







模型训练
一、数据集
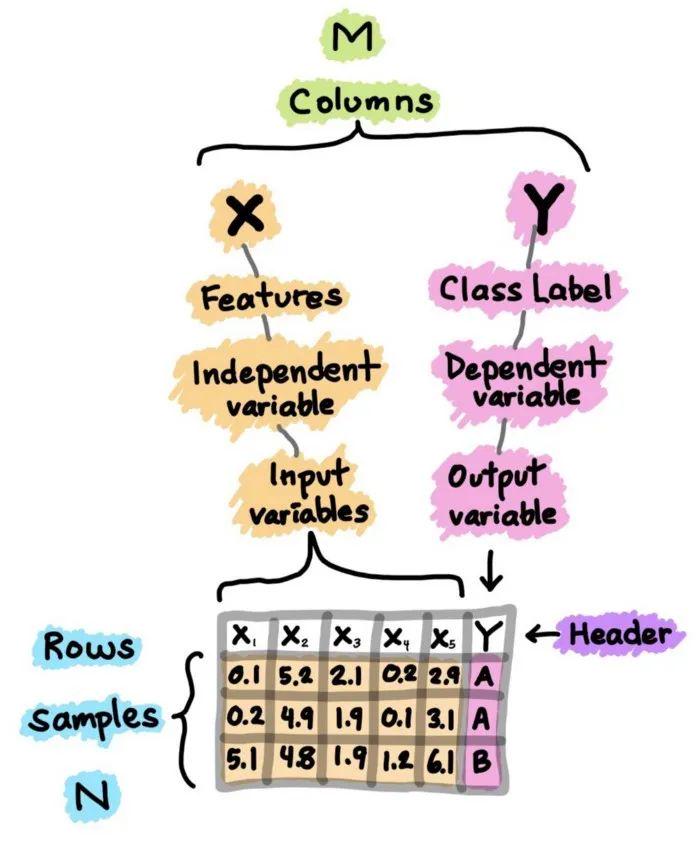
数据集作为模型训练的起点,时一切模型训练的基础之一。从本质上来说,数据集本质是一个M×N的矩阵,每一行代表不同的样本,每一列都是一种特征。而特征之中又可以分为X(一般是作为输入的特征),和Y(一般是作为输出和想要判断的结果的特征)。如下图所示。
(一)、探索性数据分析(EDA)
进行探索性数据分析(EDA)是为了获得对数据的初步了解。在一个典型的数据科学项目中,我会做的第一件事就是通过执行EDA来 “盯住数据”,以便更好地了解数据。
通常使用的三大EDA方法包括:
-
描述性统计:平均数、中位数、模式、标准差。
-
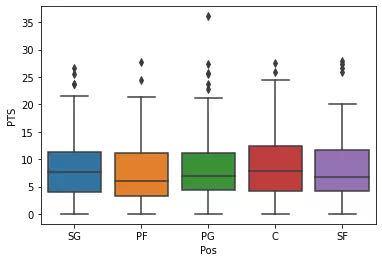
数据可视化:热力图(辨别特征内部相关性)、箱形图(可视化群体差异)、散点图(可视化特征之间的相关性)、主成分分析(可视化数据集中呈现的聚类分布)等。
-
数据整形:对数据进行透视、分组、过滤等。
(二)、数据预处理
主要是对数据集中的数据进行审查和处理,纠正错误和转换标签等,一般比较重要。
(三)、数据集分类与分割:
数据集一般可以分为以下三类:
-
训练数据集(test):用于训练模型的数据集,调整模型的参数等
-
验证数据集(val):用来评估模型好坏的数据集,和训练数据并不重合(一般取50%左右的训练数据集)
如果没有足够多的数据使用时,可以使用K-则交叉验证
algorithm
for i = 1,……k
使用第i块作为验证数据集,其余作为训练集
报告K个验证集误差的平均
-
测试数据集(test):一般是只用一次的数据集,用于测试模型训练的结果
数据集的分割也主要分为以下两种方式:
-
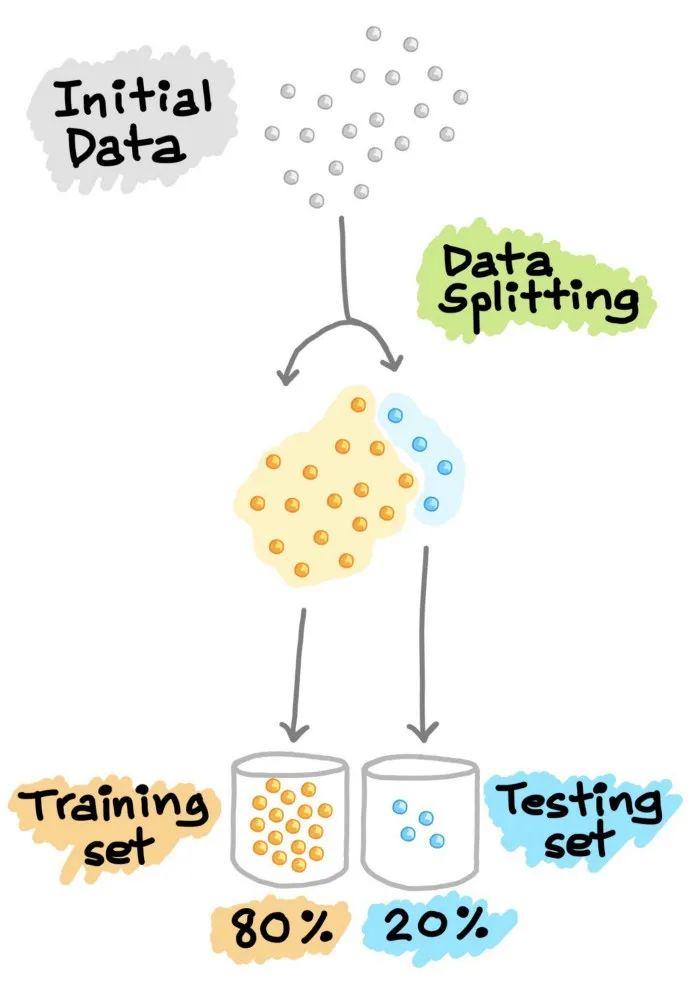
为了能将训练好的模型在新的、未见过的数据上也能表现良好,为了模拟新的、未见过的数据,对可用数据进行数据分割,从而将其分割成2部分(有时称为训练—测试分割)。特别是,第一部分是较大的数据子集,用作训练集(如占原始数据的80%),第二部分通常是较小的子集,用作测试集(其余20%的数据)。需要注意的是,这种数据拆分只进行一次。
接下来,利用训练集建立预测模型,然后将这种训练好的模型应用于测试集(即作为新的、未见过的数据)上进行预测。根据模型在测试集上的表现来选择最佳模型,为了获得最佳模型,还可以进行超参数优化。
