






NLP作业01:请利用HMM实现词性标注
一、课程目标
| 这个作业属于那个课程 | 自然语言处理 |
| 这个作业要求在哪里 | http://t.csdn.cn/f0hUe |
| 我在这个课程的目标是 | 我希望在学习完这门课后,我能够掌握分词及标注的基本方法并且熟练使用各种数据处理的方式;并且能从中找出能够帮助个人或企业实现商业目的有价值的东西。 |
| 这个作业在那个具体方面帮助我实现目标 | 此次作业所用到的HMM,是NLP中重要的分词算法之一,用来解决文本序列标注问题。 |
| 参考文献 |
二、HMM模型介绍
隐含马尔可夫模型(HMM)是将分词作为字在句子中的序列标注任务来实现分词的。其基本思路是:每个字在构造一个特定的词语时都占据着一个确定的词位,现设定每个字最多只有四种构词位置:即B(Begin 词首)、M(Middle 词中)、E(End 词尾)、S(single 单独成词)。
HMM是一个五元组(O,S,O0,A,B):
- O:{o1...ot}是状态集合, 也称为观测序列;
- S:{s1...sv}是一组输出结果,也称隐序列;
- aij=P(sj|si):转移概率分布;
- bij=P(oj|si):发射概率分布;
- O0是初始状态,有些还有终止状态。
HMM可以用于估算隐藏于表面事件背后的事件的概率。 在词性标注中,词串可视为可观察序列,词的词性可视为隐序列。
三、估计HMM的模型参数
我是根据这个链接(http://t.csdn.cn/Huaak)中的相关知识来进行对HMM模型参数的深入学习与实践应用的。
def cal_hmm_matrix(observation):
# 得到所有标签
word_pos_file = open('ChineseDic.txt',encoding='utf-8').readlines()
tags_num = {}
for line in word_pos_file:
word_tags = line.strip().split(',')[1:]
for tag in word_tags:
if tag not in tags_num.keys():
tags_num[tag] = 0
tags_list = list(tags_num.keys())
# 转移矩阵、发射矩阵
transaction_matrix = np.zeros((len(tags_list), len(tags_list)), dtype=float)
emission_matrix = np.zeros((len(tags_list), len(observation)), dtype=float)
# 计算转移矩阵和发射矩阵
word_file = open('199801.txt',encoding='utf-8').readlines()
for line in word_file:
if line.strip() != '':
word_pos_list = line.strip().split(' ')
for i in range(1, len(word_pos_list)):
tag = word_pos_list[i].split('/')[1]
pre_tag = word_pos_list[i - 1].split('/')[1]
try:
transaction_matrix[tags_list.index(pre_tag)][tags_list.index(tag)] += 1
tags_num[tag] += 1
except ValueError:
if ']' in tag:
tag = tag.split(']')[0]
else:
pre_tag = tag.split(']')[0]
transaction_matrix[tags_list.index(pre_tag)][tags_list.index(tag)] += 1
tags_num[tag] += 1
for o in observation:
# 注意这里用in去找(' 我/',' **我/'的区别),用空格和‘/’才能把词拎出来
if ' ' + o in line:
pos_tag = line.strip().split(o)[1].split(' ')[0].strip('/')
if ']' in pos_tag:
pos_tag = pos_tag.split(']')[0]
emission_matrix[tags_list.index(pos_tag)][observation.index(o)] += 1
for row in range(transaction_matrix.shape[0]):
n = np.sum(transaction_matrix[row])
transaction_matrix[row] += 1e-16
transaction_matrix[row] /= n + 1
for row in range(emission_matrix.shape[0]):
emission_matrix[row] += 1e-16
emission_matrix[row] /= tags_num[tags_list[row]] + 1
times_sum = sum(tags_num.values())
for item in tags_num.keys():
tags_num[item] = tags_num[item] / times_sum
