







数组定义以及排序的算法
文章目录
一、定义数组
- 方法一:
数组名=(value0 value1 value2 …)
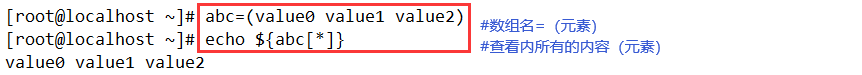
- 方法二:
数组名=([0]=value [1]=value [2]=value …)

- 方法三:
列表名=“value0 value1 value2 …”
数组名=($列表名)

- 方法四:
数组名[0]=“value”
数组名[1]=“value”
数组名[2]="value"

二、数组的数据类型
- 字符类型(字符串):使用" "或’ '定义
- 防止元素当中有空格,元素按空格分割
三、获取数组长度
abc=(1 2 3 4 5)
#定义数组
echo KaTeX parse error: Expected 'EOF', got '#' at position 80: …n punctuation">#̲</span><span cl…(#abc[@])
#获取数组长度

1.读取某索引复制
zxc=(1 2 3 4 5)
echo ${ zxc[0]}
echo ${ zxc[3]}

2.遍历数组
#!/bin/bash
zxc=(1 2 3 4 5)
for q in
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
<
!
−
−
−
−
>
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
z
x
c
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
b
r
a
c
k
e
t
s
"
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
[
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
∗
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
]
<
/
s
p
a
n
>
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
d
o
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
e
c
h
o
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
</span><span class="token punctuation">{<!-- --></span><span class="token variable">zxc</span><span class="token brackets"><span class="token punctuation">[</span><span class="token variable">*</span><span class="token punctuation">]</span></span><span class="token punctuation">}</span> <span class="token variable">do</span> <span class="token variable">echo</span> <span class="token variable">
</span><spanclass="tokenpunctuation"><!−−−−></span><spanclass="tokenvariable">zxc</span><spanclass="tokenbrackets"><spanclass="tokenpunctuation">[</span><spanclass="tokenvariable">∗</span><spanclass="tokenpunctuation">]</span></span><spanclass="tokenpunctuation"></span><spanclass="tokenvariable">do</span><spanclass="tokenvariable">echo</span><spanclass="tokenvariable">q
done


3.数组切片
arry=(1 2 3 4 5 )
echo ${zxc[*]}
echo ${zxc[@]}
#输出整个数组,此处*与@相同
echo KaTeX parse error: Expected 'EOF', got '#' at position 468: …n punctuation">#̲</span><span cl…{
数组名[@或*]:始位置:长度} 的值
echo
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
<
!
−
−
−
−
>
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
z
x
c
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
b
r
a
c
k
e
t
s
"
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
[
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
@
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
]
<
/
s
p
a
n
>
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
:
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
n
u
m
b
e
r
"
>
2
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
:
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
n
u
m
b
e
r
"
>
2
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
e
c
h
o
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
</span><span class="token punctuation">{<!-- --></span><span class="token variable">zxc</span><span class="token brackets"><span class="token punctuation">[</span><span class="token variable">@</span><span class="token punctuation">]</span></span><span class="token variable">:</span><span class="token number">2</span><span class="token variable">:</span><span class="token number">2</span><span class="token punctuation">}</span> <span class="token variable">echo</span> <span class="token variable">
</span><spanclass="tokenpunctuation"><!−−−−></span><spanclass="tokenvariable">zxc</span><spanclass="tokenbrackets"><spanclass="tokenpunctuation">[</span><spanclass="tokenvariable">@</span><spanclass="tokenpunctuation">]</span></span><spanclass="tokenvariable">:</span><spanclass="tokennumber">2</span><spanclass="tokenvariable">:</span><spanclass="tokennumber">2</span><spanclass="tokenpunctuation"></span><spanclass="tokenvariable">echo</span><spanclass="tokenvariable">{
zxc[@]:3:3}

4.替换数组
- 方法一:单个替换
zxc=(1 2 3 4 5)
echo ${zxc[*]}
zxc[0]=123
echo ${ zxc[*]}

- 方法二:多个替换(临时替换)
echo ${zxc[*]/1/22}
#临时替换
echo ${zxc[*]}
#原来的值不变

- 方法三:多个替换(永久替换)
zxc=${zxc[*]/1/22}
zxc=($zxc)
#再次赋值变量,以达到永久替换的作用
echo ${ zxc[*]}

