






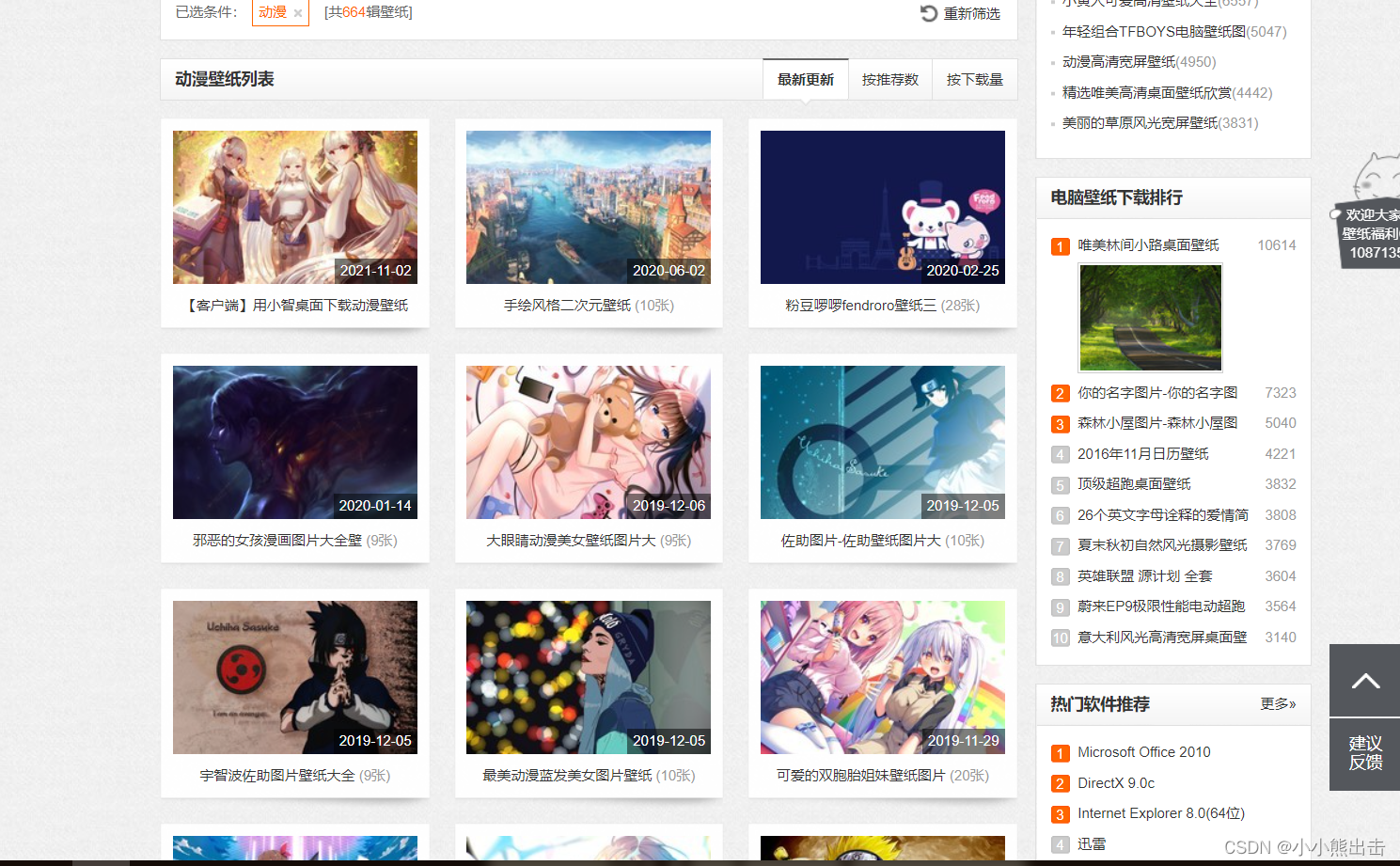
爬取这个页面的动漫壁纸
先创建一个爬虫项目
scrapy stratproject dongmanbizhi
scrapy getspider desk desk.zol.com.cn
在命令行写这个指令
会得到这个项目
desk.py 的代码
# coding=utf-8
import scrapy
from scrapy import Request
from dongmanbizhi.items import DMBZItem
class DeskSpider(scrapy.Spider):
name = 'desk'
allowed_domains = ['desk.zol.com.cn']
start_url = 'https://desk.zol.com.cn'
def start_requests(self):
for i in range(1, 11):
url = f'{self.start_url}/dongman/{i}.html'
yield Request(url=url, callback=self.parse_index)
def parse_index(self, response):
items = response.css(".photo-list-padding")
for item in items:
href = item.css(".pic::attr(href)").extract_first()
if len(href) > 50: # 判断长度 因为每一页第一个链接都是下载app的安装包 所以要去除
pass
else:
url = f'{self.start_url}{href}' # 合并链接
yield Request(url=url, callback=self.parse_deatil)
def parse_deatil(self, response):
item = DMBZItem()
item['img'] = response.css('#mouscroll img::attr(src)').extract_first()
item['name'] = response.css('#titleName::text').extract_first()
item['id'] = response.css('.photo-tit .current-num::text').extract_first()
yield item
next = response.css('.next::attr(href)').extract_first()
url = f'{self.start_url}{next}' # 获取下一页的图片
yield Request(url=url, callback=self.parse_deatil) # 因为需要点击下一页,所以需要请求下一个新链接
items.py 的代码
import scrapy
class DMBZItem(scrapy.Item):
# define the fields for your item here like:
img = scrapy.Field()
name = scrapy.Field()
id = scrapy.Field()
pipelines.py 的代码
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
from scrapy import Request
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
class ImagePipeline(ImagesPipeline):
def file_path(self, request, response=None, info=None, *, item=None):
name = request.meta['name']
id = request.meta['id']
file_name = f'{name}/{id}.jpg' # 构造存储路径
return file_name
def get_media_requests(self, item, info):
name = item['name']
img = item['img']
id = item['id']
yield Request(img, meta={ # 提取请求里面的名字 和id
"name": name,
"id": id
})
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
# result 里面存放着下载的结果
# 是就返回结果,否就返回报错信息
if not image_paths:
raise DropItem('Image Downloaded Failed')
return image_paths
settings.py 的代码
BOT_NAME = 'dongmanbizhi'
SPIDER_MODULES = ['dongmanbizhi.spiders']
NEWSPIDER_MODULE = 'dongmanbizhi.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
# 设置请求头
IMAGES_STORE = "D:/img" # 图片下载位置
ITEM_PIPELINES = {
"dongmanbizhi.pipelines.ImagePipeline": 300 # 调用这个下载的方法
}
# Obey robots.txt rules
ROBOTSTXT_OBEY = False # 不遵守机器人协议














 802
802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









