






0. 前序
每天迈出一小步,朝着目标迈一大步。
Python爬虫主要分为三大板块:抓取数据,分析数据,存储数据。
简单来说,爬虫要做就是通过指定的url,直接返回用户所需数据,无需人工一步步操作浏览器获取。

1. 抓取数据
一般来说,访问网站url给我们返回两种格式数据,html和json。
1) 无参
抓取数据的大多数属于get请求,我们可以直接从网站所在服务器获取数据。在python自带模块中,主要有urllib及urllib2,requests等。
这里以requests为例。
Requests:
import requests
response = requests.get(url)
content = requests.get(url).content
content = requests.get(url).json()
print "response headers:", response.headers
print "content:", content
**2)带参
**
此外,还有一种是以带参的形式抓取数据,参数一般附在url结尾,首个参数以"?“连接,后续参与以”&"连接。
data = {'data1':'XXXXX', 'data2':'XXXXX'}
Requests:data为dict,json
import requests
response = requests.get(url=url, params=data)
2.登录情况处理
1) post表单登录
先向服务器发送表单数据,服务器再将返回的cookie存入本地。
data = {'data1':'XXXXX', 'data2':'XXXXX'}
Requests:data为dict,json
import requests
response = requests.post(url=url, data=data)
2) 使用cookie登陆
使用cookie登录,服务器会认为你是一个已登录用户,会返回一个已登录的内容。需要验证码的情况,我们可以考虑此方式解决。
import requests
requests_session = requests.session()
response = requests_session.post(url=url_login, data=data)
3.反爬虫机制处理
我们知道,现在很多网站都做了反爬虫机制处理。
相信我们都遇到,当我们爬取某个网站的时候,**第一次爬取可以,第二次可以,第三次就报失败了,**会提示IP限制或者访问过于频繁报错等。
针对于这种情况,我们有几种方法解决。
1) 使用代理
主要是用于"限制IP"地址情况,同样也可以解决频繁访问需要验证码的问题。
我们可以维护一个代理IP池,网上可以查到很多免费的代理IP,我们可以选择我们所需要的。
proxies = {'http':'http://XX.XX.XX.XX:XXXX'}
Requests:
import requests
response = requests.get(url=url, proxies=proxies)
2)时间限制
解决频繁访问导致访问受限问题。遇到这种情况很简单,我们需要放缓两次点击之间的频率即可,加入sleep函数即可。
import time
time.sleep(1)
3) 伪装成浏览器访问
当我们看到一些爬虫代码的时候,会发现get请求会有headers头,这是在伪装浏览器访问的反盗链。
一些网站会检查你是不是真的浏览器访问,还是机器自动访问的。这种情况,加上User-Agent,表明你是浏览器访问即可。
有时还会检查是否带Referer信息还会检查你的Referer是否合法,一般再加上Referer。
headers = {'User-Agent':'XXXXX'} # 伪装成浏览器访问,适用于拒绝爬虫的网站
headers = {'Referer':'XXXXX'}
headers = {'User-Agent':'XXXXX', 'Referer':'XXXXX'}
Requests:
response = requests.get(url=url, headers=headers)
4) 断线重连
可以参考两种方法。
def multi_session(session, *arg):
retryTimes = 20
while retryTimes>0:
try:
return session.post(*arg)
except:
retryTimes -= 1
或
def multi_open(opener, *arg):
retryTimes = 20
while retryTimes>0:
try:
return opener.open(*arg)
except:
retryTimes -= 1
这样我们就可以使用multi_session或multi_open对爬虫抓取的session或opener进行保持。

4.多线程爬取
当我们爬取或者数据量过大,可以考虑使用多线程。这里介绍一种,当然还有其他方式实现。
import multiprocessing as mp
def func():
pass
p = mp.Pool()
p.map_async(func)
# 关闭pool,使其不在接受新的(主进程)任务
p.close()
# 主进程阻塞后,让子进程继续运行完成,子进程运行完后,再把主进程全部关掉。
p.join(
5. 分析
一般获取的服务器返回数据主要有两种,html和json。
html格式数据,可以采用BeautifulSoup,lxml,正则表达式等处理
json格式数据,可以采用Python列表,json,正则表达式等方式处理
此外,我们可以采用numpy, pandas,matplotlib,pyecharts等模块包做相应的数据分析,可视化展示等。
6. 存储
数据抓取,分析处理完后,一般我们还需要把数据存储下来,常见的方式有存入数据库,excel表格的。根据自己需要选择合适的方式,把数据处理成合适的方式入库。
最后再说句,码字了那么多,真的不来个关注吗。

