







目录
一、前言
二、什么是数据合并
df.append() 实现数据追加
pd.concat () 实现数据拼接
pd.merge() 实现数据匹配
三、总结
----------------------------------------
📜本文共3901字,预计阅读时间10分钟,感谢阅读!
💡 本文所用数据为:
【工业互联网专题数据库存续企业省域分布统计数据(截至2020年03月)】
【工业互联网专题数据库各省市商标申请数据(截至2020年03月)】
【工业互联网专题数据库国税A级纳税人省域分布情况(截至2020年03月)】
💡 数据获取方式:关注公众号【数据seminar】,后台回复关键词“20220415”即可获取
Part 1 前言
上期文章中,我们介绍了如何使用 Pandas 根据已有的数据字段计算得到新的数据字段,根据上期所讲内容,我们可以使用多种方式生成新的数据字段,极大地丰富了数据的多样性。本期文章我们将继续讲解 Pandas,学习如何使用 Pandas 实现数据合并。对于拥有数据量大或者数据内容多且数据之间关联性强的数据使用者来说,这些方法将会非常实用。
本文中所有 Python 代码均在集成开发环境 Visual Studio Code (VScode) 中使用交互式开发环境 Jupyter Notebook 编写和运行。
Part 2 什么是数据合并
在我们使用数据时,各种各样的数据可能分散在不同的文件、数据库表格中;为了方便使用,我们需要将这些数据拼合在一起。一般有以下几种情况:
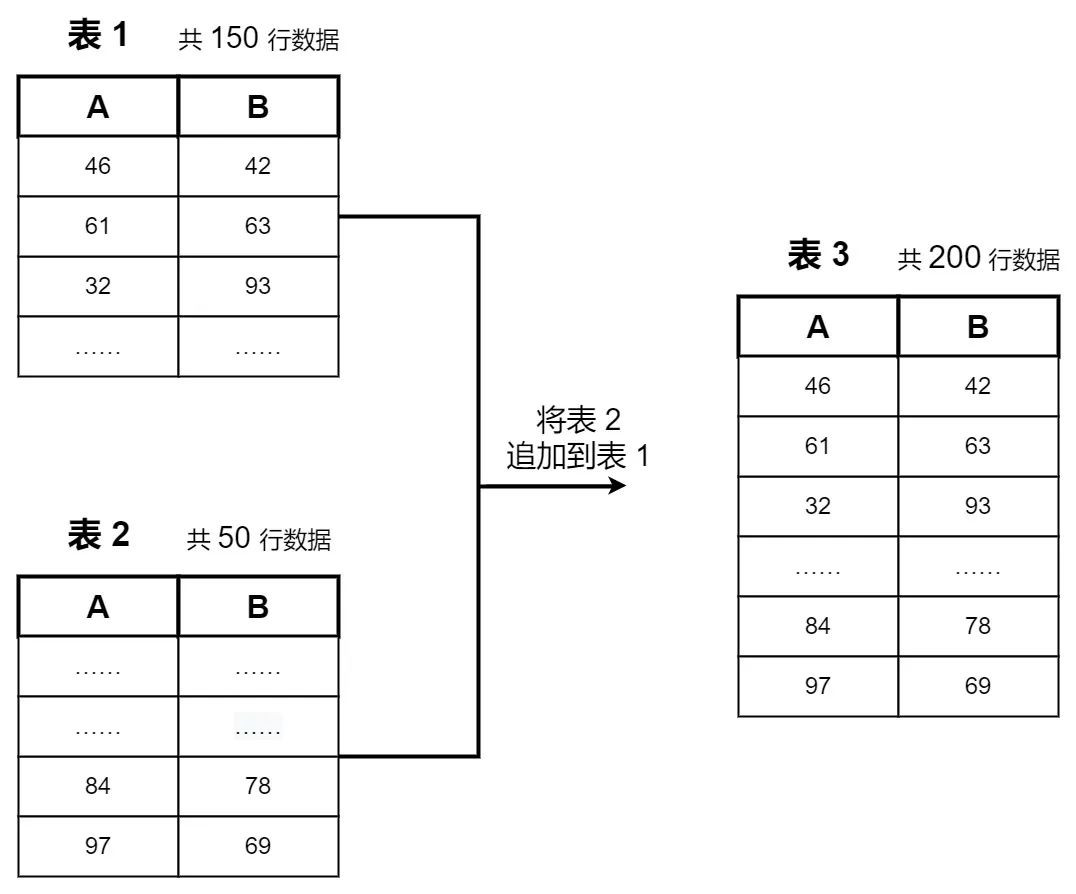
① 两份数据字段名,结构完全相同,需要将两张表纵向拼接在一起(一张表追加到另一张表中)。如下图所示。表1与表2纵向拼接形成表3:
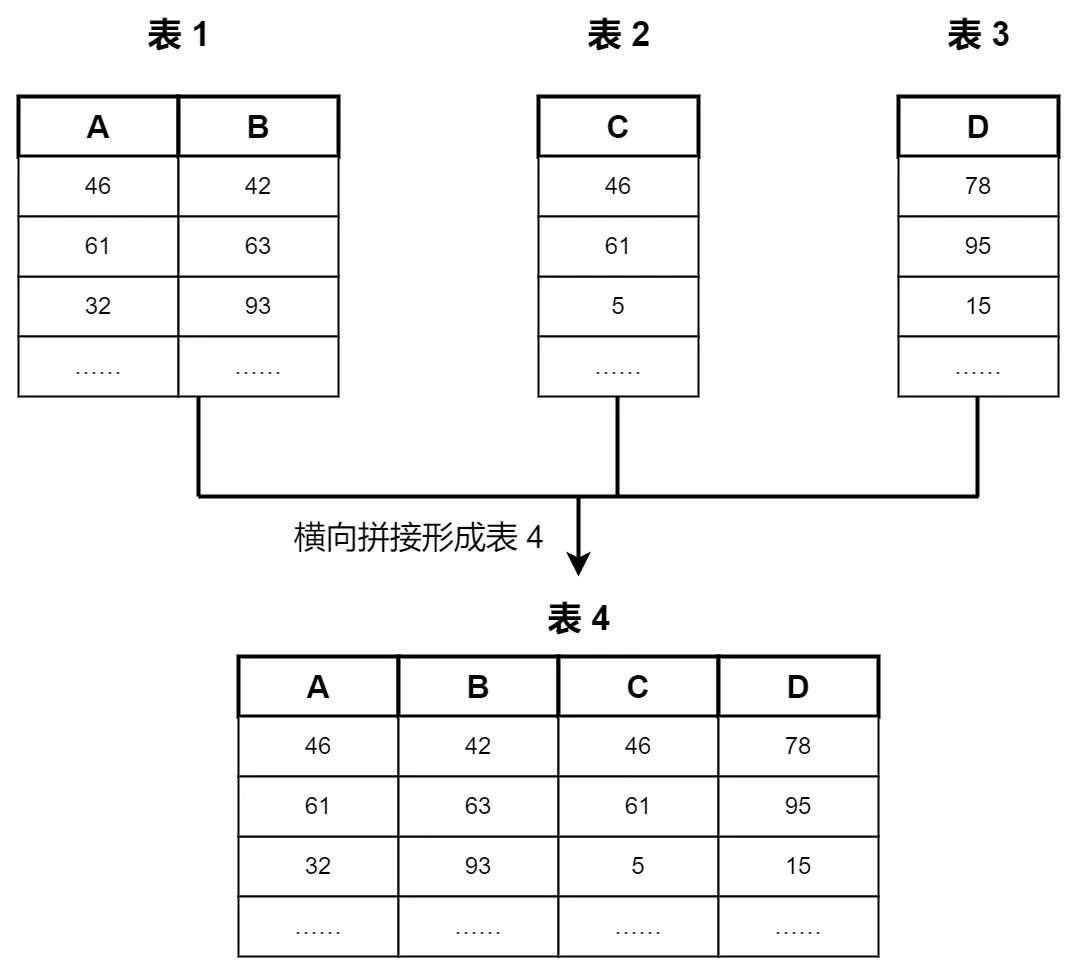
