









Linux
1. 说 10 个常用的 Linux 命令
cd 切换当前目录
ls/ll 查看当前目录
scp 加密拷贝目录
cp 拷贝目录
vi 编辑文件
rm 删除文件
mkdir 创建目录
cat 正序连接文件并打印到标准输出设备
tac 倒序连接文件并打印到标准输出设备
mv 修改目录
pwd 查看当前目录
find 查找文件和目录
clear 清屏
2. Linux 系统中创建用户,用户组的命令
创建用户 useradd
创建用户组 groupadd
3. Linux 修改文件所属的命令,修改文件权限的命令
chown 修改文件所属的命令
chmod 修改文件权限的命令
4. 用户目录在哪,环境变量有几种配置方式
用户目录:
Linux 用户目录通常位于/home/username 目录下,每个用户在系统中都有一个以其用户名命名的子目录,用于存储用户的个人文件和设置
环境变量:
在用户的~/.bashrc 或~/.bash_profile 文件中添加 export 语句
在系统级别的/etc/environment 文件中设置全局环境变量
在特定应用程序的启动脚本中设置临时环境变量
5. Linux 安装软件的方式有几种,分别什么区别
使用安装包安装。
RedHat/CentOS:rpm
Debain/Ubuntu:deb
Windows:.exe,.msi
macOS:dmg
绿色版软件,解压即安装,解压就可以使用。
使用 yum 命令安装,例如 yum install wget。
使用源码编译安装,例如:Redis、Nginx 等。
6. 如何选择 Linux 操作系统版本
企业级应用:RHEL/CentOS
桌面平台:Ubuntu
开源服务器:CentOS
7. Linux 服务器之间免密是如何实现的
生成密钥
拷贝公钥
ssh 公钥检查
8. Shell 脚本第一行是什么,运行 Shell 脚本的方式有哪些,有什么区别
第一行:
#!/bin/hash
运行方式
使用路径
bash 或 sh
source 或 .
bash 或 sh 执行脚本时会新开一个 bash,不同 bash 中的变量无法共享。而 source 或 . 是在同一个 bash 里面执行的,所以变量可以共 享
9. Shell 脚本必须以 .sh 后缀结尾吗
Shell 脚本并不一定需要以 .sh 后缀结尾,但通常为了方便识别和管理,推荐使用 .sh 后缀。除了 .sh 外,Shell 脚本还可以使用其他方式结尾,例如没有后缀、.bash、.bashrc 等。但为了遵循通用惯例,建议使用 .sh 后缀。
10. Linux 查看进程的命令以及杀死进程的命令
ps 查看进程
kill 杀死进程 -9 强杀死 -15 软杀死
ZooKeeper
1. ZooKeeper 集群中有哪些角色,分别有什么作用
Leader:负责协调和管理集群状态的角色,处理客户端的请求并负责集群中各个节点之间的同步
Follower:跟随 Leader 进行状态同步的角色,处理客户端的读请求
Observer:观察者角色,不参与投票选举 Leader,也不存储数据,但能接收并同步数据,减轻 Leader 和 Follower 的负载
这些角色共同工作,确保 ZooKeeper 集群的高可用性和一致性。Leader 负责处理写请求,Follower 处理读请求,Observer 减轻了 Leader 和 Follower 的负载,提高了系统的性能和扩展性
2. 说说 ZooKeeper Znode 的特点
ZooKeeper 中的 Znode 是一个数据节点,类似于文件系统中的文件或目录
路径:每个 Znode 都有一个唯一的路径标识符。
数据:每个 Znode 可以存储一小段数据,最大为 1MB。
版本:每个 Znode 都有一个版本号,用于处理并发操作。
序列号:Znode 可能会使用序列号来区分同名节点。
临时节点:Znode 可以被标记为临时节点,当客户端断开连接时会被自动删除。
顺序节点:Znode 可以被标记为顺序节点,ZooKeeper 在创建节点时会自动为节点名称添加序列号。
Watcher:可以为 Znode 设置 Watcher,当节点的状态发生变化时会通知客户端
3. 说说 ZooKeeper 的监听通知机制
ZooKeeper 的监听通知机制主要是通过 Watcher 来实现的。Watcher 是一个回调接口,当某个节点的状态发生变化时,ZooKeeper 会通知对该节点设置了 Watcher 的客户端,客户端可以在接收到通知后进行相应的处理。
ZooKeeper 提供了对节点的创建、删除、数据更新等操作的 Watcher 机制。客户端可以在对节点进行操作时设置 Watcher,一旦节点的状态发生变化,ZooKeeper 就会向客户端发送通知。客户端在收到通知后可以根据需要更新自身的数据或重新注册 Watcher。
需要注意的是,Watcher 是一次性的,即一旦收到一次通知后就会被移除,客户端需要重新设置 Watcher 才能继续监听节点的状态变化。因此,在使用 Watcher 时需要注意及时重新注册 Watcher,以确保持续监听节点状态的变化
4. 说一下 CAP 原则以及如何选择
CAP 原则:
C:一致性,也叫做数据原子性,系统在执行某项操作后仍然处于一致的状态。在分布式系统中,更新操作执行成功后所有 的用户都应该读到最新的值,这样的系统被认为是具有强一致性的。等同于所有节点访问同一份最新的数据副本
A:可用性,每一个操作总是能够在一定的时间内返回结果,这里需要注意的是"一定时间内"和"返回结果"。一定时间内指 的是在可以容忍的范围内返回结果,结果可以是成功或者是失败,且不保证获取的数据为最新数据
P:分区容错性,分布式系统在遇到任何网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务,除非整个网 络环境都发生了故障。这里可以理解为是否可以对数据进行分区,这是考虑到性能和可伸缩性
5. ZooKeeper 的选主过程
ZooKeeper 是一个分布式协调服务,其中选主过程是指在一个 ZooKeeper 集群中选择一个节点作为 leader,负责协调集群中的各个节点之间的通信和数据同步。选主过程主要包括以下几个步骤:
初始化选主:当一个新的 ZooKeeper 集群启动时,每个节点都会尝试成为 leader。节点会争相发送选主请求(leader election request)来竞争成为 leader。
选主算法: ZooKeeper 使用一种称为 ZAB(ZooKeeper Atomic Broadcast)协议的算法来实现选主过程。在 ZAB 协议中,每个节点都有一个递增的逻辑时钟(ZXID),用于排序和同步事务。选主过程会基于这个逻辑时钟来选择 leader。
选主条件: 为了选择一个合适的 leader,ZooKeeper 集群会考虑各个节点的性能、网络延迟、数据完整性等因素。一般情况下,具有最高逻辑时钟值的节点会成为 leader。
选主结果: 一旦选主过程完成,集群中的节点将会知道谁是当前的 leader。其他节点会成为 followers,负责和 leader 进行数据同步和通信。
