffusion 功能非常强大、也逐渐变得易于使用了。如果你还没有尝试过 SD,我强烈建议你试试看。它一定会给你带来惊喜!
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
👉[[CSDN大礼包:《StableDiffusion安装包&AI绘画入门学习资料》免费分享]](安全链接,放心点击)
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉大厂AIGC实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉12000+AI关键词大合集👈

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









