






神经网络中十分重要的一步就是数据的处理,将需要的数据打包,是十分重要的一步,下面我们就将使用步骤进行梳理。

步骤一:从标注文件中读取数据和标签
下面的程序是将数据打包成字典的结构
def load_annotations(ann_file):
data_infos = {}
with open(ann_file) as f:
samples = [x.strip().split(' ') for x in f.readlines()]
for filename, gt_label in samples:
data_infos[filename] = np.array(gt_label, dtype=np.int64)
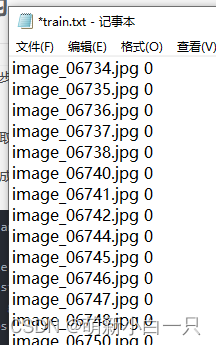
return data_infos标注文件的内容如下:
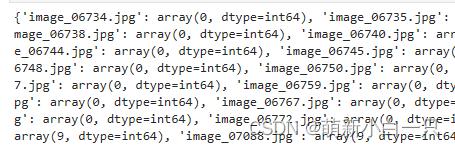
打包成字典之后的格式:
步骤二:将数据和标签都放在list中
因为dataloader是这样做的,所以我们需要做成list的格式
image_name = list(img_label.keys())
label = list(img_label.values())步骤三:获取图像路径
data_dir = './flower_data/'
train_dir = data_dir + '/train_filelist'
valid_dir = data_dir + '/val_filelist'
image_path = [os.path.join(train_dir,img) for img in image_name]
image_path结果:

步骤四:将上述的步骤合并在一起
获取数据的地址和标签的list——>通过getitem函数将每个标签和图像都取出来
from torch.utils.data import Dataset, DataLoader
class FlowerDataset(Dataset):
def __init__(self, root_dir, ann_file, transform=None):
self.ann_file = ann_file
self.root_dir = root_dir
self.img_label = self.load_annotations()
self.img = [os.path.join(self.root_dir,img) for img in list(self.img_label.keys())]
self.label = [label for label in list(self.img_label.values())]
self.transform = transform
def __len__(self):
return len(self.img)
def __getitem__(self, idx):
image = Image.open(self.img[idx])
label = self.label[idx]
if self.transform:
image = self.transform(image)
label = torch.from_numpy(np.array(label))
return image, label
def load_annotations(self):
data_infos = {}
with open(self.ann_file) as f:
samples = [x.strip().split(' ') for x in f.readlines()]
for filename, gt_label in samples:
data_infos[filename] = np.array(gt_label, dtype=np.int64)
return data_infos步骤六:用写好的类来实例化dataloader
train_dataset = FlowerDataset(root_dir=train_dir, ann_file = './flower_data/train.txt', transform=data_transforms['train'])
val_dataset = FlowerDataset(root_dir=valid_dir, ann_file = './flower_data/val.txt', transform=data_transforms['valid'])
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=True)步骤7:用 iter(train_loader).next()取一个batch来验证
image, label = iter(train_loader).next()
sample = image[0].squeeze()
sample = sample.permute((1, 2, 0)).numpy()
sample *= [0.229, 0.224, 0.225]
sample += [0.485, 0.456, 0.406]
plt.imshow(sample)
plt.show()
print('Label is: {}'.format(label[0].numpy()))结果:
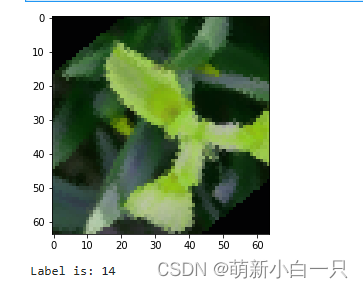
总结:获取数据的地址和标签的list——>通过getitem函数将每个标签和图像都取出来,返回图像和标签——>再用传到dataloader指定batchsize和shuffle()














 1784
1784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