总的来说,ZooKeeper 的选主过程是通过 ZAB 协议实现的,节点根据逻辑时钟值来竞争成为 leader,最终选择性能最好、数据最新的节点作为 leader,确保集群中的一致性和可靠性
6. ZooKeeper 如何帮助其他组件选主
ZooKeeper 是一个分布式的协调服务,可以帮助其他组件进行主节点选举。主节点选举是分布式系统中常见的问题,通常用于确保系统中只有一个节点在某个时间点上承担特定的角色或负责特定任务,以确保系统的一致性和可靠性。
在主节点选举过程中,各个候选节点会在 ZooKeeper 中创建临时顺序节点,通过节点的顺序来确定节点的先后顺序。候选节点会监视这些节点的变化,并根据一定的策略来确定谁是最终的主节点。一般来说,最小的序号节点会被选举为主节点。
通过 ZooKeeper,组件可以实现分布式的主节点选举功能,确保系统中只有一个节点承担主节点的角色,从而保证系统的可用性和一致性。ZooKeeper 提供了高可用性和一致性的服务,使得主节点选举过程可以在分布式系统中有效进行
3. Hadoop
1. HDFS 的读取流程
HDFS(Hadoop Distributed File System)的读取流程如下:
客户端向 NameNode 发送读取请求,指定要读取的文件路径和偏移量。
NameNode 根据文件路径找到对应的数据块所在的位置信息,然后将这些信息返回给客户端。
客户端根据返回的数据块位置信息,直接与对应的 DataNode 通信,请求读取数据块。
DataNode 接收到客户端的读取请求后,从本地存储中读取对应的数据块,并将数据块传输给客户端。
客户端接收到数据块后,将数据块缓存在本地,并进行后续的数据处理或分析操作。
需要注意的是,HDFS 采用了主动数据复制的机制,即每个数据块会被复制到多个 DataNode 上,以提高数据的可靠性和容错性。因此,在读取数据时,客户端可能会与多个 DataNode 进行通信,以实现数据的并行读取
2. HDFS 的写入流程
HDFS(Hadoop 分布式文件系统)是用于存储大规模数据的分布式文件系统。在 HDFS 中,写入数据的流程如下:
客户端向 NameNode 请求写入数据,NameNode 会返回一个适合写入数据的 DataNode 列表。
客户端开始写入数据到第一个 DataNode,并且同时向第一个 DataNode 发送数据副本的请求。
第一个 DataNode 接收到数据后,会将数据写入本地磁盘,并且将数据副本复制到其他 DataNode。
其他 DataNode 接收到数据副本后,也会将数据写入本地磁盘。
当数据写入完成后,客户端会向 NameNode 发送写入完成的请求。
NameNode 会更新元数据信息,标记该文件的写入操作已完成。
整个写入过程是在多个 DataNode 之间并行进行的,从而提高写入性能和数据的容错性。数据的冗余备份也保证了数据的可靠性,即使某个 DataNode 发生故障,数据仍然可以从其他 DataNode 中恢复
3. 阐述 MapReduce 的计算流程
原始数据 File
数据块 Block
切片 Split
MapTask
环形数据缓冲区
排序 Sort
溢写 Spill
合并 Merge
组合器 combiner
拉取 Fetch
合并 Merge
归并 Reduce
写出 Output
4. 阐述 YARN 集群的工作流程
1. 提交应用程序:
用户提交应用程序到YARN集群。
2. 资源申请:
应用程序向ResourceManager申请资源(包括CPU、内存、磁盘等资源),同时指定运行该应用程序的ApplicationMaster。
3. 分配资源:
ResourceManager根据应用程序的资源需求,从集群资源池中分配适当的资源,向ApplicationMaster分配它所需要的Container。
4. 启动ApplicationMaster:
ResourceManager通知NodeManager启动ApplicationMaster,并分配给它一个Container。
5. Container启动:
ApplicationMaster接收到资源分配信息后,向NodeManager发送启动Container的请求,NodeManager启动Container。
6. 应用程序执行:
Container内部运行应用程序,在完成任务后将输出结果写入指定的存储介质。
7. Container释放:
任务执行完毕后,Container将被释放,资源被返回到ResourceManager的资源池中,可以被其他应用程序使用。
8. 应用程序结束:
应用程序执行完毕后,ResourceManager释放它所使用的资源,应用程序结束。
5. 为什么会产生 YARN 它解决了什么问题
YARN(Yet Another Resource Negotiator)是 Apache Hadoop 生态系统中的一个资源管理和调度框架。它被引入主要是为了克服第一代 Hadoop MapReduce 框架中的一些限制和问题。以下是 YARN 产生的原因及它解决的问题:
1. **资源管理的局限性
在 Hadoop 1.x 中,资源管理和作业调度都是由 JobTracker 负责的,这导致了以下问题:
- 单点瓶颈:JobTracker 既负责资源管理,又负责任务调度和监控,容易成为性能瓶颈。
- 可扩展性问题:随着集群规模的扩大,JobTracker 需要管理更多的任务和节点,导致性能下降和可靠性问题。
- 资源利用率低:由于 MapReduce 作业的固定资源分配方式,资源利用率不高,难以适应不同作业的需求。
2. **框架的灵活性不足
Hadoop 1.x 的 MapReduce 框架是为批处理任务设计的,这限制了它在不同类型的计算任务中的适用性。例如,实时处理、流处理和交互式查询等任务在 MapReduce 框架中难以高效执行。
YARN 解决的问题
1. 分离资源管理和作业调度
YARN 将资源管理和作业调度分离成两个独立的组件:
- ResourceManager:负责整个系统的资源管理和分配。
- NodeManager:负责每个节点上的资源管理和任务执行。
通过这种分离,YARN 提高了系统的可扩展性和可靠性。
2. 提高资源利用率
YARN 引入了基于容器(Container)的资源分配机制,可以根据不同作业的需求动态分配资源,从而提高资源利用率。
3. 支持多种计算框架
YARN 的设计使其不仅支持 MapReduce,还支持其他类型的计算框架,如 Apache Tez、Apache Spark、Apache Flink 等。这大大提高了 Hadoop 生态系统的灵活性和适用性。
4. 提高系统的可扩展性和性能
由于 ResourceManager 和 NodeManager 的分离,YARN 可以更好地扩展以支持大型集群。同时,YARN 的调度机制使得资源分配更加高效,从而提高了整体性能。
5. 增强的容错性
YARN 的设计增强了系统的容错性。例如,当某个 NodeManager 失败时,ResourceManager 可以将任务重新分配到其他节点,从而提高了系统的可靠性。
通过这些改进,YARN 不仅解决了 Hadoop 1.x 中存在的资源管理和调度问题,还使得 Hadoop 生态系统能够更好地支持不同类型的计算任务,成为一个更加通用和灵活的大数据处理平台
