







查看原文:【数据seminar】数据治理 | 数据采集实战:静态网页数据采集
我们将在数据治理板块中推出一系列原创推文,帮助读者搭建一个完整的社科研究数据治理软硬件体系。该板块将涉及以下几个模块:
计算机基础知识
编程基础
(1)数据治理 | 带你学Python之 环境搭建与基础数据类型介绍篇
(4)数据治理 | 还在用Excel做数据分析呢?SQL它不香吗
(5)数据治理 | 普通社科人如何学习SQL?一篇文章给您说明白
数据采集
(2)本期内容:数据治理 | 采集实战操作篇:静态网页数据采集
数据存储
(1)安装篇 数据治理 | 遇到海量数据stata卡死怎么办?这一数据处理利器要掌握
(2)管理篇 数据治理 | 多人协同处理数据担心不安全?学会这一招,轻松管理你的数据团队
(3)数据导入数据治理 | “把大象装进冰箱的第二步”:海量微观数据如何“塞进”数据库?
数据清洗
数据实验室搭建
目录
Part 1 引言
大数据时代的社科研究者非常有必要了掌握数据采集技能,前期推文我们已经讲解了数据采集的基本知识,本文主要介绍如何采集静态网页的数据。
在网站设计中,纯粹HTML格式的网页通常被称为静态网页。静态网站的特点是,所有的数据都呈现在网页的HTML源代码中。
本文基于Stata工具包的下载网站进行数据采集的演示,网址链接:http://fmwww.bc.edu/RePEc/bocode/,我们的目标是将Stata模块下载并保存到本地,我们会一步一步的演示下载的流程。
Part 2 手动演示Stata模块的下载
在演示Python自动化下载之前,我们先演示手动下载的方式。
(一)登陆网站
在浏览器中输入:http://fmwww.bc.edu/RePEc/bocode/ ,登录网站首页。
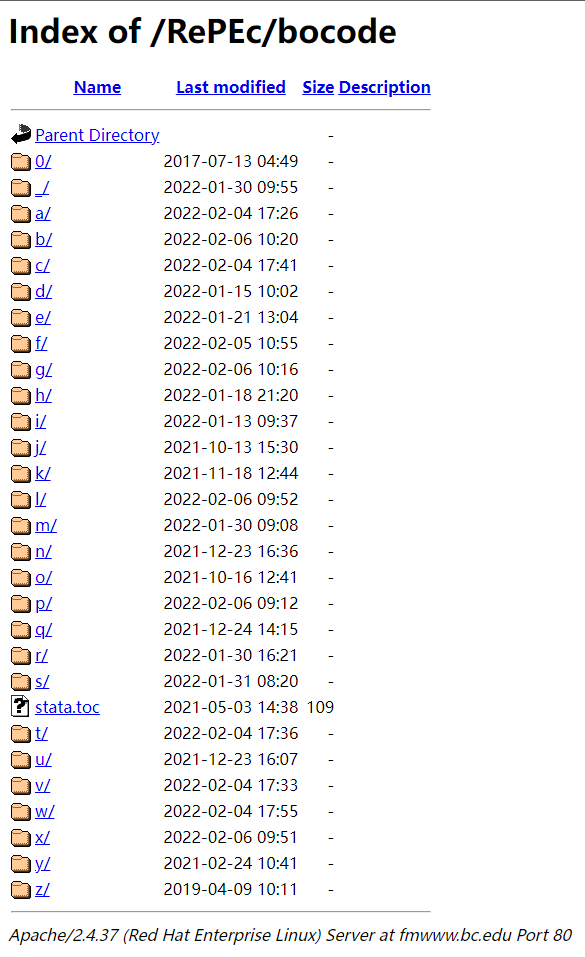
(二)选择模块所在的文件夹
比如说我们想要下载aaniv.ado这个文件,就要先进入其所在的文件夹:

(三)下载需要的Stata模块
比如说我们想要下载aaniv.ado这个文件,就需要先选定文件,然后再右键选择链接另存为,操作如下:

Part 3 用Python自动化下载
上面我们演示了手动下载的方法,如果我们需要把该网页上所有的模块全部下载下来,面对这么多的模块的情况下,手动下载的方式非常耗时,为了方便下载,我们可以使用Python进行自动化下载。
(一)登录网站
1. 通过开发者工具分析首页
在编写爬虫脚本之前,需要先分析网页的请求流程和特征,针对指定的流程才能编写特定的爬虫脚本。
-
打开网站,F12打开浏览器开发者工具(本文使用谷歌浏览器),选择Network网络面板。
-
刷新页面进行网络抓包。
-
查找数据在哪个网络请求中返回。