② 多张表中数据字段名有些不同,需要将这些数据表横向拼接在一起,形成一个多列数据表。如下图所示,三张表中的所有字段拼接在一起形成一个多字段的大表:
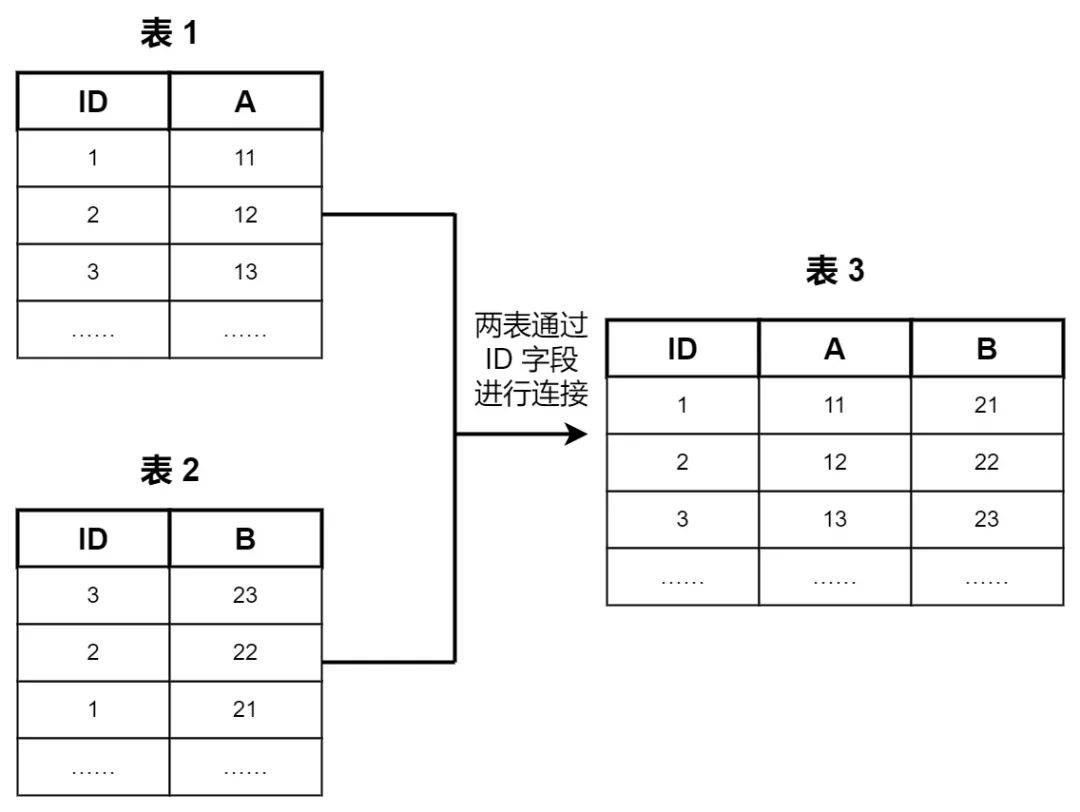
③ 两张表既有相同的字段又有不同的字段,需要像数据库表连接一样,使用共同的字段将两张表连接在一起。如下图所示,两张表使用 ID 字段连接在一起:
在 Pandas 中,以上三种操作都有对应的方法来完成,如下表所示:

下面我们举例一一说明。
1、df.append() 实现数据追加
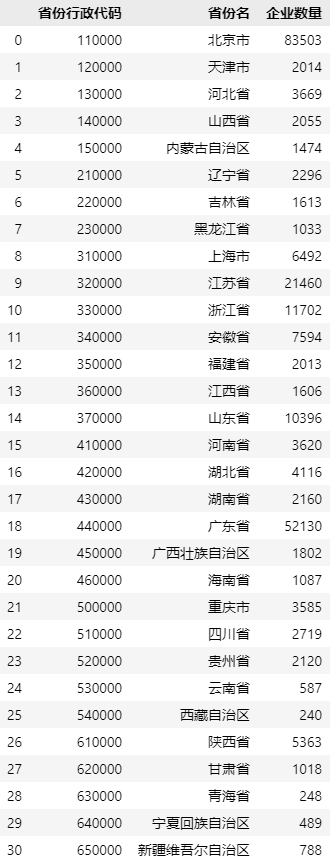
df.append()是 Pandas 中专门用于数据追加的方法,使用方法非常简单。我们使用本期赠送的数据来为大家演示如何进行数据追加。我们先将一份完整的数据被分为两份,来模拟一种需要数据合并的场景。读取数据【工业互联网专题数据库存续企业省域分布统计数据(截至2020年03月).xlsx】,并将这份数据一分为二,代码如下:
import pandas as pd
# 数据存储的路径
path_存续企业 = '工业互联网专题数据库存续企业省域分布统计数据(截至2020年03月).xlsx'
# 读取数据,该数据共 30 行
df_存续企业 = pd.read_excel(path_存续企业)
# 拆分数据,前 15 行为数据1
df_存续企业1 = df_存续企业.loc[:14,:]
# 拆分数据,后 15 行为数据2
df_存续企业2 = df_存续企业.loc[15:,:]
拆分后的两份数据如下图所示:
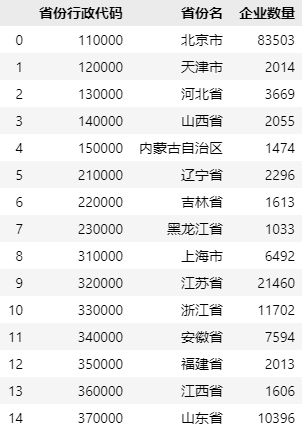
由于两份数据是从一份数据中拆分出来的,所示所有的字段名称完全一样。假设这两份数据原先是独立的,现在需要将两份数据合并在一起,并命名为【data_存续企业】,则操作代码如下:
# df.append() 方法会生成新的数据,所以需要将结果赋值给一个变量名
data_存续企业 = df_存续企业1.append(df_存续企业2)
# 输出查看合并后的数据
data_存续企业
2、pd.concat() 实现数据拼接
df.append()能够实现纵向数据追加,但是它的使用局限性太大,需要两个数据的所有字段完全相同才能达到理想的效果,且只能纵向操作,增加数据行数。如果想要将两份数据横向拼接,实现数据列的增加该如何操作呢?这时就需要用到 Pandas 中强大的数据拼接方法 pd.concat()。该方法可以实现数据横向拼接,还支持数据纵向拼接,而且一次性可以操作多个数据(两个或以上)。
下面我们将以下三张表横向拼接在一起(下图均是数据表的部分截图):
表1:【工业互联网专题数据库存续企业省域分布统计数据(截至2020年03月)】
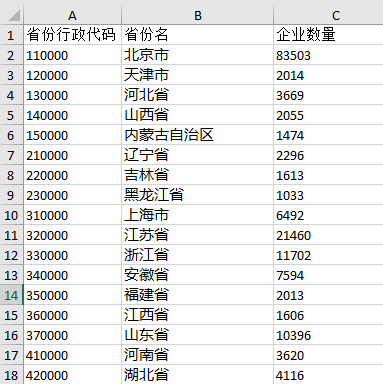
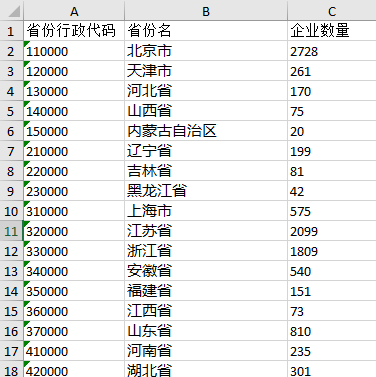
表2:【工业互联网专题数据库各省市商标申请数据(截至2020年03月)】

表3:【工业互联网专题数据库国税A级纳税人省域分布情况(截至2020年03月)】
使用 pd.concat()拼接以上三张表的代码如下:
# 三张表的存储路径
path_存续企业 = '工业互联网专题数据库存续企业省域分布统计数据(截至2020年03月).xlsx'
path_商标申请 = '工业互联网专题数据库各省市商标申请数据(截至2020年03月).xlsx'
path_A级纳税人 =至'工业互联网专题数据库国税A级纳税人省域分布情况(截至2020年03月).xlsx'
# 依此读取三张表
df_存续企业 = pd.read_excel(path_存续企业)