6. Hadoop MR 模型中数据倾斜一般是在 Mapper 端发生的还是在 Reducer 端发生的,为什么?
MR模型中数据倾斜一般是在Reducer端发生的
数据倾斜在Reduce端出现的原因有很多种可能性:
1.数据分布不均匀:
在MapReduce中,Mapper输出的数据会被基于Key被分组并发送到Reduce进行处理,如果某些key的数据量显著大于其他key,那么某些Reduce会收到更多数据,从而导致处理时间长,而其他Reduce处理完数据后可能就处于空闲状态。
2.Shuffle阶段:
Shuffle是MapReduce中Map任务和Reduce任务之间的过程,其中数据被排序和传输。再次阶段,数据是基于key进行排序和分组的,然后将相同的key的数据发送到同一个Reduce,这个过程使得数据倾斜问题可能性增大,因为相同的key值会被集中在一起。
3.固定的Reduce数量:
在MapReduce作业中,Reduce的数量是固定的,因此,即使某些Key有大量的值,它们仍然会被发送到一个Reduce上,而不是分散到多个Reduce上。
4.自定义Partition的问题:
Partitioner决定了数据如何分布到各个Reducer,一个不恰当的PArtitioner可能导致某些Reducer收到的数据明显多余其他Reducer。
5.Mapper的输出不均:
虽然数据倾斜问题在Reducer端更为明显,但问题可能源于Mapper的输出。如果Mapper输出的数据分布不均,或某些key特别多,那么在Reduce阶段这种倾斜就会被放大。
为了解决数据倾斜问题,可以采取以下一些策略:
1.Combiner函数:在Map阶段使用Combiner函数进行局部聚合,减少输出到Reduce阶段的数据量,从而降低数据倾斜的可能性。
2.数据重分区:通过自定义Partitioner,将数据重新分配到不同的Reduce任务中,使得数据更加均匀地分布在各个任务上。
3.增加Reduce任务数:增加Reduce任务的数量,使得数据更细粒度地分布在更多地任务中,减轻单个任务的负载。
4.二次排序:如果数据倾斜是由于键的选择导致的,可以考虑对键进行二次排序,将相似的键值对聚集在一起,减少数据倾斜的可能性。
5.动态调整任务负载:监控任务执行情况,在运行时动态调整任务的负载,将负载过重的任务重新分配到其他节点上,实现负载均衡
-
Hadoop 常用的压缩算法有哪些,有什么区别
图片: https://uploader.shimo.im/f/76C3SetooiaejmFg.png!thumbnail?accessToken=eyJhbGciOiJIUzI1NiIsImtpZCI6ImRlZmF1bHQiLCJ0eXAiOiJKV1QifQ.eyJleHAiOjE3MTc1ODc4MjQsImZpbGVHVUlEIjoiQjFBd2ROYm94YnRSMXYzbSIsImlhdCI6MTcxNzU4NzUyNCwiaXNzIjoidXBsb2FkZXJfYWNjZXNzX3Jlc291cmNlIiwidXNlcklkIjo5NDI5MTQ1NX0.sknsBdBnMNRyqmtYbhc86Ypt6fP05Fib5gsYrkuViWI -
Hadoop MR 模型中哪些地方可以进行优化
在 Hadoop MapReduce 模型中,以下是一些可以进行优化的地方:
数据压缩:在数据传输和存储过程中使用压缩可以减少数据量,提高整体性能。
数据本地化:尽可能将计算任务分配给存储有相关数据的节点,减少数据传输和提高计算效率。
合适的数据划分:根据数据的特性选择合适的划分方法,避免数据倾斜和不均匀的情况。
合理的任务调度:根据集群资源的使用情况和任务的优先级进行合理的任务调度,避免资源浪费和任务阻塞。
合适的 Reducer 数量:根据数据规模和计算需求选择合适的 Reducer 数量,避免资源的浪费和性能下降。
使用 Combiner 函数:在 Map 阶段执行 Combiner 函数可以减少数据传输量,加快计算速度。
使用 Partitioner:自定义 Partitioner 可以使数据更加均匀地分配给不同的 Reducer,提高整体性能。
优化代码逻辑:优化 Map 和 Reduce 函数的逻辑,避免不必要的计算和数据处理,提高执行效率。
以上是一些常见的 Hadoop MapReduce 模型优化方法,根据具体场景和需求可以进一步深入优化
4. Hive
1. Hive SQL 的执行流程
Hive SQL 的执行流程大致如下:
编写 Hive SQL 查询语句:用户首先编写 Hive SQL 查询语句,定义数据处理逻辑和操作。
解析查询语句:Hive 会解析用户输入的查询语句,检查语法,语义和逻辑正确性,并生成对应的逻辑执行计划。
生成 MapReduce 任务(或 Tez、Spark 等):根据查询语句生成的逻辑,执行计划,Hive 会将其转换为 MapReduce 任务(或其他计算引擎支持的任务),并提交给对应的计算引擎执行。
任务执行:计算引擎接收到任务后,会进行任务的划分、调度和执行,根据数据存储位置和计算逻辑在集群上进行数据处理。
数据读取和写入:在任务执行过程中,会涉及到数据的读取和写入,读取源数据、计算中间结果和写入最终结果。
返回结果:一旦任务执行完成,计算引擎会将结果返回给 Hive,然后 Hive 会将结果返回给用户。
图片: https://uploader.shimo.im/f/vYv8FuEi4ykyQECg.png!thumbnail?accessToken=eyJhbGciOiJIUzI1NiIsImtpZCI6ImRlZmF1bHQiLCJ0eXAiOiJKV1QifQ.eyJleHAiOjE3MTc1ODc4MjQsImZpbGVHVUlEIjoiQjFBd2ROYm94YnRSMXYzbSIsImlhdCI6MTcxNzU4NzUyNCwiaXNzIjoidXBsb2FkZXJfYWNjZXNzX3Jlc291cmNlIiwidXNlcklkIjo5NDI5MTQ1NX0.sknsBdBnMNRyqmtYbhc86Ypt6fP05Fib5gsYrkuViWI
2. Hive 自定义函数的流程,有什么作用
Hive 自身已经提供了非常丰富的函数,比如:COUNT/MAX/MIN 等,但是数量与功能有限,如果无法满足需求,可以 通过自定义函数来进行扩展
自定义函数分为三种:
UDF(User Defined Function):普通函数,一进一出,比如 UPPER, LOWER
UDAF(User Defined Aggregation Function):聚合函数,多进一出,比如 COUNT/MAX/MIN
UDTF(User Defined Table Generating Function):表生成函数,一进多出,比如 LATERAL VIEW EXPLODE()
3. 说一说 Hive 的分区分桶
分区(Partition):
分区是将表数据按照某个列的值进行划分存储的方式。通过分区,可以将数据按照某个列的不同取值分别存放在不同的目录下,这样可以提高查询效率,特别是在对分区键进行过滤的查询操作中。可以使用 PARTITIONED BY 关键字来定义分区列
使用分区技术,可以避免 Hive 全表扫描,提升查询效率;同时能够减少数据冗余进而提高特定(指定分区)查询分析的效率
分区表类型分为静态分区和动态分区。区别在于前者是我们手动指定的,后者是通过数据来判断分区的。根据分区的 深度又分为单分区与多分区
