









下载模型、代码及数据集
从huggingface或镜像网站下载模型及ice_text.model文件,如chatglm3-6b-32kTHUDM/chatglm3-6b-32k at main![]() https://huggingface.co/THUDM/chatglm3-6b-32k/tree/mainice_text.model · THUDM/chatglm-6b at main
https://huggingface.co/THUDM/chatglm3-6b-32k/tree/mainice_text.model · THUDM/chatglm-6b at main![]() https://huggingface.co/THUDM/chatglm-6b/blob/main/ice_text.model
https://huggingface.co/THUDM/chatglm-6b/blob/main/ice_text.model
从github下载chatglm3的代码,解压后在项目的主目录建立model等文件夹放自己下载的模型,并将ice_text.model也放在模型文件夹GitHub - THUDM/ChatGLM3: ChatGLM3 series: Open Bilingual Chat LLMs | 开源双语对话语言模型
从Google云端硬盘下载淘宝对话数据集,下载后ChatGLM3/finetune_demo建立data文件夹,在这个文件夹解压
注:打不开或下载速度慢可以用安装clash进行科学上网,具体配置请见其他博客。
测试对话
先在cmd等进入主目录,通过pip install -r requirements.txt命令下载,这里不做演示。

在IDE如pycharm、vscode或cursor打开项目,修改basic_demo/cli_demo.py中的MODEL_PATH为自己的文件夹路径,比如

注:1.没有gpu,可以将model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True, device_map="cuda").cuda().eval()改为model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True, device_map="cpu").float().eval()
2.内存太小,使用量化的方式加载。
运行cli_demo.py代码,能正常回答说明配置基本正确

画圈是警告的内容,不是chatglm的回答,可以忽略

如果出现No module named 'transformers_modules.xx,通常是transformers版本较低,建立检查transformers版本是否正确,也可能是选择了错误的python环境
数据集预处理
我的预处理方式的函数如下,主要目的是转化为chatglm的多轮对话数据集的格式,clean_text可自行修改或不做特殊处理,system_prompt用于整体提示AI生成的内容,数据类型是字符串,添加系统角色的代码可根据实际需要决定是否删除
def process_ecommerce_dataset(input_file: Union[str, Path], output_file: Union[str, Path]):
def clean_text(text: str) -> str:
# 去除多余的空格
text = text.replace(' ','')#''.join(text.split())
# 在特定位置添加逗号
text = re.sub(r'(那要怎样)(这)(也不行)', r'\1\2,\3', text) # 在特定短语中插入逗号
#text = re.sub(r'([,])([^\s])', r'\1 \2', text) # 在逗号后添加空格
text = re.sub(r'(?<!,)(但|但是|如果|只要|所以|然而|不过)([^\s])', r',\1\2', text) # 在“但”前添加逗号
#text = re.sub(r'([。!?])([^\s])', r'\1 \2', text) # 在句号、问号、感叹号后添加空格
# 处理语气词
text = re.sub(r'([呢|嘛|吗|哦|啊])([^\s])', r'\1 \2', text) # 在语气词后添加空格
text=text.strip()
# # 添加标点符号
# if not text.endswith('。'):
# text += '。'
return text
# 读取数据
input_file = _resolve_path(input_file)
output_file = _resolve_path(output_file)
# 读取数据
with open(input_file, 'r', encoding='utf-8') as f:
lines = f.readlines()
conversations = []
for line in lines:
parts = line.strip().split('\t')
if len(parts) < 3:
continue # 跳过不完整的行
# 假设每个对话的发言和响应都可以被视为用户和助手的交替
label = parts[0]
utterances = parts[1:-1] # 所有发言
response = parts[-1] # 最后一个是响应
# 构建对话内容
conversation = {
"conversations": []
}
# 添加系统角色(可选)
conversation["conversations"].append({
"role": "system",
"content": system_prompt # 可以根据需要自定义
})
# 添加用户和助手的发言
for i, utterance in enumerate(utterances):
role = "user" if i % 2 == 0 else "assistant" # 假设用户和助手交替发言
cleaned_utterance = clean_text(utterance) # 清理发言
conversation["conversations"].append({
"role": role,
"content": cleaned_utterance
})
# 添加最后的响应
cleaned_response = clean_text(response) # 清理响应
conversation["conversations"].append({
"role": "assistant",
"content": cleaned_response
})
conversations.append(conversation)
# 将处理后的数据保存为 JSON 格式
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(conversations, f, ensure_ascii=False, indent=4)
process_ecommerce_dataset('finetune_demo/data/E-commerce dataset/train.txt', 'finetune_demo/data/E-commerce dataset/data/train.json')
process_ecommerce_dataset('finetune_demo/data/E-commerce dataset/dev.txt', 'finetune_demo/data/E-commerce dataset/data/dev.json')
process_ecommerce_dataset('finetune_demo/data/E-commerce dataset/test.txt', 'finetune_demo/data/E-commerce dataset/data/test.json')
处理后的部分数据如下