# 返回隐状态,初始概率,转移概率,发射矩阵概率
return tags_list, list(tags_num.values()), transaction_matrix, emission_matrix
四、基于维特比算法进行解码
在HMM的解码问题中,我们可以使用穷举法把所有可能的隐序列的概率都计算出来,这样最优解自然就出来了,但是缺点也很明显,即计算量太大。Viterbi算法的主要思想是寻找局部最优路径,即寻找所有序列中在t时刻以状态j终止的最大概率,所对应的路径为部分最优路径。
Viterbi算法是用动态规划的方法求解最优的标注序列。每个标注序列视为从句首到句尾的一个路径,通过Viterbi算法获取概率最大的路径,在主要由以下几步实现:
1、状态dp[i][j] =dp[i][j]:表示第i ii个字符标签为j jj 的所有路径中的最大概率。
2、记录路径 path[ i ] [ j ] path[i][j]path[i][j]:表示d p [i][j]dp[i][j]dp[i][j]为最大概率时,第i − 1 i-1i−1个字符的标签
3、状态初始化:dp[ 0 ][ j ] = start( j )emit( j, w0)
4、递推(状态转移方程):d p [ i ] [ j ] = m a x k ∈ { p o s } ( d p [ i − 1 ] [ k ] × t r a n s [ k , j ] ) × e m i t [ j , w i ]
5、记录路径:path[ i ] [ j ] = argmaxk ∈ { pos } (dp[ i − 1 ] [ k ] × trans[ k , j ] )
6、回溯最优路径:pi = path[ i + 1 ] [p( i + 1 )]i = n − 1, n − 2 , … … 1 , 0
7、输出最优路径:[ p1 , p2 … … pn]
def viterbi(obs_len, states_len, init_p, trans_p, emit_p):
"""
:param obs_len: 观测序列长度 int
:param states_len: 隐含序列长度 int
:param init_p:初始概率 list
:param trans_p:转移概率矩阵 np.ndarray
:param emit_p:发射概率矩阵 np.ndarray
:return:最佳路径 np.ndarray
"""
max_p = np.zeros((states_len, obs_len)) # max_p每一列为当前观测序列不同隐状态的最大概率
path = np.zeros((states_len, obs_len)) # path每一行存储上max_p对应列的路径
# 初始化max_p第1个观测节点不同隐状态的最大概率并初始化path从各个隐状态出发
for i in range(states_len):
max_p[i][0] = init_p[i] * emit_p[i][0]
path[i][0] = i
# 遍历第1项后的每一个观测序列,计算其不同隐状态的最大概率
for obs_index in range(1, obs_len):
new_path = np.zeros((states_len, obs_len))
# 遍历其每一个隐状态
for hid_index in range(states_len):
# 根据公式计算累计概率,得到该隐状态的最大概率
max_prob = -1
pre_state_index = 0
for i in range(states_len):
each_prob = max_p[i][obs_index - 1] * trans_p[i][hid_index] * emit_p[hid_index][obs_index]
if each_prob > max_prob:
max_prob = each_prob
pre_state_index = i
# 记录最大概率及路径
max_p[hid_index][obs_index] = max_prob
for m in range(obs_index):
# "继承"取到最大概率的隐状态之前的路径(从之前的path中取出某条路径)
new_path[hid_index][m] = path[pre_state_index][m]
new_path[hid_index][obs_index] = hid_index
# 更新路径
path = new_path
# 返回最大概率的路径
max_prob = -1
last_state_index = 0
for hid_index in range(states_len):
if max_p[hid_index][obs_len - 1] > max_prob:
max_prob = max_p[hid_index][obs_len - 1]
last_state_index = hid_index
return path[last_state_index]
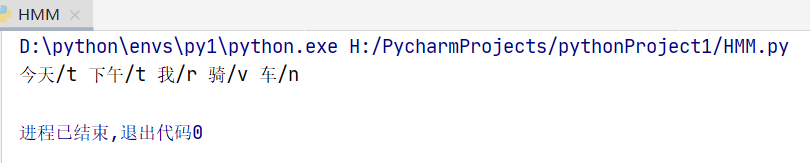
五、词性标注结果
在开始测试时,在测试的时候我发现无论输入什么句子,词性标注都是Rg和Yg。


后来,查资料发现是用的数据平滑不行,改用Laplace平滑方法后,标注的结果就有了很大的改善。
















 141
141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