通过观察,我们发现在请求名称为bocode/包中的中找到了网页返回的数据内容。(Response栏中可以查看网页给我们返回的数据)。我们也可以直接使用搜索按钮,来快速的定位:
-
点击搜索按钮。
-
在搜索框输入想要搜索的内容。
-
点击内容,即可快速的定位。

该网站的数据与HTML网站源代码一并的返回,说明该网站为静态网页。
通过上述的分析,我们可以得出一个结论:网页的数据是在HTML源代码里面的,我们可以直接请求网页的源代码,之后可以利用解析数据的工具提取出我们想要的数据。
2. 用Python登录网站获取首页
我们想要获取网站的首页内容,就需要向对方服务器发起请求,在Python中发起网络请求的模块为requests,requests为Python的第三方模块,所以我们需要安装一下:pip install requests。
import requests # 导入第三方模块
# 1.确定目标 URL
url = 'http://fmwww.bc.edu/RePEc/bocode/'
# 2.利用 requests的 get方法向对方服务器发送 GET请求
res = requests.get(url)
# 3.获取文本数据(网站的html内容)
res_text = res.text
print(res_text)
执行结果:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">
<html>
<head>
<title>Index of /RePEc/bocode</title>
</head>
<body>
<h1>Index of /RePEc/bocode</h1>
<table>
<tr><th valign="top"><img src="/icons/blank.gif" alt="[ICO]"></th><th><a href="?C=N;O=D">Name</a></th><th><a href="?C=M;O=A">Last modified</a></th><th><a href="?C=S;O=A">Size</a></th><th><a href="?C=D;O=A">Description</a></th></tr>
<tr><th colspan="5"><hr></th></tr>
<tr><td valign="top"><img src="/icons/back.gif" alt="[PARENTDIR]"></td><td><a href="/RePEc/">Parent Directory</a></td><td> </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="0/">0/</a></td><td align="right">2017-07-13 04:49 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="_/">_/</a></td><td align="right">2022-01-30 09:55 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="a/">a/</a></td><td align="right">2022-02-04 17:26 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="b/">b/</a></td><td align="right">2022-02-06 10:20 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="c/">c/</a></td><td align="right">2022-02-04 17:41 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="d/">d/</a></td><td align="right">2022-01-15 10:02 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="e/">e/</a></td><td align="right">2022-01-21 13:04 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="f/">f/</a></td><td align="right">2022-02-05 10:55 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="g/">g/</a></td><td align="right">2022-02-06 10:16 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="h/">h/</a></td><td align="right">2022-01-18 21:20 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="i/">i/</a></td><td align="right">2022-01-13 09:37 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="j/">j/</a></td><td align="right">2021-10-13 15:30 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="k/">k/</a></td><td align="right">2021-11-18 12:44 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="l/">l/</a></td><td align="right">2022-02-06 09:52 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="m/">m/</a></td><td align="right">2022-01-30 09:08 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="n/">n/</a></td><td align="right">2021-12-23 16:36 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="o/">o/</a></td><td align="right">2021-10-16 12:41 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="p/">p/</a></td><td align="right">2022-02-06 09:12 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="q/">q/</a></td><td align="right">2021-12-24 14:15 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="r/">r/</a></td><td align="right">2022-01-30 16:21 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="s/">s/</a></td><td align="right">2022-01-31 08:20 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/unknown.gif" alt="[ ]"></td><td><a href="stata.toc">stata.toc</a></td><td align="right">2021-05-03 14:38 </td><td align="right">109 </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="t/">t/</a></td><td align="right">2022-02-04 17:36 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="u/">u/</a></td><td align="right">2021-12-23 16:07 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="v/">v/</a></td><td align="right">2022-02-04 17:33 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="w/">w/</a></td><td align="right">2022-02-04 17:55 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="x/">x/</a></td><td align="right">2022-02-06 09:51 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="y/">y/</a></td><td align="right">2021-02-24 10:41 </td><td align="right"> - </td><td> </td></tr>
<tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="z/">z/</a></td><td align="right">2019-04-09 10:11 </td><td align="right"> - </td><td> </td></tr>
<tr><th colspan="5"><hr></th></tr>
</table>
<address>Apache/2.4.37 (Red Hat Enterprise Linux) Server at fmwww.bc.edu Port 80</address>
</body></html>
(二)解析首页数据获取文件夹路径
我们使用Python的正则语法来解析网站给我们返回的数据,也需要导入正则的模块import re,与requests模块的不同的是,re模块是Python的内置模块,所以不需要额外的安装。
我们可以在Response栏中看到html的格式如下:

在观察响应后发现,相对链接href都由<a>标签包裹,日期都是由<td>标签包裹,所以我们可以使用正则语法,将这些数据解析出来:
import requests
import re # 导入正则模块
url = 'http://fmwww.bc.edu/RePEc/bocode/'
res = requests.get(url)
res_text = res.text
# 解析数据
rule_index = '<a href="(.*?)">..</a></td><td align="right">(.*?)..</td>'
info_list = re.findall(rule_index, res_text) # 利用正则语法取出我们需要的文件内容
# 遍历列表,并格式化输出
for info in info_list:
item = dict()
item['detail_url'] = url + info[0] # 将相对路径拼接成绝对路径
item['update_time'] = info[1]
print(item)
执行结果:
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/0/', 'update_time': '2017-07-13 04:49'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/_/', 'update_time': '2022-01-30 09:55'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/a/', 'update_time': '2022-02-04 17:26'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/b/', 'update_time': '2022-02-06 10:20'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/c/', 'update_time': '2022-02-04 17:41'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/d/', 'update_time': '2022-01-15 10:02'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/e/', 'update_time': '2022-01-21 13:04'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/f/', 'update_time': '2022-02-05 10:55'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/g/', 'update_time': '2022-02-06 10:16'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/h/', 'update_time': '2022-01-18 21:20'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/i/', 'update_time': '2022-01-13 09:37'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/j/', 'update_time': '2021-10-13 15:30'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/k/', 'update_time': '2021-11-18 12:44'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/l/', 'update_time': '2022-02-06 09:52'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/m/', 'update_time': '2022-01-30 09:08'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/n/', 'update_time': '2021-12-23 16:36'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/o/', 'update_time': '2021-10-16 12:41'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/p/', 'update_time': '2022-02-06 09:12'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/q/', 'update_time': '2021-12-24 14:15'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/r/', 'update_time': '2022-01-30 16:21'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/s/', 'update_time': '2022-01-31 08:20'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/t/', 'update_time': '2022-02-04 17:36'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/u/', 'update_time': '2021-12-23 16:07'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/v/', 'update_time': '2022-02-04 17:33'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/w/', 'update_time': '2022-02-04 17:55'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/x/', 'update_time': '2022-02-06 09:51'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/y/', 'update_time': '2021-02-24 10:41'}
{'detail_url': 'http://fmwww.bc.edu/RePEc/bocode/z/', 'update_time': '2019-04-09 10:11'}Tip: a标签的 href 属性用于指定超链接目标的 URL,这边为相对路径。
(三)下载Stata模块
上面我们只是访问的首页的数据,我们实际需求是将Stata的包下载下来保存到本地以便使用。
为此我们还需要请求详情页的数据,然后对详情页的数据进行解析,之后再下载所有的Stata包。
1.获取Stata模块的路径
请求详情页的数据跟我们请求首页的数据是一样的,只是修改了请求的URL而已:
import requests
import re
import time
url = 'http://fmwww.bc.edu/RePEc/bocode/'
res = requests.get(url)
res_text = res.text
rule_index = '<a href="(.*?)">..</a></td><td align="right">(.*?)..</td>'
info_list = re.findall(rule_index, res_text)
for info in info_list:
# 发送详情页的请求
detail_url = url + info[0] # 将相对路径拼接成绝对路径
res_detail = requests.get(detail_url)
# 解析数据
detail_text = res_detail.text
rule_detail = '<a href="(.*?)">(.*?)</a></td><td align="right">'
item_list = re.findall(rule_detail, detail_text)
# 格式化输出,打印详情页每个Stata包的 url和 name
for item in item_list:
dic = {
'file_url': detail_url + item[0],
'file_name': item[1]
}
print(dic)
time.sleep(1) # 挂起程序1秒,防止请求过快
执行结果(部分):
{'file_url': 'http://fmwww.bc.edu/RePEc/bocode/0/stata.toc', 'file_name': 'stata.toc'}
{'file_url': 'http://fmwww.bc.edu/RePEc/bocode/0/wagegap.hlp', 'file_name': 'wagegap.hlp'}
{'file_url': 'http://fmwww.bc.edu/RePEc/bocode/0/wagegap.pkl', 'file_name': 'wagegap.pkl'}
{'file_url': 'http://fmwww.bc.edu/RePEc/bocode/_/_adjksm.ado', 'file_name': '_adjksm.ado'}
{'file_url': 'http://fmwww.bc.edu/RePEc/bocode/_/_adminregion.ado', 'file_name': '_adminregion.ado'}
{'file_url': 'http://fmwww.bc.edu/RePEc/bocode/_/_adminregion_iso2.ado', 'file_name': '_adminregion_iso2.ado'}
{'file_url': 'http://fmwww.bc.edu/RePEc/bocode/_/_adminregionname.ado', 'file_name': '_adminregionname.ado'}
{'file_url': 'http://fmwww.bc.edu/RePEc/bocode/_/_api_read.ado', 'file_name': '_api_read.ado'}
2.下载Stata模块
我们可以根据文件的URL,将文件进行下载,在下载并保存文件之前,需要先创建文件夹,在Python中创建文件夹的方法可以用内置的os模块。
import requests
import re
import time
import os
def download_model():
url = 'http://fmwww.bc.edu/RePEc/bocode/'
res = requests.get(url)
res_text = res.text
rule_index = '<a href="(.*?)">..</a></td><td align="right">(.*?)..</td>'
info_list = re.findall(rule_index, res_text)
for info in info_list:
# 创建子文件夹
dir_path = os.path.join(total_dir, info[0]) # 拼接路径
os.mkdir(dir_path)
# 发送详情页的请求
detail_url = url + info[0] # 将相对路径拼接成绝对路径
res_detail = requests.get(detail_url)
# 解析数据
detail_text = res_detail.text
rule_detail = '<a href="(.*?)">(.*?)</a></td><td align="right">'
item_list = re.findall(rule_detail, detail_text)
# 遍历详情页的数据
for item in item_list:
# 文件url
file_url = detail_url + item[0]
# 发送下载文件请求
file_res = requests.get(file_url)
# 模块文件名
file_name = item[1]
# 文件保存的路径
save_path = os.path.join(dir_path, file_name)
# 保存文件
with open(save_path, 'wb') as file:
file.write(file_res.content)
print(file_name, '保存完毕!')
time.sleep(0.5) # 挂起程序0.5秒,防止请求过快
if __name__ == '__main__':
# 创建总文件夹
total_dir = 'Stata_Model'
os.mkdir(total_dir)
# 下载Stata模块
download_model()
执行效果(部分):