lora微调训练
在cmd进入ChatGLM3\finetune_demo目录,再次运行pip install -r requirements.txt命令下载相关配置。
![]()
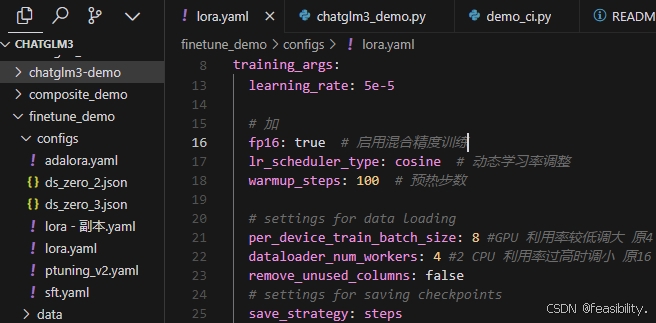
打开configs文件夹的lora.yaml文件,其中的output_dir是自己保存训练时生成模型文件夹的路径,参数可根据实际情况调整或增加,建议启用 fp16 混合精度训练减少内存开销并加速训练,将 lr_scheduler_type 设为 cosine,搭配 100 步 warmup_steps 预热,能提升模型收敛速度与性能
finetune_hf.py可以修改每次加载的验证集数量,或者保留
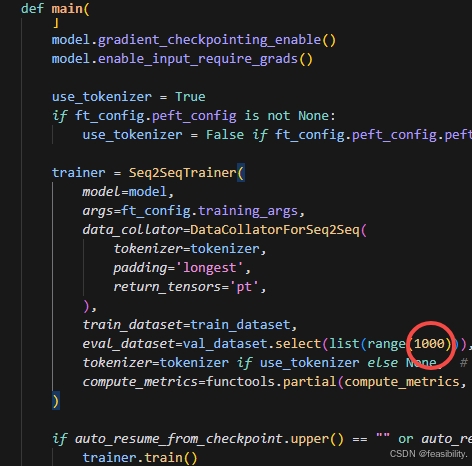