静态分区与动态分区的主要区别在于静态分区是手动指定,而动态分区是通过数据来判断分区的。详细来说,静态分 区的列是在编译时期通过用户传递来决定的;动态分区只有在 SQL 执行时才能决定
分桶(Bucket):
分桶是将表数据按照 hash 函数的结果划分成若干个桶进行存储的方式。分桶可以将数据均匀分布到不同的桶中,这样可以提高数据的查询和聚合性能。可以使用 CLUSTERED BY 关键字来定义分桶列,并指定分桶的数量
分区针对的是数据的存储路径,分桶针对的是数据文件
Hive 采用对列值哈希,然后除以桶的个数求余的方式决定该条记录要存放在哪个桶中
方便抽样:使抽样(Sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小 部分数据上试运行查询,会带来很多方便。
提高 JOIN 查询效率:获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理某些查询的时能利用这个结 构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side Join)高效的 实现。比如 JOIN 操作。对于 JOIN 操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列 值的桶进行 JOIN 操作就可以,可以大大较少 JOIN 的数据量
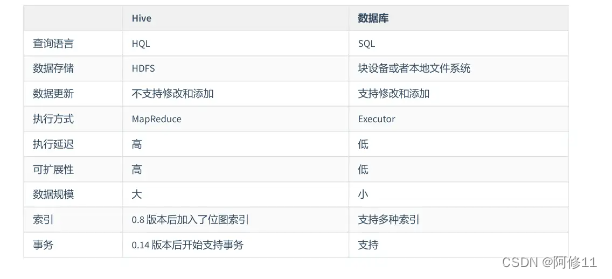
4. Hive 和传统数据库的区别
Hive 和传统数据库之间有一些重要的区别,主要包括以下几点:
数据处理方式:Hive 是建立在 Hadoop 平台上的数据仓库工具,主要用于大数据处理和分析。它使用类似于 SQL 的查询语言来处理数据,但是它在底层是通过 MapReduce 或 Tez 这样的分布式计算框架来执行查询的。传统数据库则是使用结构化查询语言(SQL)来处理数据,通常是在单个服务器上执行。
数据类型支持: 传统数据库通常支持各种数据类型,包括整数、浮点数、字符串等。而 Hive 更适合处理大数据,支持更多的数据类型和复杂的数据结构,比如数组、map、struct 等。
存储方式: 传统数据库通常使用行存储来存储数据,而 Hive 使用列存储来存储数据,这使得它更适合于分析查询,因为可以只读取需要的列而不是整行。
扩展性: 由于 Hive 是建立在 Hadoop 这样的分布式系统上的,因此它可以轻松地扩展到数千台服务器上处理大规模数据。传统数据库在扩展性方面可能会受到服务器性能或存储容量的限制。
总的来说,Hive 更适合于大规模数据处理和分析,而传统数据库更适合于事务处理和实时查询。在选择使用哪种工具时,应根据具体的需求和数据规模来进行权衡
5. Hive 的物化视图和视图有什么区别
视图:
是一个虚拟的表,只保存定义,不实际存储数据,实际查询的时候改写 SQL 去访问实际的数据表。不同于直接 操作数据表,视图是依据 SELECT 语句来创建的,所以操作视图时会根据创建视图的 SELECT 语句生成一张虚拟表,然后在 这张虚拟表上做 SQL 操作

物化视图:
物化视图 Materialized View,是一个包括查询结果的数据库对象,可以用于预先计算并保存表连接或聚集等耗时较多的操作结果。
在执行查询时,就可以避免进行这些耗时的操作,从而快速的得到结果。 使用物化视图的目的就是通过预计算,提高查询性能,所以需要占用一定的存储空间。Hive 还提供了物化视图的查询 自动重写机制(基于 Apache Calcite 实现)和物化视图存储选择机制,可以本地存储在 Hive,也可以通过用户自定义 Storage Handlers 存储在其他系统(如 Apache Druid)
物化视图只可以在事务表上创建
6. Hive 内部表和外部表的区别
Hive 中的内部表(Managed Table)和外部表(External Table)有以下几点区别:
存储位置管理:
内部表的数据由 Hive 管理,数据存储在 Hive 指定的位置,当删除表时,数据也会被删除。
外部表的数据不由 Hive 管理,数据可以存储在任何位置,删除外部表时只会删除表的元数据,而不会删除实际数据。
数据保护:
内部表在删除表时会删除数据,因此可能会导致数据丢失。
外部表在删除表时只删除元数据,不会删除数据,所以数据是安全的。
表的备份和恢复:
内部表的备份和恢复比较简单,可以直接备份整个表目录。
外部表的备份和恢复需要额外的步骤来确保数据的完整性。
数据管理:
内部表适用于管理 Hive 所有的数据,更适合用于数据仓库等场景。
外部表适用于在 Hive 中使用外部数据(如 HDFS 文件),更适合用于数据集成和数据共享等场景。
总的来说,内部表适合在 Hive 中进行数据的管理和处理,而外部表适合在 Hive 中引用外部数据源并与之交互
7. Hive 导出数据有几种方式
通过 SQL 操作
将查询结果导出到本地
将查询结果输出到 HDFS
通过 HDFS 操作
将元数据和数据同时导出
8. Hive 动态分区和静态分区有什么区别
静态分区与动态分区的主要区别在于静态分区是手动指定,而动态分区是通过数据来判断分区的。详细来说,静态分 区的列是在编译时期通过用户传递来决定的;动态分区只有在 SQL 执行时才能决定
9. Hive 的 sort by、order by、distrbute by、cluster by 的区别
Sort by:
Sort by 是在查询结果中对数据进行排序的关键字,它会对最终输出的结果进行排序,但并不会改变数据的物理存储顺序。Sort by 可以在查询的最后使用,以实现对结果进行排序。
Order by:
Order by 也是用于对最终输出结果进行排序,与 Sort by 类似,但 Order by 会进行全局排序,可能会导致性能问题,特别是当数据量较大时。Order by 通常用于要求全局有序的场景。
Distribute by:
Distribute by 是用于在 Map 阶段将数据分发到不同的 Reduce Task 中的关键字。它定义了数据分片的方式,可以根据指定的列或表达式将数据分发到不同的 Reduce Task 中,以实现数据分布的控制。
Cluster by:
Cluster by 是在创建表时用于定义数据的物理存储顺序的关键字。它会对表中的数据按照指定的列进行排序,并按照这个顺序存储数据。这样可以提高查询性能,特别是对于经常按照某个列排序的查询。
总结:
Sort by 和 Order by 是用于对查询结果进行排序的关键字,Sort by 是在查询结果中排序,而 Order by 是全局排序;
Distribute by 用于数据分发到 Reduce Task 中的控制;
Cluster by 用于定义数据的物理存储顺序
10. 行式文件和列式文件的区别
行式文件和列式文件是在数据存储和组织方面的两种不同方式。
行式文件存储数据是按照记录行的方式存储的,每一行记录包含了多个字段。这种方式类似于关系型数据库的存储方式,例如 CSV 文件就是一种行式文件。行式文件适合于对整行记录进行读取和处理,但当需要对单个字段进行查询或处理时,效率可能较低。
列式文件则是将数据按照列的方式存储,每一列包含了相同类型的数据。这种方式适合于对单个字段进行查询和处理,因为可以只读取需要的列数据而不必读取整行记录。列式文件通常用于大数据分析和处理领域,比如 Parquet 和 ORC 格式就是列式文件的代表。