-
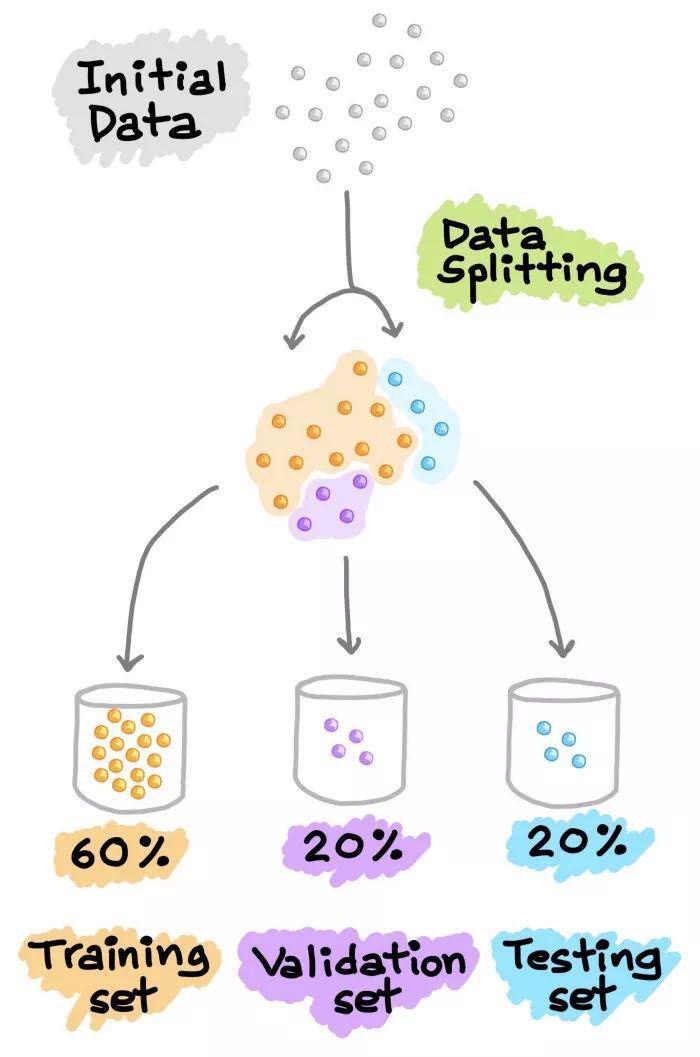
另一种常见的数据分割方法是将数据分割成3部分。(1) 训练集,(2) 验证集和(3) 测试集。与上面解释的类似,训练集用于建立预测模型,同时对验证集进行评估,据此进行预测,可以进行模型调优(如超参数优化),并根据验证集的结果选择性能最好的模型。正如我们所看到的,类似于上面对测试集进行的操作,这里我们在验证集上做同样的操作。请注意,测试集不参与任何模型的建立和准备。因此,测试集可以真正充当新的、未知的数据。
二、模型选择和建立
在处理好数据集之后,可以选择我们希望训练的模型进行优化或者搭建自己的模型,根据输出的数据类型,我们可以建立分类(输出Y是定性的)或者回归(如果Y是定量的)模型。
下面以yolov5模型为例,
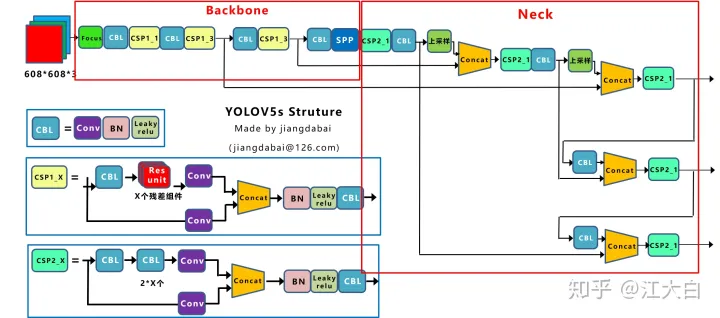
(一)、网络整体结构
其详细的网络结构图如下图所示:

Yolov5官方代码中,给出的目标检测网络中一共有4个版本,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x四个模型,以下是原作者对不同结构网络性能测试图。
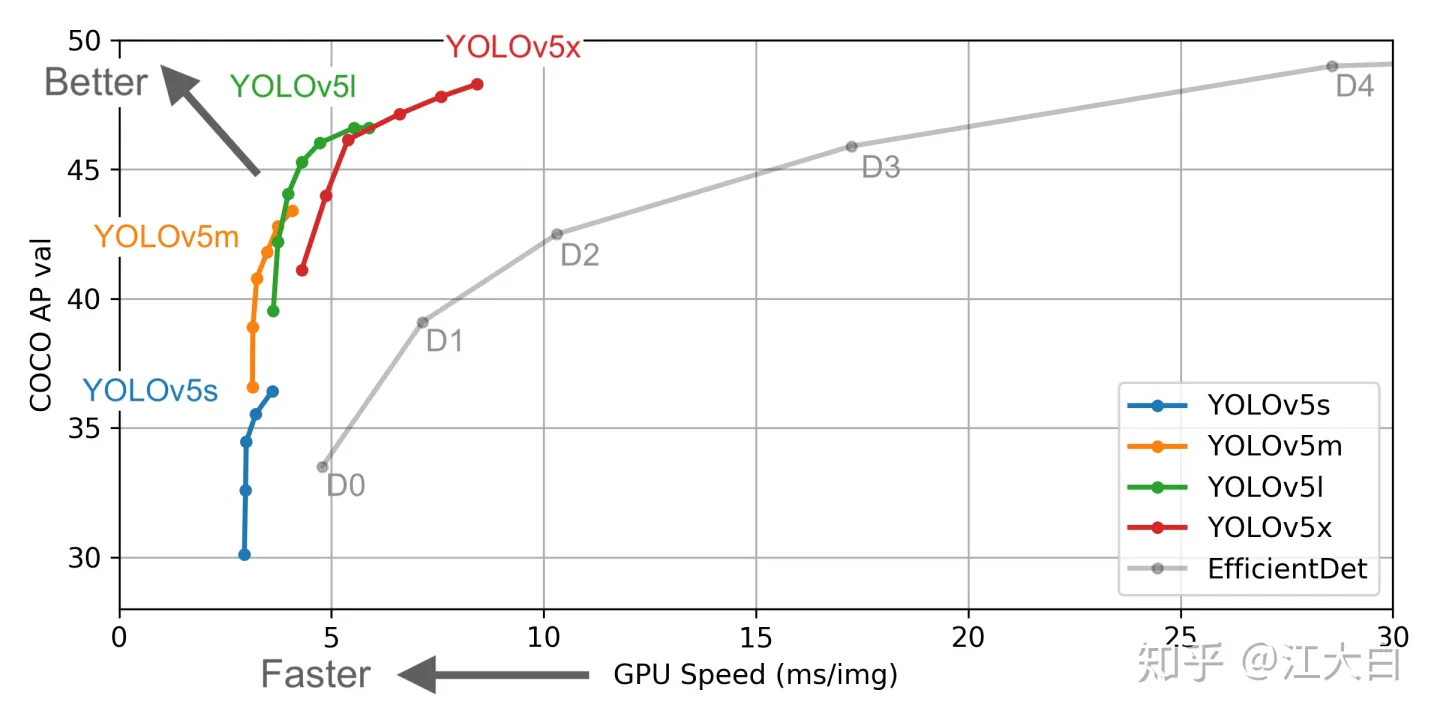
以其中模型最小的yolov5s为例,江大白老师绘制的结构简图如下图所示。Yolov5s网络是Yolov5系列中深度最小,特征图的宽度最小的网络。后面的yolov5m、l等都是在此基础上不断加深,不断加宽。
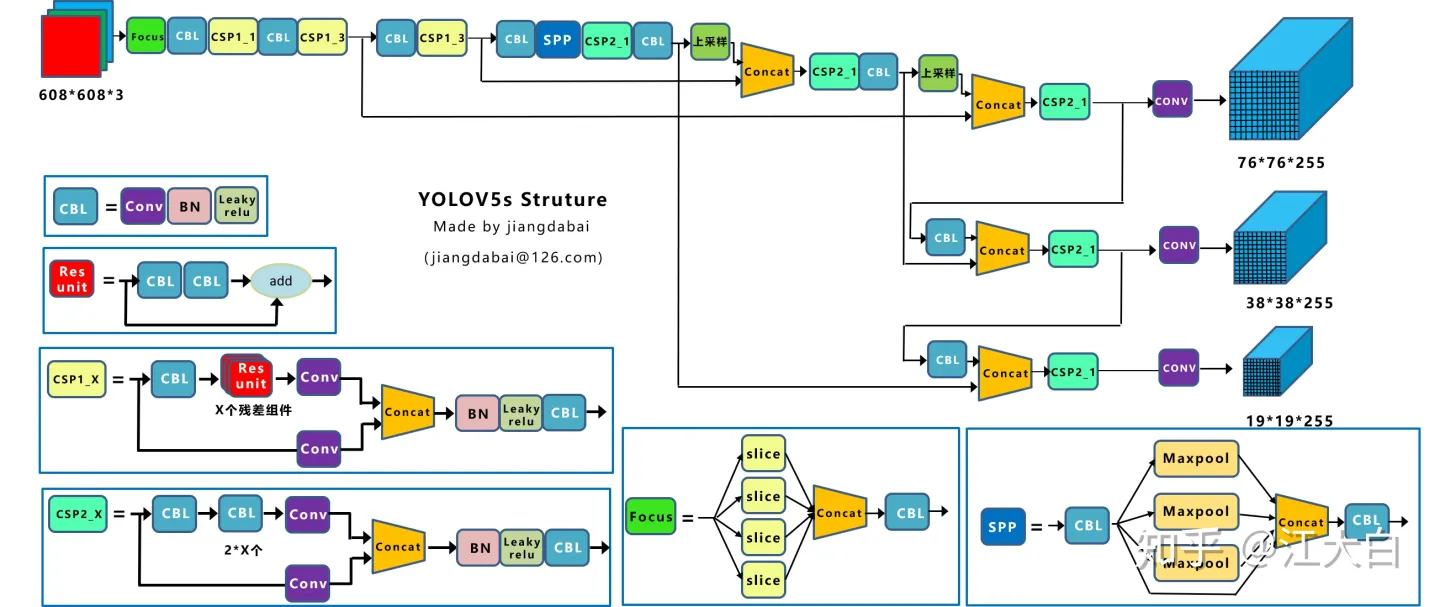
上图即Yolov5的网络结构图,可以看出,还是分为输入端、Backbone、Neck、Prediction四个部分。
(二)、yolov5详细网络分解
-
输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放
-
Mosaic数据增强提出的作者也是来自Yolov5团队的成员,不过,随机缩放、随机裁剪、随
机排布的方式进行拼接,对于小目标的检测效果还是很不错的。Mosaic是参考2019年底提出 的CutMix数据增强的方式,但CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。