运行微调命令python finetune_hf.py 数据集路径 模型路径 你的lora微调配置文件路径,如python finetune_hf.py data/E-commerce dataset/data E:\Project\ML\ChatGLM3\model\chatglm3-6b-32k configs/lora.yaml ,结果出现报错,但运行其他数据集却能正常加载。
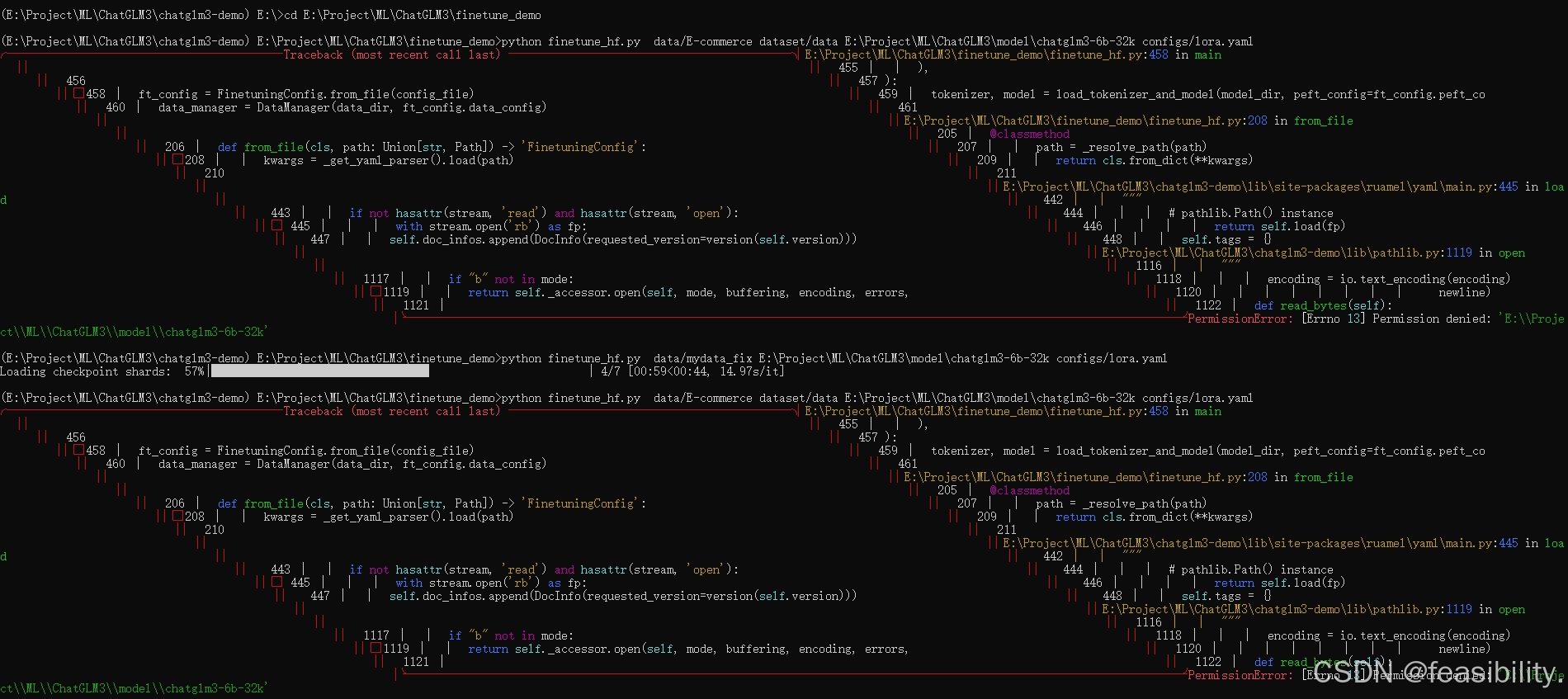
打开任务管理器检查文件夹是否被占用,点击性能,打开资源管理器,搜索模型文件夹,查看关联的句柄,发现不是这个模型文件夹被占用的原因
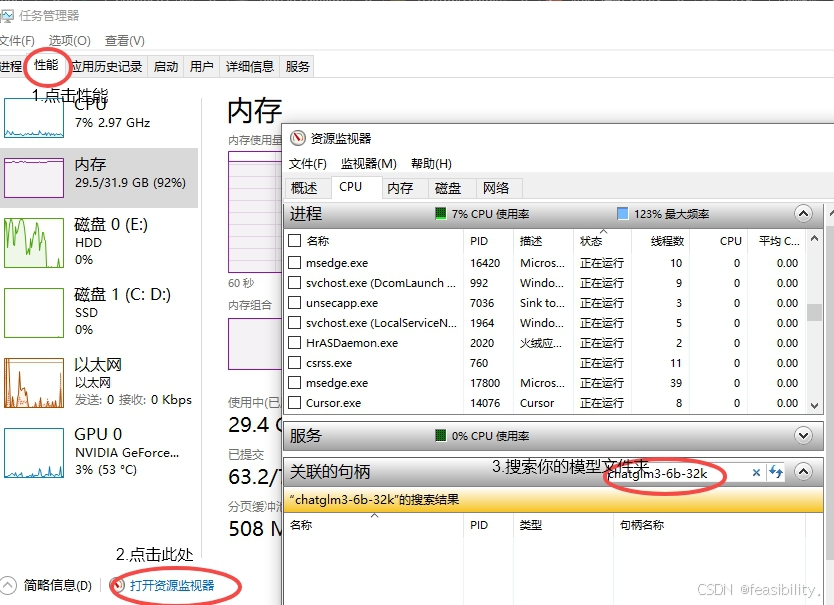
猜测是路径问题,发现命令中比较特别的路径是数据集的路径(存在空格),修改文件夹data/E-commerce dataset为data/E-commerce_dataset,修改命令为再次运行,成功执行!
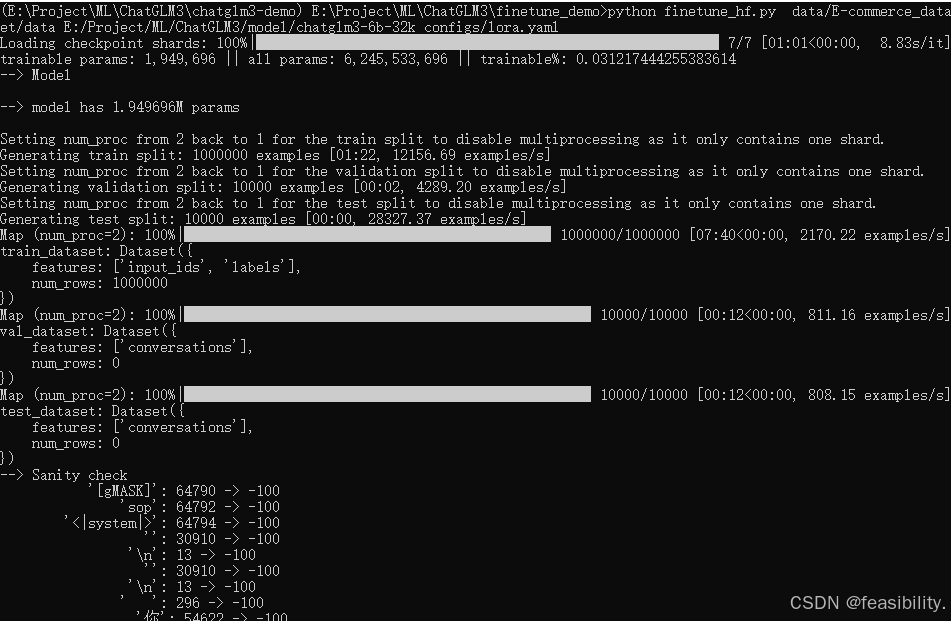
中断后加yes继续上一次的微调训练