5.删除数组
echo ${zxc[*]}
unset zxc
#删除整个数组
echo ${ zxc[*]}

zxc=(1 2 3 4 5)
echo ${zxc[*]}
unset zxc[]
#删除数组中选择索引对应的元素
echo ${
zxc[*]}
echo
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
<
!
−
−
−
−
>
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
z
x
c
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
[
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
n
u
m
b
e
r
"
>
4
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
]
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
e
c
h
o
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
</span><span class="token punctuation">{<!-- --></span><span class="token variable">zxc</span><span class="token punctuation">[</span><span class="token number">4</span><span class="token punctuation">]</span><span class="token punctuation">}</span> <span class="token variable">echo</span> <span class="token variable">
</span><spanclass="tokenpunctuation"><!−−−−></span><spanclass="tokenvariable">zxc</span><spanclass="tokenpunctuation">[</span><spanclass="tokennumber">4</span><spanclass="tokenpunctuation">]</span><spanclass="tokenpunctuation"></span><spanclass="tokenvariable">echo</span><spanclass="tokenvariable">{
zxc[3]}
echo ${
zxc[2]}

6.追加元素
- 方法一:单个添加
zxc=(1 2 3 4 5)
echo ${zxc[*]}
arr[5]=6
arr[6]=7
echo ${
zxc[*]}

- 方法二:
在不进行任何删减时,索引最大值就是元素长度减一
zxc=(1 2 3 4 5)
zxc[${#zxc[*]}]=10
echo < / s p a n > < s p a n c l a s s = " t o k e n p u n c t u a t i o n " > < ! − − − − > < / s p a n > < s p a n c l a s s = " t o k e n v a r i a b l e " > z x c < / s p a n > < s p a n c l a s s = " t o k e n b r a c k e t s " > < s p a n c l a s s = " t o k e n p u n c t u a t i o n " > [ < / s p a n > < s p a n c l a s s = " t o k e n v a r i a b l e " > ∗ < / s p a n > < s p a n c l a s s = " t o k e n p u n c t u a t i o n " > ] < / s p a n > < / s p a n > < s p a n c l a s s = " t o k e n p u n c t u a t i o n " > < / s p a n > < s p a n c l a s s = " t o k e n v a r i a b l e " > e c h o < / s p a n > < s p a n c l a s s = " t o k e n v a r i a b l e " > </span><span class="token punctuation">{<!-- --></span><span class="token variable">zxc</span><span class="token brackets"><span class="token punctuation">[</span><span class="token variable">*</span><span class="token punctuation">]</span></span><span class="token punctuation">}</span> <span class="token variable">echo</span> <span class="token variable"> </span><spanclass="tokenpunctuation"><!−−−−></span><spanclass="tokenvariable">zxc</span><spanclass="tokenbrackets"><spanclass="tokenpunctuation">[</span><spanclass="tokenvariable">∗</span><spanclass="tokenpunctuation">]</span></span><spanclass="tokenpunctuation"></span><spanclass="tokenvariable">echo</span><spanclass="tokenvariable">{ zxc[5]}