-
在Yolo算法中,针对不同的数据集,都会有初始设定长宽的锚框。在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数.因此初始锚框也是比较重要的一部分,比如Yolov5在Coco数据集上初始设定的锚框:

但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。如果觉得不需要的话科研在train.py中上面一行代码,设置成False,每次训练时,不会自动计算。
-
自适应锚框计算。在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。
比如Yolo算法中常用416*416,608*608等尺寸,比如对下面800*600的图像进行缩放。Yolov5的代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。

-
Backbone:Focus结构,CSP结构
-
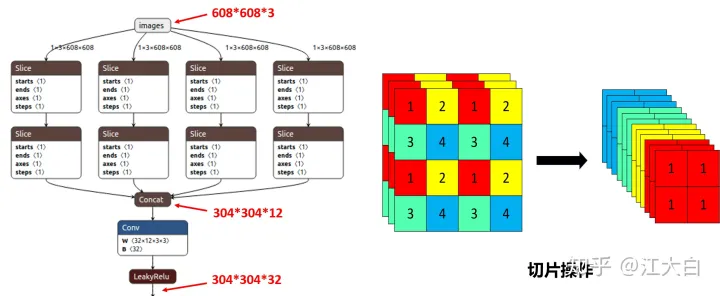
Focus结构:
在Yolov3&Yolov4中并没有这个结构,其中比较关键是切片操作。
比如下图的切片示意图,443的图像切片后变成2212的特征图。
以Yolov5s的结构为例,原始6086083的图像输入Focus结构,采用切片操作,先变成30430412的特征图,再经过一次32个卷积核的卷积操作,最终变成30430432的特征图。
需要注意的是:Yolov5s的Focus结构最后使用了32个卷积核,而其他三种结构,使用的数量有所增加,先注意下,后面会讲解到四种结构的不同点。
-
Yolov4网络结构中,借鉴了CSPNet的设计思路,在主干网络中设计了CSP结构。Yolov5与Yolov4不同点在于,Yolov4中只有主干网络使用了CSP结构。
而Yolov5中设计了两种CSP结构,以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
-
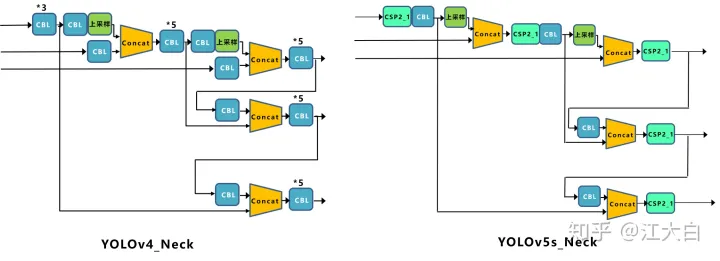
Neck:FPN+PAN结构