Part 4 总结
文本讲述了静态网站的采集实战,考虑到读者的编程能力,我们没有使用多线程进行爬取,后续我们还会推出《动态网页数据采集》实战推文,敬请期待。
附件:stata_download.py
import requests
import re
import time
import os
def download_model():
url = 'http://fmwww.bc.edu/RePEc/bocode/'
res = requests.get(url)
res_text = res.text
rule_index = '<a href="(.*?)">..</a></td><td align="right">(.*?)..</td>'
info_list = re.findall(rule_index, res_text)
for info in info_list:
# 创建子文件夹
dir_path = os.path.join(total_dir, info[0]) # 拼接路径
os.mkdir(dir_path)
# 发送详情页的请求
detail_url = url + info[0] # 将相对路径拼接成绝对路径
res_detail = requests.get(detail_url)
# 解析数据
detail_text = res_detail.text
rule_detail = '<a href="(.*?)">(.*?)</a></td><td align="right">'
item_list = re.findall(rule_detail, detail_text)
# 遍历详情页的数据
for item in item_list:
# 文件url
file_url = detail_url + item[0]
# 发送下载文件请求
file_res = requests.get(file_url)
# 模块文件名
file_name = item[1]
# 文件保存的路径
save_path = os.path.join(dir_path, file_name)
# 保存文件
with open(save_path, 'wb') as file:
file.write(file_res.content)
print(file_name, '保存完毕!')
time.sleep(0.5) # 挂起程序0.5秒,防止请求过快
if __name__ == '__main__':
# 创建总文件夹
total_dir = 'Stata_Model'
os.mkdir(total_dir)
# 下载Stata模块
download_model()














 1489
1489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









