







 本文详细介绍了Python数据分析库Pandas,包括Pandas数据特征分析、Series类型、DataFrame类型、数据类型运算以及数据的累计统计分析。重点讨论了Series的创建、操作以及数据的相关分析,如协方差和Pearson相关系数。
本文详细介绍了Python数据分析库Pandas,包括Pandas数据特征分析、Series类型、DataFrame类型、数据类型运算以及数据的累计统计分析。重点讨论了Series的创建、操作以及数据的相关分析,如协方差和Pearson相关系数。
一、Pandas数据特征分析
Pandas库的引用:
Pandas是Python第三方库,提供高性能易用数据类型和分析工具。
import pandas as pd
Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用
Pandas库的理解
两个数据类型:Series, DataFrame基于上述数据类型的各类操作
基本操作、运算操作、特征类操作、关联类操作
二、series类型:
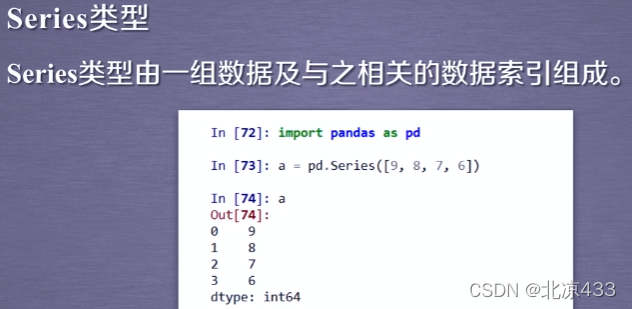
1、Series类型
Series类型可以由如下类型创建:
Python列表,index与列表元素个数一致。今标量值,index表达Series类型的尺寸。
Python字典,键值对中的“键”是索引,index从字典中进行选择操作。
ndarray,索引和数据都可以通过ndarray类型创建。其他函数,range(函数等。
2、Series类型的基本操作
Series类型包括index和values两部分。
Series类型的操作类似ndarray类型。
Series类型的操作类似Python字典类型
3、Series类型的基本操作
Series类型的操作类似ndarray类型索引方法相同,采用门。
NumPy中运算和操作可用于Series类型。可以通过自定义索引的列表进行切片。
可以通过自动索引进行切片,如果存在自定义索引,则—同被切片。
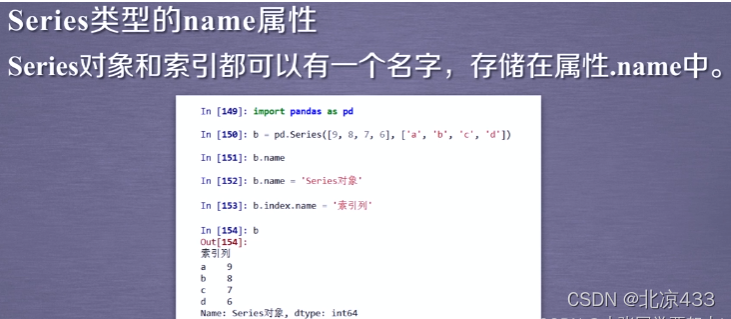
三、 DataFrame类型:


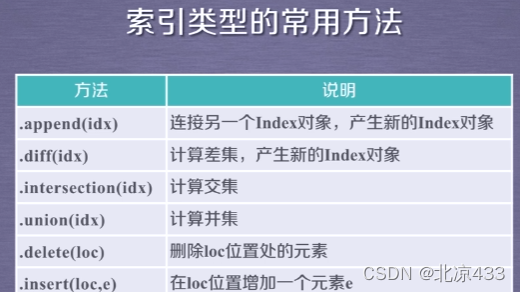
四、Pandas库的数据类型运算
算术运算法则
算术运算根据行列索引,补齐后运算,运算默认产生浮点数。
补齐时缺项填充NaN(空值)
二维和一维、一维和零维间为广播运算
采用+-*/符号进行的二元运算产生新的对象



不同维度,广播运算,默认在1轴

将一组数据通过摘要(有损地提取数据特征的过程)的方式,可以获得基本统计(含排序)、分布/累计统计、数据特征(相关性、周期性等)、数据挖掘(形成知识)。


- .sort_values()方法在指定轴上根据数值进行排序,默认升序
- Series.sort_values(axis=0, ascending=True)
DataFrame.sort_values(by, axis=0, ascending=True) # by:axis轴上的某个索引或索引列表
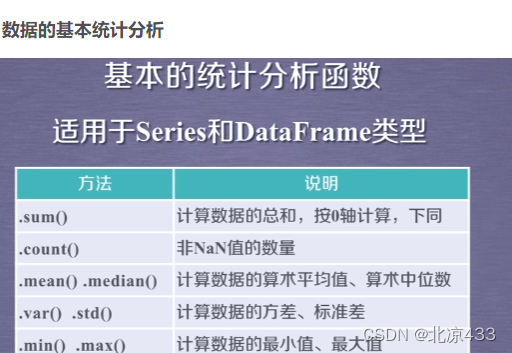
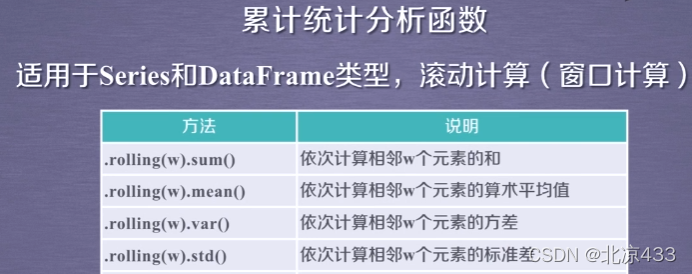
五、 数据的累计统计分析
数据的相关分析
两个事物,表示为X和Y,如何判断它们之间的存在相关性?
- X增大,Y增大,两个变量正相关
- X增大,Y减小,两个变量负相关
- X增大,Y无视,两个变量不相关
协方差:
- 协方差>0, X和Y正相关
- 协方差<0, X和Y负相关
- 协方差=0, X和Y独立无关
Pearson相关系数:
- 0.8 - 1.0 极强相关
- 0.6 - 0.8 强相关
- 0.4 - 0.6 中等程度相关
- 0.2 - 0.4 弱相关
- 0.0 - 0.2 极弱相关或无相关


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