Yolov5现在的Neck和Yolov4中一样,都采用FPN+PAN的结构,但在Yolov5刚出来时,只使用了FPN结构,后面才增加了PAN结构,此外网络中其他部分也进行了调整。Yolov4的Neck结构中,采用的都是普通的卷积操作。而Yolov5的Neck结构中,采用借鉴CSPnet设计的CSP2结构,加强网络特征融合的能力。
-
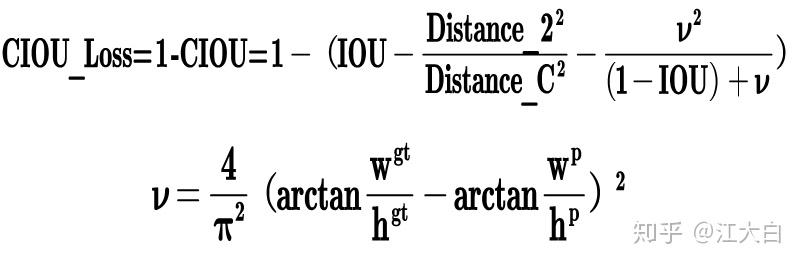
输出端Prediction:GIOU_Loss
-
Bounding box损失函数(进化为GIOU_Loss)
-
nms非极大值抑制
在训练过程中,目标检测算法会根据给定的ground truth调整深度学习网络参数来拟合数据集的目标特征,训练完成后,神经网络的参数固定,因而能够直接对新的图像进行目标预测。
然而,在实际的目标预测中,一般的目标检测算法(R-CNN,YOLO等等)都会产生非常多的目标框,其中有很多重复的框定位到同一个目标,NMS作为目标检测的最后一步,用来去除这些重复的框,获得真正的目标框。
NMS基本算法的具体步骤如下:
(1)依据框的分数(即目标的概率)将所有预测框排序;
(2)选择最大分数的检测框M,将其他与M框重叠度大(IoU超过阈值Nt)的框抑制;
(3)迭代这一过程直到所有框被检测完成。
在NMS中,使用小的阈值Nt(如0.3),将会更多的抑制附近的检测框,从而增加了错失率;而使用大的Nt(如0.7)将会增加假正的情况。当目标个数远远小于RoI个数时,假正的增加将会大于真阳的增加,因此高的NMS不是最优的。
以上是对整个yolov5s网络结构的简单介绍,其余类型仅仅是网络的深度和宽度有所不同
三、开始训练
当准备好我们的visdrone2021数据集、整个代码相关的依赖的python库之后(如果是原始的记得要将格式转化为yolov5的label格式),并且下载好了相关的yolov5的模型和源代码,便可以开始训练模型了,根据yolov5官方的指导,可以开始接下来一步步进行模型的训练了。
-
首先编写一个VisDrone.yaml文件。此文件主要用来说明数据集的位置和路径,以及检测的目标数量和类别。
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# VisDrone2019-DET dataset https://github.com/VisDrone/VisDrone-Dataset by Tianjin University
