







查看原文:【数据seminar】Python教学 | Python 中的循环结构(下)【附本文代码和数据】
Part1引言
循环是使用编程处理数据时必备的编程技巧。在 Python 教学系列👉上期文章中(传送门:Python教学 | Python 中的循环结构(上)),我们向大家介绍了 Python 循环结构的基本概念和使用方法,主要包括以下内容:
遍历循环与无限循环的基本概念和使用方法
循环体的概念和range()函数
循环终止语句break与continue
熟练掌握以上内容之后,在数据处理过程中解决简单循环问题对我们来说已经是小菜一碟。不过当要解决更加复杂或特殊的问题时,我们还需要学习更多关于循环的编程技巧,这也是本期文章的目的。下面我们将向大家介绍Python 循环结构中更多实用的技巧,一起学习吧!
💡关注微信公众号 数据seminar 并在对话框内发送关键词“20230210”,即可获取文章中用到的样例数据和代码。
Part2同步遍历循环——使用zip()函数
在遍历循环最简单的用法中,循环体往往是一个包含多个元素的可迭代对象。比如列表、字典等单一的组合数据类型,在上期介绍循环的文章中,我们使用了一个 统计成立时间在 2018-2021年之间的家庭农场数量 的案例来介绍遍历循环。主要过程是在全国所有在市场监管部门登记在册的家庭农场数据中,使用 for 循环处理所有家庭农场的成立日期(如下图所示,截图仅为样例数据),循环过程中每遇到一个家庭农场成立日期在指定时间范围内的数据,统计值(初始值为 0)就会自动加一,循环结束后的统计值就是我们想要得到的结果。

这个案例的 Python 代码如下。
# 读取样例数据(随文赠送的)
data = pd.read_csv('./全国家庭农场成立日期(样例数据).csv')
# 成立日期字段转为日期类型
data['成立日期'] = data['成立日期'].astype('datetime64[ns]')
# 将表中成立时间这一字段转为列表,那么列表中的数据均是企业成立时间
ESDATE = list(data['成立日期'])
# 初始化目标统计值
Num = 0
# 使用 for 循环遍历列表 ESDATE
for date in ESDATE:
# date 就是列表 ESDATE 中的元素,也就是一个成立日期
# 设置判断条件判断是都是符合条件的日期
if 2018 <= date.year <= 2021:
Num += 1 # 日期符合条件,那么统计目标 Num 增加 1
# 循环结束后,输出统计值
print(f'2018-2021年,共有{Num}个家庭农场成立。') # 输出:2018-2021年,共有182855个家庭农场成立。在上面的案例中,循环体ESDATE是一个列表,其中包含了所有家庭农场的成立时间。如下图所示:

现在我们换一个需求,要求 获取所有成立时间在2018-2021年之间的家庭农场的企业名称和成立时间 。这时我们发现, 仅循环成立时间列表的话只能得到符合要求的家庭农场的数量或成立时间,却无法得到这些家庭农场的名称。比较稳妥的做法是同时循环企业名称列表和企业成立时间列表,那么在每一次循环中同时存在一家企业(家庭农场)的名称和成立日期,如果成立日期符合要求,我们获取企业名称和成立时间就可以了。
迎面而来的问题是怎么样才能同步循环这两个列表呢?答案是使用 Python 内置的 zip()函数。
在 Python 3.x 版本中,zip()函数的功能是返回一个元组迭代器,这样说非常不直观,下面我们用一个例子帮助大家理解。
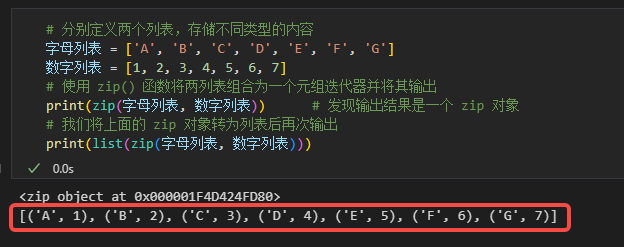
观察上图中红色方框中的内容,会发现zip()函数将图中的字母列表和数字列表中的元素按顺序一 一绑定对应起来,每一组绑定的结果都使用元组保存。而这个结果是我们将其转为列表之后才观察得到的,而zip()函数本身返回的结果则是一个无法直观看到任何内容的迭代器(见代码输出结果中的<zip object at 0x000001F4D424FD80>),这是因为迭代器是一个占用内存很少的类型,这种做的目的就是帮助我们节省内存。说到这里,我们应该如何使用zip()函数做到同步循环两个列表呢?请看下图。
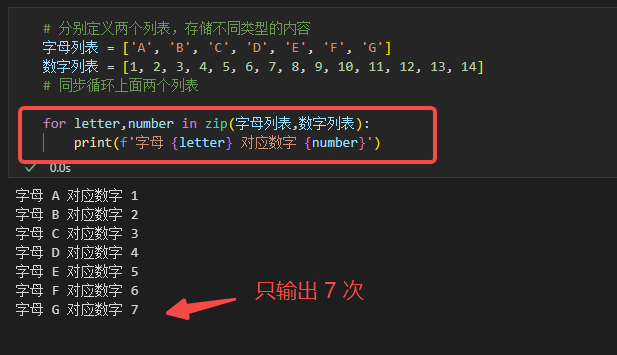
在上图所示的 for 循环中使用zip()函数, 发现每一次循环中的字母和数字都是按顺序对应的。另外,笔者故意将数字列表的长度设置的更长,最后我们发现,当zip()函数中的多个对象长度不一致时候,会按照木桶原理返回一个长度与zip()中最短对象的长度相同的迭代器,其他较长对象中多余的元素会被舍弃。
回到解决问题的立场上来,我们发现掌握了zip()函数的用法之后,这个问题就迎刃而解了,具体代码如下。
# 将表中成立时间这一字段转为列表,则列表中的元素值均是家庭农场成立日期
ENTNAME = list(data['企业名称'])
ESDATE = list(data['成立日期'])
# 用于存储符合条件的企业名称的列表
TARGET_NAME_DATE = []
# 使用 for 循环遍历列表 ENTNAME 和 ESDATE
for name, date in zip(ENTNAME, ESDATE):
# name 是列表 ENTNAME 中的元素。即企业名称
# date 是列表 ESDATE 中的元素。也就是成立日期
# 此时 name 和 date 是对应的,date 就是 name 的成立日期
# 设置判断条件判断是否是符合条件的日期
if 2018 <= date.year <= 2021:
TARGET_NAME_DATE.append([name, date]) # 每有一个家庭农场的成立时间符合要求,目标统计值就会加 1
# 循环结束后, 将符合要求的企业名称列表转为表格,使用到 pandas 模块
TARGET_TABLE = pd.DataFrame(TARGET_NAME_DATE,
columns=['2018-2021成立的家庭农场的名称', '成立时间'])
TARGET_TABLE所得结果如下图所示。

Part3添加索引循环——使用enumrate()函数
一般的遍历循环往往是遍历循环体中的每一个元素。而在一些特殊的需求中,我们需要在循环中添加循环元素在循环体中的索引。此时只需要在循环体外加上 enumrate()函数,那么循环中就既含有循环体中的元素,又包括该元素在循环体中的索引值。如下图所示。

以上就是 enumrate()函数的功能。同 zip() 函数一样,enumrate()函数也是 Python 内置的函数,并且enumrate()函数的返回结果也是一个迭代器。下面我们通过一个解决实际问题的场景说明 enumrate() 的作用。
问题提出:有一个占用空间很大的 csv 文件,我们希望快速的了解这个 csv 数据的数据量,但是由于这个文件占用空间太大了,如果使用 Stata、Python 等工具来导入这个文件,可能会导致计算机内存不足。此时我们可以使用遍历循环 + enumrate()函数的方式来获取这个文件的行数,也就是数据量。
💡 csv 是一种可以表示表结构的文本文件,文件后缀名为 “.csv” 。我们可以使用 Excel、WPS 等工具打开 csv 文件,打开后就是表格形式;也可以以文本文件方式打开 csv 文件,打开后是文本,此时文本中的一行内容就表示表格中的一行内容,也就是说文本的行数就是该 csv 表格的行数(数据量)。