因此,行式文件适合整行记录的读取和处理,而列式文件适合单个字段的查询和处理。选择哪种方式取决于具体的应用场景和需求
11. 说一说常见的 SQL 优化
RBO 优化:
Rule-Based Optimization,简称 RBO:基于规则优化的优化器,是一种经验式、启发式的优化思路,优化规则都已经 预先定义好了,只需要将 SQL 往这些规则上套就可以
谓词下推
列裁剪&常量替换
列裁剪(Column Pruning):表示扫描数据源的时候,只读取那些与查询相关的字段
常量替换:表示将表达式提前计算出结果,然后使用结果对表达式进行替换
CBO 优化:
CBO(Cost-Based Optimization)意为基于代价优化的策略,它需要计算所有可能执行计划的代价,并挑选出代价最小的执行计划
JOIN 优化
小表 JOIN 大表的 Map Join
大表 JOIN 大表的 Reduce Join,Reduce Join 又分为以下两种:
Bucket Map Join(中型表和大表 JOIN)
Sort Merge Bucket Join(大表和大表 JOIN)
Map Join:
Map Join 顾名思义,就是在 Map 阶段进行表之间的连接。而不需要进入到 Reduce 阶段才进行连接。这样就节省了 在 Shuffle 阶段时要进行的大量数据传输
Map Join 简单说就是在 Map 阶段将小表读入内存,顺序扫描大表完成 Join
Reduce Join:
Map 端的主要工作:为来自不同表或文件的 key/value 对,打标签以区别不同来源的记录。然后用连接字段作为 Key,其余部分和新加的标志作为 Value,最后进行输出
Reduce 端的主要工作:在 Reduce 端以连接字段作为 Key 的分组已经完成,我们只需要在每一个分组当中将那些来源 于不同文件的记录进行合并即可
Bucket Map Join:
大表对小表应该使用 Map Join 来进行优化,但是如果是大表对大表,如果进行 Shuffle,那就非常可怕,第一个慢不 用说,第二个容易出异常
12. 根据现阶段所学知识总结一下产生数据倾斜的原因
压缩引发的数据倾斜
单表数据倾斜优化
JOIN 数据倾斜优化 Map JOIN 大小表 JOIN
业务无关数据引发的数据倾斜
无法消减中间结果的数据量引发的数据倾斜
多维聚合计算数据膨胀引起的数据倾斜
13. 说一说 Hive 你知道的优化
使用分区表:将数据按照特定的字段进行分区存储,可以加快查询速度,减少扫描的数据量。
合理设计表结构:避免使用过多的小文件,合理选择数据类型和分区字段,减少不必要的数据转换和计算。
建立索引:对于经常用于查询的字段,可以建立索引来加速查询。
数据压缩:使用压缩格式来减少存储空间并提高 IO 性能。
使用 Tez 或 Spark 引擎:这些执行引擎可以优化查询计划,并提高查询性能。
调整配置参数:根据实际情况调整 Hive 的配置参数,如内存大小、并行度等。
5. HBase
1. RowKey 如何设计,设计不好会产生什么后果
RowKey 的概念与关系型数据库中的主键相似,是一行数据的唯一标识。RowKey 可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100 Bytes),RowKey 以字节数组保存。存储数据时,数据会按照 RowKey 的字典序排序 存储,所以设计 RowKey 时,要充分利用排序存储这个特性,将经常一起读取的行存放到一起
RowKey 是 Azure Table Storage 中用于唯一标识每个实体的键。设计 RowKey 时需要考虑以下几点:
唯一性: RowKey 必须在同一分区内是唯一的,确保不会出现重复的 RowKey。
查询效率: RowKey 的设计应该能够提高数据的查询效率,通常会根据查询需求来选择合适的 RowKey 设计。
排序: RowKey 可以用于对实体进行排序,如果需要对数据进行范围查询或排序操作,需要考虑如何设计 RowKey 来满足这些需求。
设计不好的 RowKey 可能会导致以下后果:
数据分布不均匀: 如果 RowKey 设计不合理,可能会导致数据在表中分布不均匀,影响查询性能。
查询效率低下: 如果 RowKey 没有按照查询需求进行合理设计,可能会导致查询效率低下,需要扫描大量数据才能找到需要的实体。
难以维护和管理:设计不合理的 RowKey 可能会导致数据管理和维护变得困难,增加系统的维护成本。
因此,在设计 RowKey 时需要综合考虑唯一性、查询效率和排序等因素,确保能够提高数据存储和查询的效率
HBase 的 RowKey 设计需要遵循以下原则:
唯一原则: 单主键 组合主键(注意顺序)
长度原则: 不要超过 16 个字节 对齐 RowKey 长度
散列原则: 反转 加盐 Hash
2. 列族如何设计,为什么不建议 HBase 设计过多列族
追求原则: 在合理范围内,尽可能的减少列族。
最优设计: 将所有相关性很强的 key-value 都放在同一个列族。这样既能做到查询效率最高,也能保证尽可能少的访 问不同的磁盘文件。
控制长度: 列族名的长度要尽量小,一个为了节省空间,一个为了加快效率,最好是一个字符,比如 d 表示 data 或 default,v 表示 value
从HBase底层原理解析HBASE列族不能设计太多的原因?-腾讯云开发者社区-腾讯云 (tencent.com)
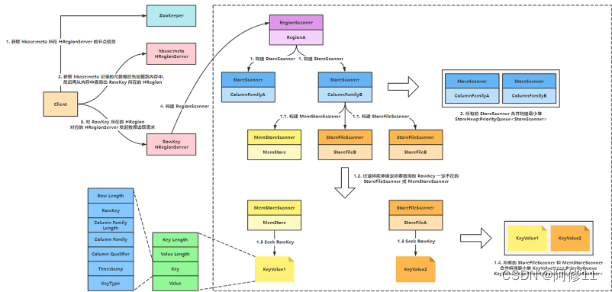
- HBase 读取数据的流程

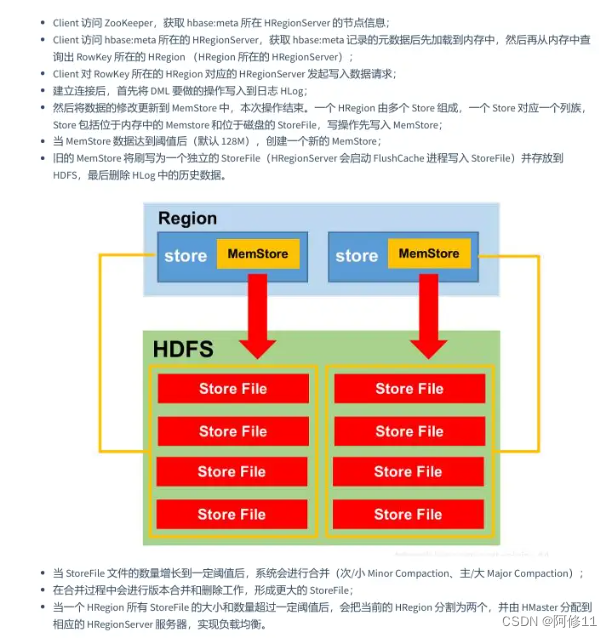
- HBase 写入数据的流程
5. Hive 和 HBase 的区别
Hive 和 HBase 是两种常用的大数据存储技术,它们有以下几点区别:
数据模型:
Hive:Hive 是基于 SQL 的数据仓库工具,它将结构化的数据映射到 Hadoop 文件系统中,并使用类似 SQL 的查询语言来查询和分析数据。
HBase:HBase 是一个分布式的、面向列的 NoSQL 数据库,适用于快速随机读/写大规模数据。它提供了高可用性、高性能和强一致性。
数据存储方式:
Hive:Hive 将数据存储在 HDFS 中,适合用于批量处理大规模数据。
HBase:HBase 将数据存储在 HDFS 上的 HBase 文件系统中,支持实时随机读/写操作。
数据访问方式:
Hive:Hive 提供了类似 SQL 的查询语言,适合用于复杂的数据分析和查询。
HBase:HBase 提供了对单行或单列的高效随机读/写操作,适合用于实时访问和交互式应用。
数据处理能力:
Hive:Hive 适合用于批量处理和离线分析,对于实时查询性能较差。
HBase:HBase 适合用于实时查询和快速随机读写,对于复杂聚合查询性能可能较低。
总的来说,Hive 更适合用于大规模数据的批量处理和复杂查询分析,而 HBase 更适合用于实时访问和随机读写大规模数据。在实际应用中,通常会根据具体需求和场景选择使用哪种技术或者两者结合使用
6. 为什么要使用 Phoenix
- 构建在 HBase 上的 SQL 层
- 可以使用标准 SQL 在 HBase 中管理,便于开发
- 可以使用 JDBC 来创建表,插入数据、对 HBase 数据进行查询
- Phoenix JDBC Driver 容易嵌入到支持 JDBC 的程序中
7. HBase 的热点区域会产生什么问题
