






本人编程小白,自学了python,在这里分享一下自学爬虫的一些心得,帮助跟我一样的小白少踩坑,同时也是总结一下自己所学。
- 爬虫其实就是发送网络请求来获取别人网页的源码,然后在经过数据提取,获取到自己想要的内容。那么首先自然就是发送请求了,python常用的两种库urllib和requests。这里我先讲urllib,urllib是python自带的库,以下是一个基础的爬虫
from urllib.request import urlopen # 请求的地址 url = 'http://www.baidu.com/' # 发送请求 resp = urlopen(url) # 打印响应结果 print(resp.read()) #read()方法用来读取响应的结果 #这样会显示一大堆看不懂类似乱码的东西 因为resp.read()的类型是<class 'bytes'> #那么需要做一个编码的操作 print(resp.read().decode()[:100]) #decode()默认UTF-8 并且用切片操作截取前100个字符 # 打印结果 <!DOCTYPE html><!--STATUS OK--><html><head><meta http-equiv="Content-Type" content="text/html;charse可以看到 其实就是获取了百度网页的html代码
-
urllib其实有多种响应对象
from urllib.request import urlopen # 定义发送的位置 url = 'http://www.baidu.com/' # 发送请求 resp = urlopen(url) # 打印响应数据 print(resp.read()[:100]) # 获取响应码 print(resp.getcode()) # 200 # 获取访问的url print(resp.geturl()) # http://www.baidu.com/ # 获取响应头信息 print(resp.info()) # 响应头信息包括 Content-Type Cookie等 -
当使用urllib.request.urlopen发送请求时,并不能设置请求参数,那么可以将参数封装到一个Request对象中。比如请求头信息User-Agent 这个是能识别你通过什么发送请求的一个东西,为了防止反爬是需要隐藏的比如
from urllib.request import Request,urlopen url = 'http://httpbin.org/get' #这是HTTP响应测试网站 # 创建Request req = Request(url) # 发送请求 resp = urlopen(req) # 打印结果 print(resp.read().decode()) # { "args": {}, "headers": { "Accept-Encoding": "identity", "Host": "httpbin.org", "User-Agent": "Python-urllib/3.10", "X-Amzn-Trace-Id": "Root=1-637cbca6-2bb6514c285f49751a84ce8c" } 可以看到 "User-Agent": "Python-urllib/3.10" 这条信息明显就是一条爬虫,那么在爬各大网站的时候别人会直接把你封掉 #那么就需要隐藏User-Agent from urllib.request import Request,urlopen # url = 'http://www.baidu.com/' url = 'http://httpbin.org/get' # 定义headers信息 user_agent隐藏请求头 headers = {'User-Agent':'Mozilla/5.0 Python666666666'} #User-Agent可以自定义,当然自定义的肯定不行,这里只是做演示 # 创建Request req = Request(url) # 发送请求 resp = urlopen(req) # 打印结果 print(resp.read().decode()) #{ "args": {}, "headers": { "Accept-Encoding": "identity", "Host": "httpbin.org", "User-Agent": "Mozilla/5.0 Python666666666", "X-Amzn-Trace-Id": "Root=1-637cbdab-20bad7777fbe830048086836" } 可以看到User-Agent已经改变了User-Agent的设置方式有两种,一种就是使用自己浏览器的开发者工具获取(如有不会的小伙伴可以百度或者私信我),第二种是python有一个三方库可以随机生成不同浏览器的User-Agent这个后面说
-
在目前网络获取数据的方式有多种方式:GET方式
大部分被传输到浏览器的html,images,js,css, ... 都是通过GET
方法发出请求的。它是获取数据的主要方法
例如:www.baidu.com 搜索
Get请求的参数都是在Url中体现的(就是在你的网址中会存在中文),如果有中文,需要转码,这时我们可使用urllib.parse.urlencode() 转换键值对
urllib.parse. quote() 转换一个值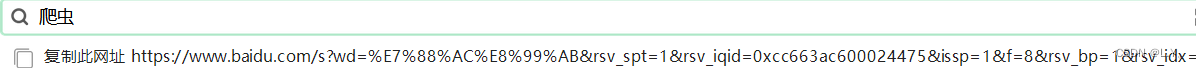
wd= 后面跟的就是中文爬虫两字 进行了转码
from urllib.request import urlopen,Request from urllib.parse import quote,urlencode # UnicodeEncodeError: 'ascii' codec can't encode characters in position 16-17: ordinal not in range(128) # 报错提示 url里的参数,不能有中文 #查询参数 args = 'python爬虫' #采用字符串拼接 quote()方法把中文转码 url = f'https://www.baidu.com/s?wd={quote(args)}' headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36'} req = Request(url,headers=headers) resp = urlopen(req) print(resp.read().decode()[:1500]) #urlencode方法 args ={'wd':'python爬虫'} #urlencode方法是转换字典形式的数据 url = f'https://www.baidu.com/s?{urlencode(args)}' headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36'} req = Request(url,headers=headers) resp = urlopen(req) print(resp.read().decode()[:1500]) -
接下来做一个简单网页的爬取 url:https://www.ximalaya.com/yinyue
from urllib.request import Request,urlopen from time import sleep def spider_music(_type,page): # 构造URL地址 for num in range(1,page+1): if num == 1: url = f'https://www.ximalaya.com/yinyue/{_type}' else: url = f'https://www.ximalaya.com/yinyue/{_type}/p{num}/' headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36'} # 构造请求对象 req = Request(url,headers=headers) # 发送请求 resp = urlopen(req) # 获取响应 print(resp.getcode()) print(resp.geturl()) # print(resp.read().decode()[:2000]) # 休眠 防止爬取速度过快对别人服务器造成影响 sleep(1) if __name__ == '__main__': spider_music('minyao',3)这里需要分析url的构成,如何动态的获取到多页url和想要的音乐属性
暂时总结这么多会持续更新,手敲不易希望多多支持,有问题的可以私信我,大家一起学习















 762
762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