- 方法三:
直接获取源数组的全部元素再加上新要添加的元素,一并重新赋予该数组,重新刷新定义索引
zxc=(1 2 3 4 5)
echo ${zxc[*]}
unset zxc[1]
unset zxc[3]
echo ${
zxc[*]}
echo
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
<
!
−
−
−
−
>
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
z
x
c
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
[
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
n
u
m
b
e
r
"
>
0
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
]
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
e
c
h
o
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
</span><span class="token punctuation">{<!-- --></span><span class="token variable">zxc</span><span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">}</span> <span class="token variable">echo</span> <span class="token variable">
</span><spanclass="tokenpunctuation"><!−−−−></span><spanclass="tokenvariable">zxc</span><spanclass="tokenpunctuation">[</span><spanclass="tokennumber">0</span><spanclass="tokenpunctuation">]</span><spanclass="tokenpunctuation"></span><spanclass="tokenvariable">echo</span><spanclass="tokenvariable">{
zxc[2]}
echo
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
<
!
−
−
−
−
>
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
z
x
c
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
[
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
n
u
m
b
e
r
"
>
4
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
]
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
e
c
h
o
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
</span><span class="token punctuation">{<!-- --></span><span class="token variable">zxc</span><span class="token punctuation">[</span><span class="token number">4</span><span class="token punctuation">]</span><span class="token punctuation">}</span> <span class="token variable">echo</span> <span class="token variable">
</span><spanclass="tokenpunctuation"><!−−−−></span><spanclass="tokenvariable">zxc</span><spanclass="tokenpunctuation">[</span><spanclass="tokennumber">4</span><spanclass="tokenpunctuation">]</span><spanclass="tokenpunctuation"></span><spanclass="tokenvariable">echo</span><spanclass="tokenvariable">{
zxc[1]}
echo ${
zxc[3]}
zxc=("
z
x
c
[
@
]
"
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
n
u
m
b
e
r
"
>
6
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
n
u
m
b
e
r
"
>
7
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
n
u
m
b
e
r
"
>
8
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
)
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
e
c
h
o
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
{zxc[@]}"</span> <span class="token number">6</span> <span class="token number">7</span> <span class="token number">8</span><span class="token punctuation">)</span> <span class="token variable">echo</span> <span class="token variable">
zxc[@]"</span><spanclass="tokennumber">6</span><spanclass="tokennumber">7</span><spanclass="tokennumber">8</span><spanclass="tokenpunctuation">)</span><spanclass="tokenvariable">echo</span><spanclass="tokenvariable">{
zxc[*]}
echo
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
<
!
−
−
−
−
>
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
z
x
c
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
[
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
n
u
m
b
e
r
"
>
0
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
]
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
e
c
h
o
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
</span><span class="token punctuation">{<!-- --></span><span class="token variable">zxc</span><span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">}</span> <span class="token variable">echo</span> <span class="token variable">
</span><spanclass="tokenpunctuation"><!−−−−></span><spanclass="tokenvariable">zxc</span><spanclass="tokenpunctuation">[</span><spanclass="tokennumber">0</span><spanclass="tokenpunctuation">]</span><spanclass="tokenpunctuation"></span><spanclass="tokenvariable">echo</span><spanclass="tokenvariable">{
zxc[1]}
echo
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
<
!
−
−
−
−
>
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
z
x
c
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
[
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
n
u
m
b
e
r
"
>
2
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
]
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
e
c
h
o
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
</span><span class="token punctuation">{<!-- --></span><span class="token variable">zxc</span><span class="token punctuation">[</span><span class="token number">2</span><span class="token punctuation">]</span><span class="token punctuation">}</span> <span class="token variable">echo</span> <span class="token variable">
</span><spanclass="tokenpunctuation"><!−−−−></span><spanclass="tokenvariable">zxc</span><spanclass="tokenpunctuation">[</span><spanclass="tokennumber">2</span><spanclass="tokenpunctuation">]</span><spanclass="tokenpunctuation"></span><spanclass="tokenvariable">echo</span><spanclass="tokenvariable">{
zxc[3]}
echo
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
<
!
−
−
−
−
>
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
z
x
c
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
[
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
n
u
m
b
e
r
"
>
4
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
]
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
e
c
h
o
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
</span><span class="token punctuation">{<!-- --></span><span class="token variable">zxc</span><span class="token punctuation">[</span><span class="token number">4</span><span class="token punctuation">]</span><span class="token punctuation">}</span> <span class="token variable">echo</span> <span class="token variable">
</span><spanclass="tokenpunctuation"><!−−−−></span><spanclass="tokenvariable">zxc</span><spanclass="tokenpunctuation">[</span><spanclass="tokennumber">4</span><spanclass="tokenpunctuation">]</span><spanclass="tokenpunctuation"></span><spanclass="tokenvariable">echo</span><spanclass="tokenvariable">{
zxc[5]}
#注意:
#双引号不能省略,否则数组中存在包含空格的元素时会按空格将元素拆分成多个
#不能将“@”替换为“”,如果替换为“”,不加双引号时与“@”的表现一致,加双引号时,会将数组中的所有元素作为一个元素添加到数组中