HBase 的热点区域是指在表中某些行或列族上产生了过多的读取或写入操作,导致该区域受到过度访问的情况。这可能会导致以下问题:
性能瓶颈: 热点区域的高访问频率会导致该区域的服务器负载过高,降低整体系统的性能。
数据不均衡: 由于热点区域的存在,数据库中的数据分布不均匀,导致某些区域的数据存储过载,而其他区域却相对空闲。
单点故障:如果热点区域的服务器出现故障,可能会导致整个区域的数据不可用。
数据不一致: 由于热点区域的高访问频率,可能会导致数据写入操作发生冲突,造成数据不一致的情况。
为了避免这些问题,可以采取一些措施来缓解热点区域的影响,例如使用缓存、数据分片、负载均衡等技术来平衡数据访问
8. 说一说 HBase 的数据刷写与合并
数据刷写
当某个memstore的大小达到了hbase.hregion.memstore.flush.size(默认值128M),其所在region的所有memstore都会刷写。当memstore的大小达到了hbase.hregion.memstore.flush.size(默认值128M) hbase.hregion.memstore.block.multiplier(默认值4)时,会阻止继续往该memstore写数据。
当region server中memstore的总大小达到java_heapsize*hbase.regionserver.global.memstore.size(默认值0.4)
hbase.regionserver.global.memstore.size.lower.limit(默认值0.95),region会按照其所有 memstore的大小顺序(由大到小)依次进行刷写。直到region server中所有memstore的总大小减小到上述值以下。当region server中memstore的总大小达到java_heapsizehbase.regionserver.global.memstore.size(默认值0.4)时,会阻止继续往所有的memstore写数据。
到达自动刷写的时间,也会触发memstore flush。自动刷新的时间间隔由该属性进行配置hbase.regionserver.optionalcacheflushinterval(默认1小时)。
当WAL文件的数量超过hbase.regionserver.max.logs,region会按照时间顺序依次进行刷写,直到WAL文件数量减小到hbase.regionserver.max.log以下(该属性名已经废弃,现无需手动设置,最大值为32)。
合并
Minor Compaction(次要/小)
选取一些小的、相邻的 StoreFile 将他们合并成一个更大的 StoreFile,在这个过程中不做任何删除数据、多版本数据的 清理工作,但是会对 minVersion=0 并且设置 TTL 的过期版本数据进行清理。一次 Minor Compaction 的结果是让小的 StoreFile 变的更少并且产生更大的 StoreFile
Major Compaction(主要/大)
将所有的 StoreFile 合并成一个 StoreFile 清理三类无意义数据:被删除的数据、TTL 过期数据、版本号超过设定版本号 的数据。一般情况下,Major Compaction 时间会持续比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影 响。因此线上业务都会关闭自动触发 Major Compaction 功能,改为手动在业务低峰期触发
Minor Compaction:快速让小文件合并成大文件
Major Compaction:清理大文件不必要的数据,释放空间
合并时机
触发 Compaction 的方式有三种:MemStore 刷盘、后台线程周期性检查、手动触发
MemStore 刷盘 MemStore Flush 会产生 HFile 文件,文件越来越多就需要 Compact。每次执行完 Flush 操作之后,都会对当前 Store 中 的文件数进行判断,一旦文件数大于配置,就会触发 Compaction。Compaction 都是以 Store 为单位进行的,整个 HRegion 的所有 Store 都会执行 Compact。
周期性检查 后台线程定期触发检查是否需要执行 Compaction,检查周期可配置。线程先检查文件数是否大于配置,一旦大于就 会触发 Compaction。如果不满足,它会接着检查是否满足 Major Compaction 条件(默认 7 天触发一次,可配置手动触 发)。周期性检查线程 CompactionChecker 大概 2hrs 46mins 40sec 执行一次。
手动执行 一般来讲,手动触发 Compaction 通常是为了执行 Major Compaction,一般有这些情况需要手动触发合并: 因为很多业务担心自动 Major Compaction 影响读写性能(可以选择直接关闭),因此会选择低峰期手动触发; 用户在执行完 alter 操作之后希望立刻生效,手动执行触发 Major Compaction;HBase 管理员发现硬盘容量不够的情况下手动触发 Major Compaction 删除大量过期数据。
6. Scala
1. Scala 中,函数是一等公民具体体现在哪里
在 Scala 中,函数是一等公民的概念体现在以下几个方面:
函数可以被存储在变量中: 在 Scala 中,可以将函数赋值给变量,并且将这些函数作为变量传递给其他函数或者作为函数的返回值返回。这样可以更灵活地操作函数。
函数可以作为参数传递: 在 Scala 中,函数可以作为参数传递给其他函数。这样可以实现高阶函数,即接受一个或多个函数作为参数的函数。
函数可以作为返回值返回:在 Scala 中,函数可以作为其他函数的返回值返回。这种方式可以实现函数的嵌套调用,进一步增强了函数的灵活性。
函数可以匿名定义: 在 Scala 中,可以通过匿名函数的方式来定义函数,也就是不需要给函数命名,直接传递函数体。这种方式通常在需要使用函数临时的地方比较方便。
综上所述,函数是一等公民意味着在 Scala 中函数具有和其他数据类型一样的地位,可以像操作数据一样操作函数,从而实现更加灵活和强大的编程方式
2. 说说 Scala 函数的至简原则
-
方法和函数不建议写 return 关键字,Scala 会使用函数体的最后一行代码作为返回值;
-
方法的返回值类型如果能够推断出来,那么可以省略,如果有 return 则不能省略返回值类型,必须指定;
-
因为函数是对象,所以函数有类型,但函数类型可以省略,Scala 编译期可以自动推断类型; 如果方法明确声明了返回值为 Unit,那么即使方法体中有 return 关键字也不起作用;
-
如果方法的返回值类型为 Unit,可以省略等号=;
-
如果函数的参数类型如果能够推断出来,那么可以省略;
-
如果方法体或函数体只有一行代码,可以省略花括号{};
-
如果方法无参,但是定义时声明了(),调用时小括号()可省可不省;
-
如果方法无参,但是定义时没有声明(),调用时必须省略小括号();
-
如果不关心名称,只关心逻辑处理,那么函数名可以省略。也就是所谓的匿名函数;
-
如果匿名函数只有一个参数,小括号()和参数类型都可以省略,没有参数或参数超过一个的情况下不能省略();
-
如果参数只出现一次,且方法体或函数体没有嵌套使用参数,则参数可以用下划线_来替代。
7. Spark
1. 说 10 个常用的 Spark 转换算子
map