解决以上问题的 Python 代码如下。
# 这里使用随文赠送的 csv 文件,该文件的编码为 utf-8
for count,row in enumerate(open('./全国家庭农场成立日期(样例数据).csv', 'rU', encoding='utf-8')): pass
count # 循环结束后,count 就是 csv 文件的行数(表头不算在内)以上代码的原理就是循环读取 csv 的每一行数据,每次只读取一行数据(代码中的 row),因此只会占用极少的内存空间。使用 enumrate()函数后还能得到循环中一行数据在整个数据中的索引(代码中的count,也就是一行数据的序号)。在每一次循环中,我们什么都不处理(代码中的pass表示跳过),这样能最快速的结束循环,循环结束后的变量 count 就是 csv 文件中最后一行数据的索引值,也就是 csv 文件的总行数。在这个场景中enumerate()函数节省内存和获取索引的特性被完全发挥了出来。
Part4循环中的异常处理——使用 try-except 语句
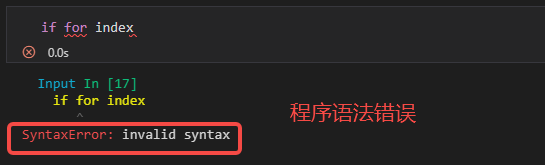
程序异常是我们常说的“报错”中的一种,“报错”可以分为两大类,一类是语法错误(SyntaxError),另一类是程序异常(Exception),它是在程序没有语法错误的前提下发生的。如下图所示。

无论是程序错误还是程序异常,只要程序报告错误,就会立刻停止运行。我们在使用 Python 时遇到程序报告语法错误,只需要找到语法错误的语句并改正就好了。如果在一般程序中遇到程序异常,我们可以分析异常原因并加以改正。可是一旦在循环程序中遇到程序异常就不好办了,因为循环程序一般会重复运行很多次循环代码,所以在一个完整的循环中,程序异常的具体类型和发生异常的次数是不可控的。因此我们必须掌握 Python 中能够处理程序异常的的语法。
Python 中通常使用try-except语句实现异常处理,下面我们来介绍这个语句的不同用法。
用法1:平等处理所有异常
try-except语句最简单粗暴的用法的语法如下。
try:
<语句块1>
except:
<语句块2>在循环中,我们可以把容易出现异常的代码放在try语句下的<语句块1>中,表示系统尝试执行这段代码,如果执行try下面的代码块时没有触发异常,系统会跳过except语句,进而执行整个try-except之后的代码。而一旦try下面的代码块触发异常(包括任何异常类型),Python 不会立即报告异常,而是会找到except语句并执行下面的<语句块2>。但是如果<语句块2>也触发异常,那么程序则会报告异常并停止运行。
用法2:针对处理某种异常
在上面的try-except语法中,只要try语句下的代码一旦触发异常(不包括语法错误),那么不管是何种异常类型,程序都会跳到except语句下的代码。这种“一刀切”的做法既有利也有弊,利在于给程序员减少了很多麻烦,弊则是程序对不同类型异常的识别和处理方式不够精准。
try-except语句提供了另外一种精准处理某种异常的做法,使用语法如下。
try:
<语句块1>
except <异常类型x>:
<语句块2>这种用法与 用法1 最大的区别就是,用法1 中的try-except语句会处理所有类型的异常,而这种用法则只针对<异常类型x>做处理。如果<语句块1>中触发异常且异常类型为<异常类型x>,那么程序会执行except语句下的<语句块2>;而如果触发异常的类型不是<异常类型x>,此时程序就会正常地报告异常,随后停止运行。也就是说,这种用法只针对<异常类型x>给出了解决方案,对其他的异常类型不起任何作用。
用法3:针对处理多种异常
在 用法2 中我们只对一种异常类型做针对处理,实际上我们还可以在 用法2 的基础上做扩展,实现对多种不同异常类型的针对处理,语法如下。
try:
<语句块1>
except <异常类型x>:
<语句块2>
except <异常类型y>:
<语句块3>
except <异常类型z>:
<语句块4>
……上述代码对try语句下的<语句块1>中可能触发的三种异常类型x、y、z分别做了针对处理。若<代码块1>触发<异常类型x>则执行<语句块2>;触发<异常类型y>则执行<语句块3>;触发<异常类型z>则执行<语句块4>……除此之外,try-except语句还有else子句和finally子句,不过这些子句的使用场景极其少,其作用对数据分析者来说十分鸡肋,一般只有在一些大型项目的源代码中才能看到,这里就不再过多介绍了。
以上三种 Python 使用try-except语句处理异常的用法中,前两种用法的使用频率更高些。在数据处理过程中,如果需要使用异常处理,绝大多数情况下,使用本文所介绍的用法1已经足够解决问题。下面我们通过一个实际案例简单介绍一下try-except语句的使用场景。
案例:很多时候我们需要 OCR 识别一些 pdf 文件或图片文件,将其中的表格转化为可编辑可分析的 Excel 表。例如这里我们 OCR 识别中国城市统计年鉴中的表格并获取各项指标。部分原件如下图所示。