# Example usage: python train.py --data VisDrone.yaml
# parent
# ├── yolov5
# └── datasets
# └── VisDrone ← downloads here
#Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: E:\NJU\dl_ml\Vitis\yolov5\datasets\VisDrone # dataset root dir
train: VisDrone2019-DET-train # train images (relative to 'path') 6471 images
val: VisDrone2019-DET-val # val images (relative to 'path') 548 images
#test: VisDrone2019-DET-test-dev # test images (optional) 1610 images
# Classes
nc: 10 # number of classes
names: ['pedestrian', 'people', 'bicycle', 'car', 'van', 'truck', 'tricycle',-
修改yolov5/models/中的模型相关文件,比如若使用visdrone数据集共有10个类别,使用的yolov5s.yaml中的nc同样要修改为10.如下图所示。

-
在一切必要准备工作就绪之后,我们便可以开始用yolov5模型来训练我们的visdrone数据集了,其中训练时可以修改的参数和相关意义如下所示。
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/coco128.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--entity', default=None, help='W&B entity')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')
opt = parser.parse_args() 训练自己的模型需要修改如下几个参数就可以训练了。首先将weights权重的路径填写到对应的参数里面,然后将修好好的models模型的yolov5s.yaml文件路径填写到相应的参数里面,最后将data数据的hat.yaml文件路径填写到相对于的参数里面。这几个参数就必须要修改的参数。