欢迎大家关注我,一起讨论Python与数据分析中常见问题,一起交流学习。
我这里准备了详细的Python资料,除了为你提供一条清晰的学习路径,我甄选了最实用的学习资源以及庞大的实例库。短时间的学习,你就能够很好地掌握爬虫这个技能,获取你想得到的数据。
01 专为0基础设置,小白也能轻松学会
我们把Python的所有知识点,都穿插在了漫画里面。
在Python小课中,你可以通过漫画的方式学到知识点,难懂的专业知识瞬间变得有趣易懂。


你就像漫画的主人公一样,穿越在剧情中,通关过坎,不知不觉完成知识的学习。
02 无需自己下载安装包,提供详细安装教程

03 规划详细学习路线,提供学习视频
04 提供实战资料,更好巩固知识
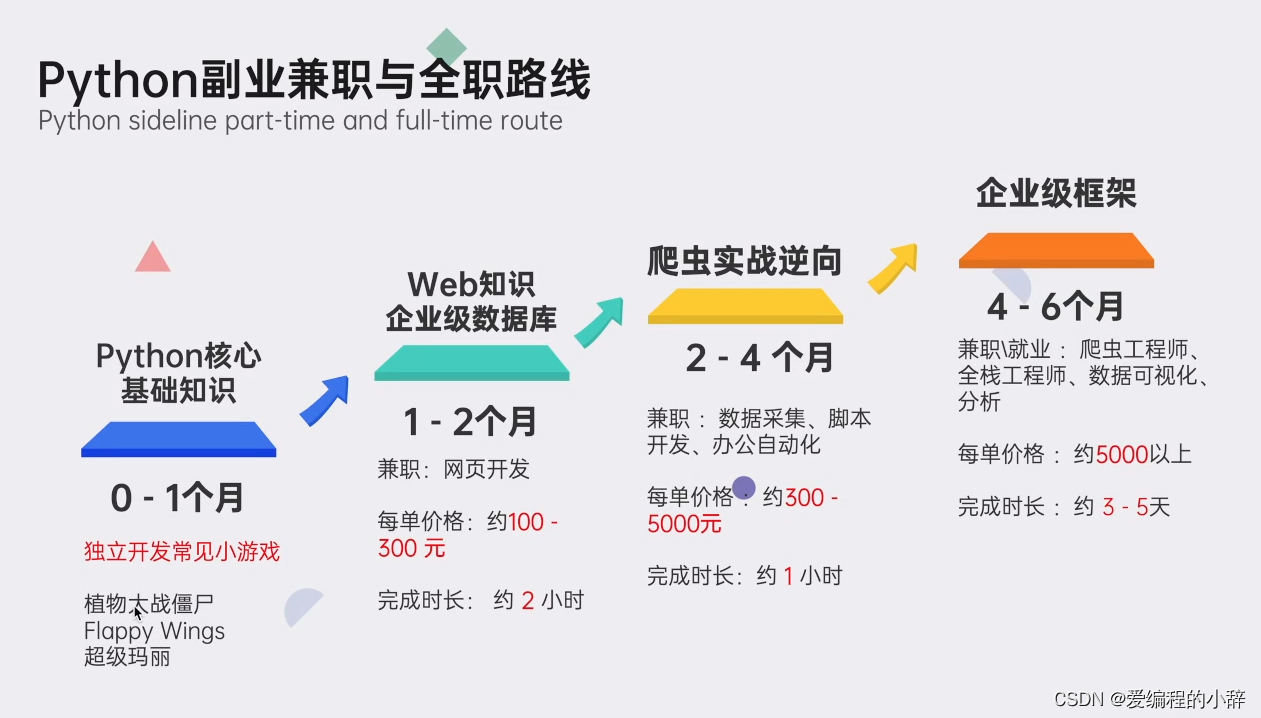
05 提供面试资料以及副业资料,便于更好就业
这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要也可以扫描下方csdn官方二维码或者点击主页和文章下方的微信卡片获取领取方式,【保证100%免费】
















 5321
5321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