df_商标申请 = pd.read_excel(path_商标申请)
df_A级纳税人 = pd.read_excel(path_A级纳税人)
# 使用 pd.concat() 拼接三张表,横向拼接需要指定参数 axis=1
df_all = pd.concat([df_存续企业, df_商标申请,df_A级纳税人], axis=1)
df_all
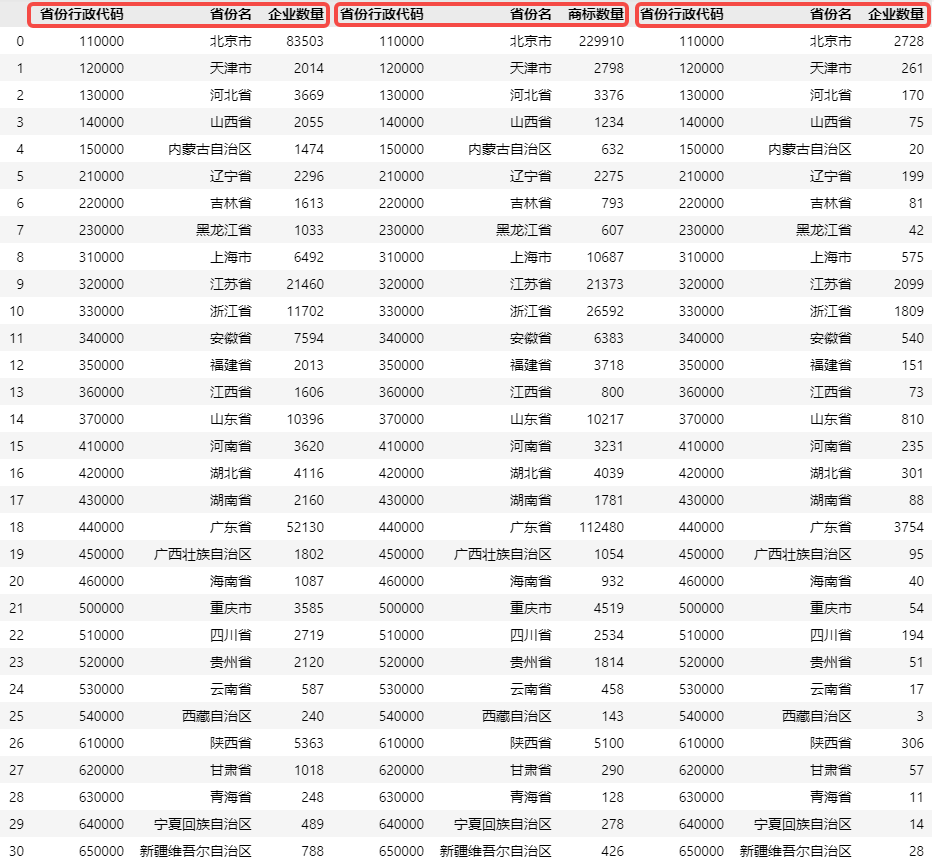
如上图所示,三张三个字段的表,拼接成为一张九个字段的表。
3、pd.merge() 实现数据匹配
前面的方法虽然可以将各个表的数据字段拼接在一起,但是九个字段中,存在两个重复字段省份行政代码和省份名,事实上9个字段中仅有5个字段是有效的。那么有什么办法可以直接根据表中字段的对应关系直接把两张表合并为一张表,又不会产生多余的字段呢?Pandas 提供了一个pd.merge()方法,它可以像数据库表连接一样匹配两张表,且性能比数据库更优。
我们将表【工业互联网专题数据库存续企业省域分布统计数据(截至2020年03月)】与表【工业互联网专题数据库各省市商标申请数据(截至2020年03月)】连接在一起。代码如下:
# left,right参数分别表示左,右两张表,on 表示实现连接的共同字段
# how 代表连接方式,how='left' 表示左连接,匹配后数据内容以左表为基准
df_merge = pd.merge(left=df_存续企业,
right=df_商标申请,
on=['省份行政代码', '省份名'],
how='left')
df_merge
匹配前的部分数据:

匹配后部分数据:

实际上,Pandas 中实现这种数据匹配的方法,还有另一个:df.join(),我们将在下期文章中详细为大家介绍如何使用 Python 做数据匹配,并与 Excel 和 MySQL 做对比。