我们对该文件做 OCR 识别,转为 Excel 表后再进行整合处理,得到下图所示指标统计表。

由于表格是使用 OCR 技术识别的,所以上表中“指标取值”这一字段中的数值都是字符型。不过由于部分原件比较模糊且 OCR 技术的识别率不够高,导致一些数字指标的识别可能出现差错,如下图所示。
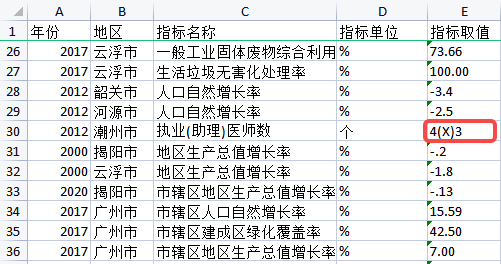
对于上图所示识别出错的指标,我们需要人工查找原件进行核对,问题是如何定位到所有可能识别出错的指标呢?我们的方法是借助 Python 的内置函数 eval() 来处理。这个函数的功能是将传入的字符串当做表达式来求值并返回计算结果,如下图所示。

处理的主要思路是使用 eval() 函数循环处理表中“指标取值”这一字段,将指标数值由字符型一 一转为数值型(整数或浮点数),并且在循环中使用try-except语句,如果在try语句中遇到不能转为数值的数据,那么程序会触发异常(这也是为什么不能使用判断语句进行处理的原因),这时我们返回一个自定义的标记,循环结束后再根据这个标记就可以找到可能识别出错的指标并人工核对。具体的代码如下。
结果如下。
# 读取数据
data = pd.read_excel('./中国城市统计年鉴(样例数据).xlsx')
# 添加新的字段,用于存放 eval() 函数转化后的指标数值。
data['指标取值(数值)'] = ''
for i in data.index:
# i 是数据 data 的行索引
value_str = data['指标取值'][i] # 根据行索引获取指标值(字符型)
# 尝试将字符型指标转为数字型并填充到新的字段中
try:
data['指标取值(数值)'][i] = eval(value_str)
except:
# 如果 eval(value_str) 触发异常,说明数值可能识别错误了,
# 这里我们将一个特殊的标记填入新字段中
data['指标取值(数值)'][i] = '识别可能出错!'循环结束后,我们利用设置的特殊标记找到所有可能识别出错的数据,代码和结果如下。
# 找到新字段中的值等于我们设置的标记的数据
data[data['指标取值(数值)'] == '识别可能出错!']
最后根据上面的结果找到所有可能识别出错的结果,然后人工核对、修改即可。
以上就是 Python 程序异常处理语句try-except的一个简单应用场景。
Part5结束语
本期文章我们向大家介绍了循环结构中几个非常实用的技巧,其中以下内容的使用频率比较高。
同步遍历循环中 zip()函数的使用
程序异常处理try-except语句的使用
读完本文之后,大家不要忘记好好练习,熟练使用之后,相信大家再次遇到复杂的循环问题时,一定会临危不乱、胸有成竹、胜券在握、举棋若定、十拿九稳、稳操胜券、得心应手、十捉九着、运筹帷幄、成竹在胸、易如反掌、手到擒来、万事顺遂、心想事成、福如东海、寿比南山!
下期再见。
💡 关注微信公众号 数据seminar 并在对话框内发送关键词“20230210”,即可获取文章中用到的样例数据和代码。















 2041
2041











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