parser.add_argument('--weights', type=str, default='weights/yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='models/yolov5s_hat.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/hat.yaml', help='data.yaml path')
***这就是刚刚三个文件的相对路径!这就是刚刚三个文件的相对路径!这就是刚刚三个文件的相对路径!***
还有几个需要根据自己的需求来更改的参数:-
在终端输入:
python train.py --参数……-
最终的结果保存至yolov5/runs/train/exp*中,里面包括以下文件:

其中包括:
-
weights权重文件,包括最好的best.pt和最后一次训练时的last.pt
-
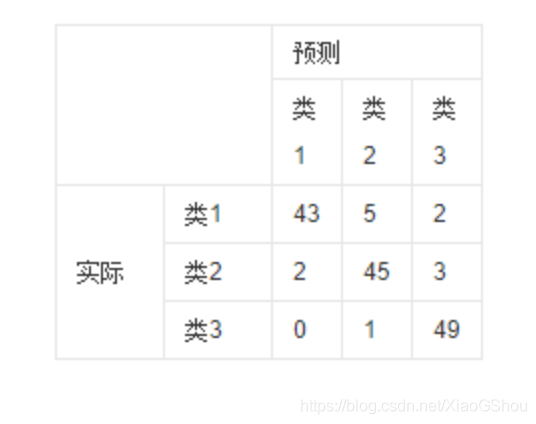
混淆矩阵:
①:混淆矩阵是对分类问题的预测结果的总结。使用计数值汇总正确和不正确预测的数量,并按每个类进行细分,这是混淆矩阵的关键所在。混淆矩阵显示了分类模型的在进行预测时会对哪一部分产生混淆。它不仅可以让我们了解分类模型所犯的错误,更重要的是可以了解哪些错误类型正在发生。正是这种对结果的分解克服了仅使用分类准确率所带来的局限性。
②:在机器学习领域和统计分类问题中,混淆矩阵(英语:confusion matrix)是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。矩阵的每一列代表一个类的实例预测,而每一行表示一个实际的类的实例。之所以如此命名,是因为通过这个矩阵可以方便地看出机器是否将两个不同的类混淆了(比如说把一个类错当成了另一个)。比较形象的解释就如下图所示。
-
TP/TN/FP/FN
①. 真阳性(True Positive,TP):样本的真实类别是正例,并且模型预测的结果也是正例,预测正确
②. 真阴性(True Negative,TN):样本的真实类别是负例,并且模型将其预测成为负例,预测正确