- 方法四:待添加元素必须用“()”包围起来,并且多个元素用空格分隔
zxc+=(10 11 12 ...)
echo ${zxc[*]}

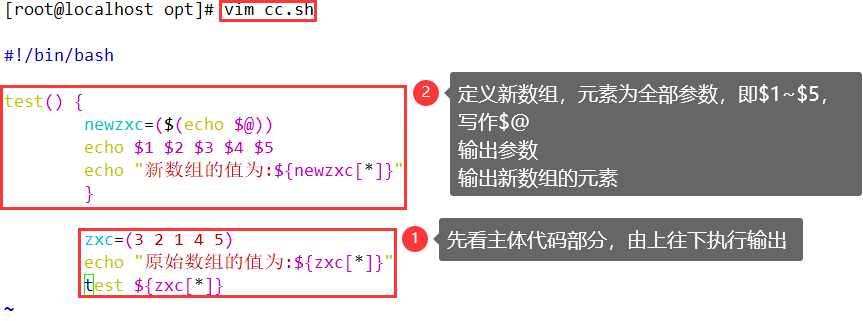
四、向函数传数组参数
#!/bin/bash
test() {
newzxc=(
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
p
u
n
c
t
u
a
t
i
o
n
"
>
(
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
e
c
h
o
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
</span><span class="token punctuation">(</span><span class="token variable">echo</span> <span class="token variable">
</span><spanclass="tokenpunctuation">(</span><spanclass="tokenvariable">echo</span><spanclass="tokenvariable">@))
echo
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
n
u
m
b
e
r
"
>
1
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
</span><span class="token number">1</span> <span class="token variable">
</span><spanclass="tokennumber">1</span><spanclass="tokenvariable">2
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
n
u
m
b
e
r
"
>
3
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
</span><span class="token number">3</span> <span class="token variable">
</span><spanclass="tokennumber">3</span><spanclass="tokenvariable">4
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
n
u
m
b
e
r
"
>
5
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
v
a
r
i
a
b
l
e
"
>
e
c
h
o
<
/
s
p
a
n
>
<
s
p
a
n
c
l
a
s
s
=
"
t
o
k
e
n
s
t
r
i
n
g
"
>
"
新
数
组
的
值
为
:
</span><span class="token number">5</span> <span class="token variable">echo</span> <span class="token string">"新数组的值为:
</span><spanclass="tokennumber">5</span><spanclass="tokenvariable">echo</span><spanclass="tokenstring">"新数组的值为:{newzxc[*]}"
}
<span class="token variable">zxc</span><span class="token punctuation">=</span><span class="token punctuation">(</span><span class="token number">3</span> <span class="token number">2</span> <span class="token number">1</span> <span class="token number">4</span> <span class="token number">5</span><span class="token punctuation">)</span>
<span class="token variable">echo</span> <span class="token string">"原始数组的值为:${zxc[*]}"</span>
<span class="token variable">test</span> <span class="token variable">$</span><span class="token punctuation">{<!-- --></span><span class="token variable">zxc</span><span class="token brackets"><span class="token punctuation">[</span><span class="token variable">*</span><span class="token punctuation">]</span></span><span class="token punctuation">}</span>