将处理的数据逐条进行映射转换,将返回值构成新的 RDD。这里的转换可以是类型的转换,也可以是值的转换
flatMap
函数作用于集合中的每个元素,然后将结果展平,返回新的集合。先 map,再 flatten
groupBy(shuffle)
分组是指将数据按指定条件进行分组,从而方便我们对数据进行统计分析。按照传入函数的返回值进行分组,将相同 的 Key 对应的值放入一个迭代器中。使用 groupBy 算子后数据会被打乱重新组合,我们将这样的操作称之为 Shuffle
filter
过滤是指过滤出符合一定条件的元素。将数据根据指定的规则进行筛选过滤,符合规则的数据保留,不符合规则的数 据丢弃。当数据进行筛选过滤后,分区不变,但是分区内的数据可能不均衡,生产环境下,可能会出现数据倾斜
sample
采样就是从大量的数据中获取少量的数据,获取的方法可以依据某种策略,得到的数据用于分析,企图使用少量数据 的分析结果代替全局
distinct(shuffle)
将数据集中重复的数据去重。Scala 的 distinct 底层采用了 HashSet 的方式,而 Spark 的 distinct 则是采用了 map reduceByKey map 的方式进行去重
repartition(shuffle)
重新分配分区数,一定会产生 Shuffle 操作,底层就是调用了 coalesce
sortBy(shuffle)
sortBy 函数可以根据指定的规则对数据源中的数据进行排序,默认为升序,该函数会产生 Shuffle 操作
partitionBy(shuffle)
将数据按照指定分区数重新进行分区,Spark 默认采用 HashPartitioner
sortByKey(shuffle)
将 K, V 格式数据的 Key 根据指定的规则进行排序,默认为升序。如果 Key 是元组,如 (x1, x2, x3, …),会先按照 x1 排 序,若 x1 相同,再按 x2 排序,依次类推。sortByKey 同样是来自 PairRDDFunctions 的函数
reduceByKey(shuffle)
将相同 Key 的值聚合到一起,Reduce 任务的个数可以通过 numPartitions 参数来设置。reduceByKey 同样是来自 PairRDDFunctions 的函数
groupByKey(shuffle)
按 K, V 格式数据的 Key 进行分组,会返回 (K, Iterable[V]) 格式数据。groupByKey 同样是来自 PairRDDFunctions 的函数
aggregateByKey(shuffle)
刚才学习的 reduceByKey 还有一个特点就是分区内和分区间的计算逻辑必须一致,那不一致的案例是怎样的呢?例如 前面学习的 glom 算子的案例练习:计算每个分区的最大值(分区内),再求所有分区的最大值总和(分区间)。
但是 glom 算子的案例练习还搭配了 map 算子才实现了最终需求,所以 Spark 为了让程序员更方便的使用,提供了 aggregateByKey 算子,该算子无需搭配其他算子就可以实现分区内和分区间不同的计算逻辑。aggregateByKey 同样是来自 PairRDDFunctions 的函数。
join
在类型为 K, V 和 K, W 的 RDD 上调用,返回一个相同 Key 对应的所有元素对在一起的 K, (V, W) 的 RDD
2. 说几个高效算子,并说明为什么高效
使用 ReduceByKey 代替 GroupByKey
ReduceByKey 先在分区内进行预聚合,减少落盘的数据量
使用 MapPartiton 代替 Map
MapPartition 一次会处理一个分区的数据,而不是一次只处理一条,性能相当于来说会更高一些
使用 ForeachPartiton 代替 Foreach
在 Foreach 中,每个元素都要执行一次指定的函数,而 ForeachPartiton 则是对一个分区执行一次指定的函数,在某些情况下性能更高
3. 如果让你编码,如何实现 distinct 算子的功能
- 读取输入数据
- 建立哈希表用于存储已经出现过的元素。
- 迭代处理数据:
对于每个输入元素,判断该元素是否已经存在于哈希表中。
如果该元素已经存在于哈希表中,表示重复元素,跳过该元素。
如果该元素不在哈希表中,表示新的元素,将该元素添加到哈希表中,并输出该元素。 - 将去重后的元素作为输出结果。
用 map-reduceByKey-map 实现 distinct
1 通过 map 将元素变成 元素 -> null 的元组
2 通过 reduceByKey 将去重
3 map 还原
4. 说几个 spark-submit 提交应用的参数,并说明其作用
–class:指定【主类】
–master:指定【运行模式和资源管理器】
–deploy-mode:指定【部署模式】,可以是 client 或 cluster
–executor-memory:指定【Executor 内存大小】
–num-executors:指定【Executor 数量】
–executor-cores:指定【Executor CPU 核心数】
–files:指定【文件】
–jars:指定【jar 包】
5. Hadoop MR 的 Shuffle 和 Spark Shuffle 的区别
1 Hadoop 是做完一个数据拉一个放内存里,等全部完成在聚合;Spark 是在拉取的时候就开始聚合,不用等全部完成
2 Hadoop shuffle 数据通过磁盘写入;Spark shuffle 数据写入内存,内存不够时写入磁盘
3 Hadoop shuffle 通过 HTTP 协议传输数据;Spark shuffle 通过 NIO 传输协议
4 Hadoop shuffle 使用分区器进行分区;Spark shuffle 默认使用哈希分区
6. Spark SQL 的执行流程
- sqlParser 解析 SQL,生成未解析的逻辑计划
- 由 Analyzer 结合 Catalog 信息生成解析的逻辑计划
- Optimizer 根据预先定义好的规则(RBO),对 Resolved Logical Plan 进行优化并生成优化后的逻辑计划
- Query Planner 将 Optimized Logical Plan 转换成多个物理计划。然后由 CBO 根据 Cost Model 算出每个 Physical Plan 的代价并选取代价最小的 Physical Plan 作为最终的最终执行的物理计划
- Spark 运行物理计划,先是对物理计划再进行进一步的优化,最终映射到 RDD 的操作上,和 Spark Core 一样,以 DAG 图的方式执行 SQL 语句。
7. 讲讲 Spark 的通用运行流程
- 启动集群后,Worker 节点会向 Master 节点心跳汇报资源情况;
- Client 提交 Application,根据不同的运行模式在不同的位置创建 Driver 进程;
- SparkContext 连接到 Master,向 Master 注册应用并申请资源;
- Master 根据 SparkContext 的资源申请并根据 Worker 心跳周期内报告的信息决定在哪个 Worker 上分配资源
- Worker 节点创建 Executor 进程,Executor 向 Driver 进行反向注册;