③. 假阳性(False Positive,FP):样本的真实类别是负例,但是模型将其预测成为正例,预测错误
④. 假阴性(False Negative,FN):样本的真实类别是正例,但是模型将其预测成为负例,预测错误

详情可见:【精选】yolov5训练结果解析_yolov5 结果-CSDN博客
-
F1_cureve:置信度和F1分数的关系图
-
hyp.yaml:超参数文件
-
labels.jpg
-
opt.yaml
-
P_curve.png:准确率和置信度的关系图
-
R_curve.png:召回率和置信度关系图
-
PR_curve.png:PR曲线中的P代表的是precision(精准率),R代表的是recall(召回率),其代表的是精准率与召回率的关系,一般情况下,将recall设置为横坐标,precision设置为纵坐标。PR曲线下围成的面积即AP,所有类别AP平均值即Map
-
results.png,其中包括:
①、Box:YOLO V5使用 GIOU Loss作为bounding box的损失,Box推测为GIoU损失函数均值,越小方框越准;
②、Objectness:推测为目标检测loss均值,越小目标检测越准;
③、Classification:推测为分类loss均值,越小分类越准;
④、Precision:精度(找对的正类/所有找到的正类);
⑤、Recall:真实为positive的准确率,即正样本有多少被找出来了(召回了多少)。
⑥、Recall从真实结果角度出发,描述了测试集中的真实正例有多少被二分类器挑选了出来,即真实的正例有多少被该二分类器召回。
⑦、val BOX: 验证集bounding box损失
⑧、val Objectness:验证集目标检测loss均值
⑨、val classification:验证集分类loss均值
⑩、mAP是用Precision和Recall作为两轴作图后围成的面积,m表示平均,@后面的数表示判定iou为正负样本的阈值,@0.5:0.95表示阈值取0.5:0.05:0.95后取均值。
mAP@.5:.95(mAP@[.5:.95])表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP。
mAP@.5:表示阈值大于0.5的平均mAP
一般训练结果主要观察精度和召回率波动情况(波动不是很大则训练效果较好)然后观察mAP@0.5 & mAP@0.5:0.95 评价训练结果。