五、数组排序算法
1.冒泡排序
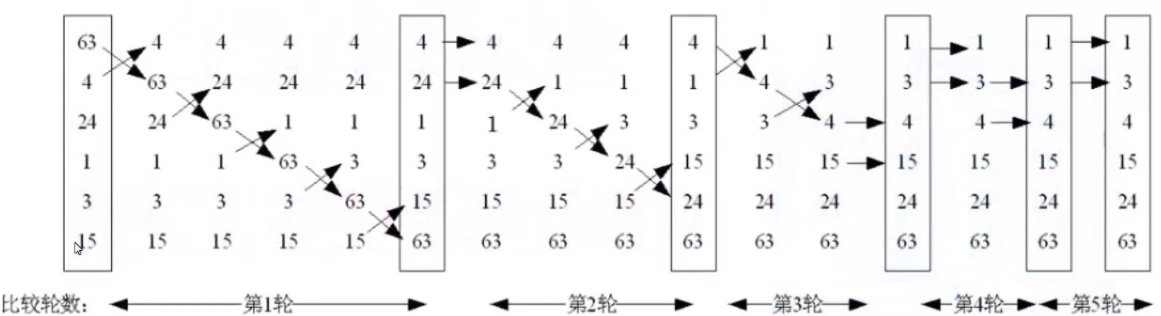
- 类似气泡上涌的动作,会将数据在数组中从小到大或者从大到小不断的向前移动
- 基本思想:
冒泡排序的基本思想是对比相邻的两个元素值,如果满足条件就交换元素值,把较小的元素移动到数组前面,把大的元素移动到数组后面(也就是交换两个元素的位置),这样较小的元素就像气泡一样从底部上升到顶部 - 算法思路:
冒泡算法由双层循环实现,其中外部循环用于控制排序轮数,一般为要排序的数组长度减1次,因为最后一次循环只剩下一个数组元素,不需要对比,同时数组已经完成排序了。而内部循环主要用于对比数组中每个相邻元素的大小,以确定是否交换位置,对比和交换次数随排序轮数而减少
#!/bin/bash
zxc=(50 30 20 10 40)
echo “原数组的元素顺序为:${zxc[*]}”
for ((i=1;i<KaTeX parse error: Expected '}', got '#' at position 88: …n punctuation">#̲</span><span cl…{
#zxc[*]}-i;a++))
do
<span class="token variable">if</span> <span class="token brackets"><span class="token punctuation">[</span><span class="token variable"> ${zxc</span><span class="token punctuation">[</span><span class="token variable">$a</span><span class="token punctuation">]</span></span><span class="token punctuation">}</span> <span class="token variable">-gt</span> <span class="token variable">$</span><span class="token punctuation">{<!-- --></span><span class="token variable">zxc</span><span class="token punctuation">[</span><span class="token variable">$a</span><span class="token punctuation">+</span><span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">}</span> <span class="token punctuation">]</span><span class="token punctuation">;</span><span class="token variable">then</span>
<span class="token variable">temp</span><span class="token punctuation">=</span><span class="token variable">$</span><span class="token punctuation">{<!-- --></span><span class="token variable">zxc</span><span class="token brackets"><span class="token punctuation">[</span><span class="token variable">$a</span><span class="token punctuation">]</span></span><span class="token punctuation">}</span>
<span class="token variable">zxc</span><span class="token brackets"><span class="token punctuation">[</span><span class="token variable">$a</span><span class="token punctuation">]</span></span><span class="token punctuation">=</span><span class="token variable">$</span><span class="token punctuation">{<!-- --></span><span class="token variable">zxc</span><span class="token punctuation">[</span><span class="token variable">$a</span><span class="token punctuation">+</span><span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">}</span>
<span class="token variable">zxc</span><span class="token punctuation">[</span><span class="token variable">$a</span><span class="token punctuation">+</span><span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">=</span><span class="token variable">$temp</span>
<span class="token variable">fi</span>
<span class="token variable">done</span>
done
echo “经过冒泡排序后,数组顺序为:${zxc[*]}”