Part 3 总结
本期文章介绍了数据合并的三种场景和对应的 Python 解决方法。数据合并最大的用处在于对一份数据做拆分-处理-合并的操作;另外在多文件合并方面,这些方法依然可以让人得心应手。

我们将在数据治理板块中推出一系列原创推文,帮助读者搭建一个完整的社科研究数据治理软硬件体系。该板块将涉及以下几个模块:
1. 计算机基础知识
2. 编程基础
(1) 数据治理 | 带你学Python之 环境搭建与基础数据类型介绍篇
(4) 数据治理 | 还在用Excel做数据分析呢?SQL它不香吗
(5) 数据治理 | 普通社科人如何学习SQL?一篇文章给您说明白
3. 数据采集
4. 数据存储
(1) 安装篇:数据治理 | 遇到海量数据stata卡死怎么办?这一数据处理利器要掌握
(2) 管理篇: 数据治理 | 多人协同处理数据担心不安全?学会这一招,轻松管理你的数据团队
(3) 数据导入:数据治理 | “把大象装进冰箱的第二步”:海量微观数据如何“塞进”数据库?
5. 数据清洗
(3) 数据治理 | 数据分析与清洗工具:Pandas数据选取与修改
(4) 数据治理 | 数据分析与清洗工具:用Pandas快速选出你的“心之所向”
(5) 数据治理 | 数据分析与清洗工具:Pandas缺失值与重复值处理
(6) 数据治理 | 数据分析与清洗工具:Pandas 数据类型转换(赠送本文同款数据!!)
(7)数据治理 | 数据分析与清洗工具:Pandas 创建新字段(赠送本文同款数据!)
(8)本期内容:数据治理 | 数据分析与清洗工具:Pandas 数据合并
6. 数据实验室搭建















 5731
5731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