map计算:
就是每个recall区间做相应的计算,即每个recall的区间内我们只取这个区间内precision的最大值然后和这个区间的长度做乘积,所以最后体现出来就是一系列的矩形的面积,还是以上面的那个例子为例,我们一共有recall一共变化了7次,我们就有7个recall区间要做计算,然后实际我们计算的时候人为的要把这个曲线变化成单调递减的,也就是对现有的precision序列要做一些处理,
6.根据训练的结果再次修改相关的参数进行微调。
四、训练性能指标
-
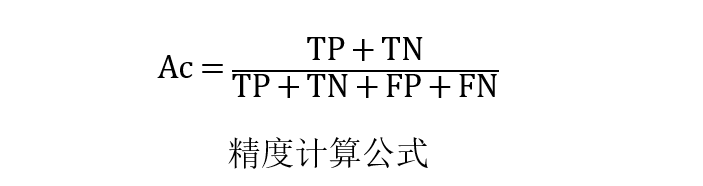
一些常见的评估分类性能的指标包括准确率(Ac)、灵敏度(Sn)、特异性(Sp)和马太相关系数(MCC)。下图是它们的计算公式:



-
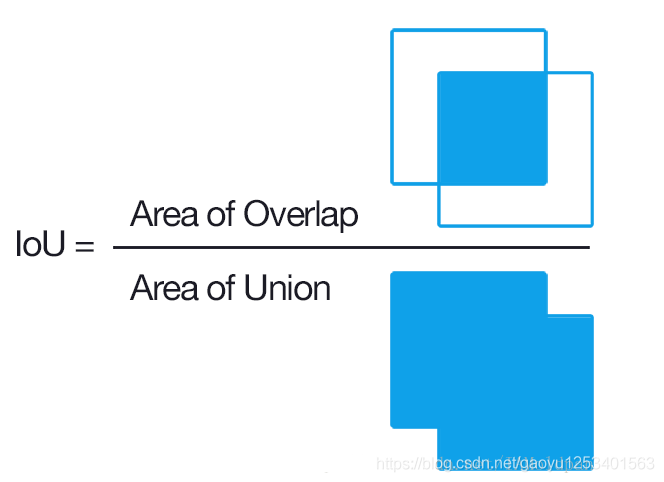
IoU(Intersection over Union)是一种测量在特定数据集中检测相应物体准确度的一个标准。IoU是一个简单的测量标准,只要是在输出中得出一个预测范围(bounding boxex)的任务都可以用IoU来进行测量。为了可以使IoU用于测量任意大小形状的物体检测,我们需要:
ground-truth bounding boxes(人为在训练集图像中标出要检测物体的大概范围)和我们的算法得出的结果范围。
也就是说,这个标准用于测量真实和预测之间的相关度,相关度越高,该值越高。如下图所示。
参考
以上总结参考了许多大佬的文件,如有侵权立马删除,以下是部分参考的视频及博客
yolo系列原理视频:4、 卷积的滑动窗口实现_哔哩哔哩_bilibili
yolov5代码解析:YOLOV5代码解析(更新中)-CSDN博客
yolov5官方git仓库相关issue:https://github.com/ultralytics/yolov5/issues
部分图文来自:https://gitcode.net/mirrors/dataprofessor/infographic?utm_source=csdn_github_accelerator

















 8395
8395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