2.直接选择排序

- 与冒泡排序相比,直接选择排序的交换次数更少,所以速度更快
- 基本思想:将指定排序位置与其他数组元素分别对比,如果满足条件就交换元素值,注意这里区别冒泡排序,不是交换相邻元素,而是把满足条件的元素与指定的排序位置交换(如从最后一个元素开始排序),这样排序好的位置逐渐扩大,最后整个数组都成为已排序好的格式
#!/bin/bash
zxc=(30 50 20 10 40)
echo “原数组元素顺序为:${zxc[*]}”
long=${ #zxc[*]}
for ((i=1;i<KaTeX parse error: Expected 'EOF', got '&' at position 755: …n punctuation">&̲lt;</span><span…long-$i;a++))
do
if [ KaTeX parse error: Expected '}', got 'EOF' at end of input: …oken variable">a]} -gt KaTeX parse error: Expected '}', got 'EOF' at end of input: …oken variable">index]} ];then
index=$a
fi
<span class="token variable">last</span><span class="token punctuation">=</span><span class="token variable">$</span><span class="token brackets"><span class="token punctuation">[</span><span class="token variable">$long-$i</span><span class="token punctuation">]</span></span>
<span class="token variable">temp</span><span class="token punctuation">=</span><span class="token variable">$</span><span class="token punctuation">{<!-- --></span><span class="token variable">zxc</span><span class="token brackets"><span class="token punctuation">[</span><span class="token variable">$last</span><span class="token punctuation">]</span></span><span class="token punctuation">}</span>
<span class="token variable">zxc</span><span class="token brackets"><span class="token punctuation">[</span><span class="token variable">$last</span><span class="token punctuation">]</span></span><span class="token punctuation">=</span><span class="token variable">$</span><span class="token punctuation">{<!-- --></span><span class="token variable">zxc</span><span class="token brackets"><span class="token punctuation">[</span><span class="token variable">$index</span><span class="token punctuation">]</span></span><span class="token punctuation">}</span>
<span class="token variable">zxc</span><span class="token brackets"><span class="token punctuation">[</span><span class="token variable">$index</span><span class="token punctuation">]</span></span><span class="token punctuation">=</span><span class="token variable">$temp</span>
<span class="token variable">done</span>
done
echo “经过直接排序后数组元素顺序为:${zxc[*]}”


3.反转排序
- 以相反的顺序把原有数组的内容重新排序
- 基本思想:把数组最后一个元素与第一个元素替换。倒数第二个元素与第二个元素替换,以此类推,直到把所有的数组元素反转替换完
#!/bin/bash
zxc=(10 20 30 40 50)
echo “现在的数组元素顺序为:${zxc[*]}”
long=${ #zxc[*]}
for ((i=0;i< l o n g < / s p a n > < s p a n c l a s s = " t o k e n p u n c t u a t i o n " > / < / s p a n > < s p a n c l a s s = " t o k e n n u m b e r " > 2 < / s p a n > < s p a n c l a s s = " t o k e n p u n c t u a t i o n " > ; < / s p a n > < s p a n c l a s s = " t o k e n v a r i a b l e " > i < / s p a n > < s p a n c l a s s = " t o k e n p u n c t u a t i o n " > + < / s p a n > < s p a n c l a s s = " t o k e n p u n c t u a t i o n " > + < / s p a n > < s p a n c l a s s = " t o k e n p u n c t u a t i o n " > ) < / s p a n > < s p a n c l a s s = " t o k e n p u n c t u a t i o n " > ) < / s p a n > < s p a n c l a s s = " t o k e n v a r i a b l e " > d o < / s p a n > < s p a n c l a s s = " t o k e n v a r i a b l e " > t e m p < / s p a n > < s p a n c l a s s = " t o k e n p u n c t u a t i o n " > = < / s p a n > < s p a n c l a s s = " t o k e n v a r i a b l e " > long</span><span class="token punctuation">/</span><span class="token number">2</span><span class="token punctuation">;</span><span class="token variable">i</span><span class="token punctuation">+</span><span class="token punctuation">+</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token variable">do</span> <span class="token variable">temp</span><span class="token punctuation">=</span><span class="token variable"> long</span><spanclass="tokenpunctuation">/</span><spanclass="tokennumber">2</span><spanclass="tokenpunctuation">;</span><spanclass="tokenvariable">i</span><spanclass="tokenpunctuation">+</span><spanclass="tokenpunctuation">+</span><spanclass="tokenpunctuation">)</span><spanclass="tokenpunctuation">)</span><spanclass="tokenvariable">do</span><spanclass="tokenvariable">temp</span><spanclass="tokenpunctuation">=</span><spanclass="tokenvariable">{ array[$i]}
<span class="token variable">zxc</span><span class="token brackets"><span class="token punctuation">[</span><span class="token variable">$i</span><span class="token punctuation">]</span></span><span class="token punctuation">=</span><span class="token variable">$</span><span class="token punctuation">{<!-- --></span><span class="token variable">zxc</span><span class="token punctuation">[</span><span class="token variable">$long-$i-</span><span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">}</span>
<span class="token variable">zxc</span><span class="token punctuation">[</span><span class="token variable">$long-$i-</span><span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">=</span><span class="token variable">$temp</span>
done
echo “反转后顺序为:${zxc[*]}”

















 1342
1342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