- 资源满足后,SparkContext 解析 Applicaiton 代码,创建 RDD,构建 DAG,并提交给 DAGScheduler 分解成 Stage(当碰到 Action 算子时,就会催生 Job,每个 Job 中含有 1 个或多个 Stage),然后将 Stage 提交给 TaskScheduler,TaskScheduler 负责将 Task 分配到相应的 Worker,最后提交给 Executor 执行;
- 每个 Executor 会持有一个线程池,Executor 通过启动多个线程(Task)来对 RDD 的 Partition 进行并行计算,并向 SparkContext 报告,直至 Task 完成。
- 所有 Task 完成后,SparkContext 向 Master 注销,释放资源。
8. 讲讲 Spark YARN Cluster 模式的运行流程
- Client 提交 Application(向 ResourcesManager 申请启动 ApplicationMaster,之后就不管了)
- ResourcesManager 找一个资源丰富的节点,把 ApplicationMaster 创建出来(选择一台 NodeManager 分配一个 Container,在 Container 中开启 ApplicationMaster 进程,在 中初始化 SparkContext)
- 紧接着在 AM 里把 Driver 创建出来
- 注册 Application
- 计算 Job 需要的资源并向 ResourcesManager 申请资源,ResourcesManager 通过资源调度器给 Job 飞配一些 Container,用来启动 Executor
- 反向注册给 AM,AM 就有了调度的功能
ps:
只能通过日志查看结果
Driver 所在节点出问题了,Driver 会被转发到其他节点继续执行
9. RDD,DataFrame,DataSet 的区别
RDD:
RDD 代表弹性分布式数据集。
它是记录的只读分区集合。
RDD 是 Spark 的基本数据结构。
它允许程序员以容错方式在大型集群上执行内存计算。
Dataframe:
与 RDD 不同,数据以列的形式组织起来,类似于关系数据库中的表。
它是一个不可变的分布式数据集合。
DataFrame 允许开发人员将数据结构(类型)加到分布式数据集合上,从而实现更高级别的抽象。
Dataset:
Dataset 是 DataFrame API 的扩展,它提供了类型安全,面向对象的编程接口。
Dataset 利用 Catalyst optimizer 可以让用户通过类似于 sql 的表达式对数据进行查询
10. Spark 的控制算子有哪些,有什么区别
cache: 保存到内存,效率高,数据不安全容易丢失;
persist:保存到磁盘(临时文件,作业结束后会删除),效率低,数据安全;
checkpoint: 保存到磁盘(永久保存,一般存储在分布式文件系统中,例如 HDFS),效率低,数据安全。
cache 和 persist 都是懒执行的,必须由一个 Action 类算子触发执行。checkpoint 算子不仅能将 RDD 持久化到磁盘,还能切断 RDD 之间的依赖关系。
11. YARN 的 Client 提交和 Cluster 提交的区别
Client 提交:
在 Client 提交模式下,应用程序的驱动程序运行在客户端机器上,负责向 YARNResourceManager 提交应用程序,并监控应用程序的运行状态。Client 提交模式适用于交互式的、需要即时获取应用程序执行结果的场景。在 Client 提交模式下,应用程序的生命周期与客户端程序紧密相关,如果客户端程序退出或断开连接,应用程序也会被终止。
Cluster 提交:
在 Cluster 提交模式下,应用程序的驱动程序运行在 YARN 集群的一个容器中,由 YARN ResourceManager 管理和监控应用程序的运行状态。Cluster 提交模式适用于长期运行的、不需要与客户端交互的应用程序。在 Cluster 提交模式下,应用程序的生命周期与 YARN 集群的生命周期相互独立,即使客户端程序退出或断开连接,应用程序仍然可以继续在集群上运行。
12. Spark 为什么比 MapReduce 快
Spark 基于内存,MR 基于磁盘
Spark 是粗粒度的资源申请,MR 是细粒度的资源申请
Spark 高效的调度算法基于 DAG
13. RDD 中 reduceBykey 与 groupByKey 的区别
reduceByKey:先在分区内进行预聚合(Shuffle 前),再将所有分区的数据按 Key 进行分组并聚合。
groupByKey:不会进行预聚合,直接将所有分区的数据一起分组(直接 Shuffle),如果要进行聚合,groupByKey 还
需要搭配其他函数一起使用,比如 sum()。
14. Spark 数据本地化级别与区别
- PROCESS_LOCAL(进程级本地化):
数据本地化在同一个进程内完成。
即将需要计算的数据存放在同一个 Executor 进程的内存中,避免网络传输开销。
这是最高级别的本地化级别,适用于数据量较小,不需要跨节点传输的情况。 - NODE_LOCAL(节点级本地化):
数据本地化在同一个节点内完成。
即将需要计算的数据存放在同一个节点的内存中,减少跨节点的数据传输。
适用于数据量较大,但仍可以容纳在一个节点的内存中的情况。 - RACK_LOCAL(机架级本地化):
数据本地化在同一个机架内完成。
即将需要计算的数据存放在同一个机架的节点内存中,减少跨机架的数据传输。
适用于数据量很大,无法完全存放在一个节点内存中的情况。 - ANY(任意位置本地化):
数据可以存放在任意节点的内存中。
这是最低级别的本地化级别,不要求数据在特定位置本地化。
适用于数据量非常大,无法在一个节点或机架内存放的情况。
15. Spark 单表 SQL 分组聚合查询数据倾斜如何解决
二阶段聚合(加盐局部聚合 + 去盐全局聚合):
自定义两个 udf 函数,一个添加随机前缀,一个移出随机前缀
首先,通过 map 算子给每个数据的 Key 添加随机数前缀,对 Key 进行打散,将原先一样的 Key 变成不一样的 Key,然
后进行第一次聚合,这样就可以让原本被一个 Task 处理的数据分散到多个 Task 上去做局部聚合;随后,去除掉每个 Key
的前缀,再次进行聚合
16. Spark JOIN SQL 查询数据倾斜如何解决
小表 join 大表,广播 join,将小表的数据分发到每个节点上,供大表使用
大表 join 小表,大表 key 打散,小表 key 扩容,join 完,union
17. 查看 SQL 执行计划的关键字是什么,有什么用
explain
模拟 优化器 执行 SQL 查询语句
不会去真正的执行这条 SQL
从而知道如何处理你的 SQL 语句
用来分析你的查询语句或是表结构的性能瓶颈
18. 说一说 Spark 你知道的优化
RBO 基于规则优化
CBO 基于代价优化
JOIN 小表jion大表
8. SQL(练习题)
- abc.txt 按空格分割 WordCount SQL 实现思路
- 求部门前三薪资 SQL 实现思路
- 连续 7 天登录 SQL 实现过程
- 统计每个员工前三个月的薪水,每月统计一次
- 好友推荐 SQL 实现思路
作者:阿修11
个人QQ:3083786259
学习交流群:743920251















 324
324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