其他报错:关于weight_only的报错如下,这是torch2.6.0版本导致默认为True,要么torch降级,要么在transformers改trainer.py文件,将checkpoint_rng_state = torch.load(rng_file)修改为checkpoint_rng_state = torch.load(rng_file,weights_only=False)
_pickle.UnpicklingError: Weights only load failed. This file can still be loaded, to do so you have two options, do those steps only if you trust the source of the checkpoint.
(1) In PyTorch 2.6, we changed the default value of the `weights_only` argument in `torch.load` from `False` to `True`. Re-running `torch.load` with `weights_only` set to `False` will likely succeed, but it can result in arbitrary code execution. Do it only if you got the file from a trusted source.
(2) Alternatively, to load with `weights_only=True` please check the recommended steps in the following error message.
WeightsUnpickler error: Unsupported global: GLOBAL numpy.core.multiarray._reconstruct was not an allowed global by default. Please use `torch.serialization.add_safe_globals([_reconstruct])` or the `torch.serialization.safe_globals([_reconstruct])` context manager to allowlist this global if you trust this class/function.
Check the documentation of torch.load to learn more about types accepted by default with weights_only https://pytorch.org/docs/stable/generated/torch.load.html.
测试微调结果
在终端输入测试命令python inference_hf.py 微调模型的路径 --prompt "你的问题",比如python inference_hf.py output\checkpoint-300 --prompt "我是想现在退货,然后重新下单"

回答不稳定,本人认为是缺乏上下文或微调训练次数不够多,处于欠拟合的情况~
注:微调结束后不要改变微调前的模型文件夹,否则要修改配置文件。
创作不易,禁止抄袭,转载请附上原文链接及标题



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











