







引言
D S U : D i s j o i n t S e t U n i o n DSU:Disjoint\;Set\;Union DSU:DisjointSetUnion
中文名:并查集
d s u o n t r e e dsu\;on\;tree dsuontree直译过来就是“在树上的并查集”
但并不是这样
你或许也听过这样一种说法
d s u o n t r e e = dsu\;on\;tree= dsuontree= 树上启发式合并
实际上
d s u o n t r e e ! = dsu\;on\;tree!= dsuontree!= 树上启发式合并
树上启发式合并
为什么说 d s u o n t r e e ! = dsu\;on\;tree!= dsuontree!= 树上启发式合并呢
首先我们先来思考一下
“启发式合并”这个词以前你是否听过?
如果没有,那么换种说法,“按秩合并”这个词以前你是否听过?
如果还没有,那么联系一下本文最开头提到的并查集
实际上,并查集的按秩合并,就是树上启发式合并
这也许就是 d s u dsu dsu和 d s u o n t r e e dsu\;on\;tree dsuontree的唯一共通之处吧
先回忆一下什么是并查集
可能很多同学都对并查集的理解就只局限于了简单的几行代码和它实际的应用
如同我们所知的众多 S T L STL STL,他们都是由一些底层的数据结构来维护的,例如堆是用二叉树, s e t set set是用红黑树
并查集虽然不是 S T L STL STL,但它实际上也有着内部的结构:树
道理很简单,每个节点都有着它自己的 f a fa fa,这样的结构不就是一颗树吗?
那么并查集是如何高效的合并两棵树的呢?
利用路径压缩和按秩合并
实际上我们平时只会用路径压缩,因为仅使用这个就已经很高效了
如果现在给你两棵树,让你把他们合并在一起,且不需要关心树的结构,你会怎么做?
最暴力的做法当然就是把一棵树上所有节点的 f a fa fa全部设置为另一棵树上的某个节点
那假设你的两棵树的大小分别为 1 1 1和 1000000 1000000 1000000呢
显然,你不会把后者合并到前者上,因为这样时间复杂度就太高了
一句话归纳:把小树合并到大树上,这就是树上启发式合并
按秩合并同理,是把小的并查集合到大的并查集上
这样听下来,如果 d s u o n t r e e = dsu\;on\;tree= dsuontree= 树上启发式合并,那么这个算法是不是就很轻松的讲完了?
轻重边
在讲 d s u o n t r e e dsu\;on\;tree dsuontree前,我们还需了解一个概念:轻重边
这个概念的最主要的应用在于树链剖分,但这里不过多介绍
先来了解:重儿子
在一棵有根树中,对于一个节点 x x x,他会有许多的子节点,在这些子节点中,只有一个称得上是它的重儿子
即子树节点个数最多的那个儿子
我们将一个节点 x x x和它重儿子之间的边成为重边,其他边为轻边
举个例子:
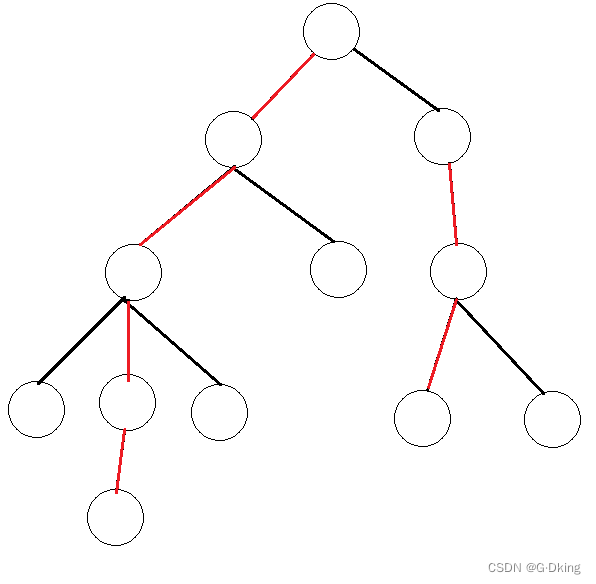
在这幅图中,红边为重边,黑边为轻边
dsu on tree
在我看来, d s u o n t r e e dsu\;on\;tree dsuont
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 572
572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









