







爬取新片场的数据
一:
https://www.xinpianchang.com/channel/index/sort-like?from=navigator
视频id。、视频标题。、视频缩略图。、视频分类。、视频创建时间。、视频详情链接。
二:
视频详情:
视频id、视频预览图。、视频链接。、视频格式。、作品分类。、播放时长。、作品描述。、播放次数。、被点赞次数。
三:
作者详情:
作者id。、作者主页banner图片。、用户头像。、作者名字。、自我介绍。,被点赞次数。、粉丝数量。、关注数量。、所在位置、职业。
四:
评论数据:
评论id。、评论作品id(视频id)。、评论人id。、评论人名称。、发表时间。、评论内容。、被点赞次数。、
爬取上面的数据存储到mongodb数据库中
其中每个数据对应着一个表
解析这个页面,获取需求的数据,
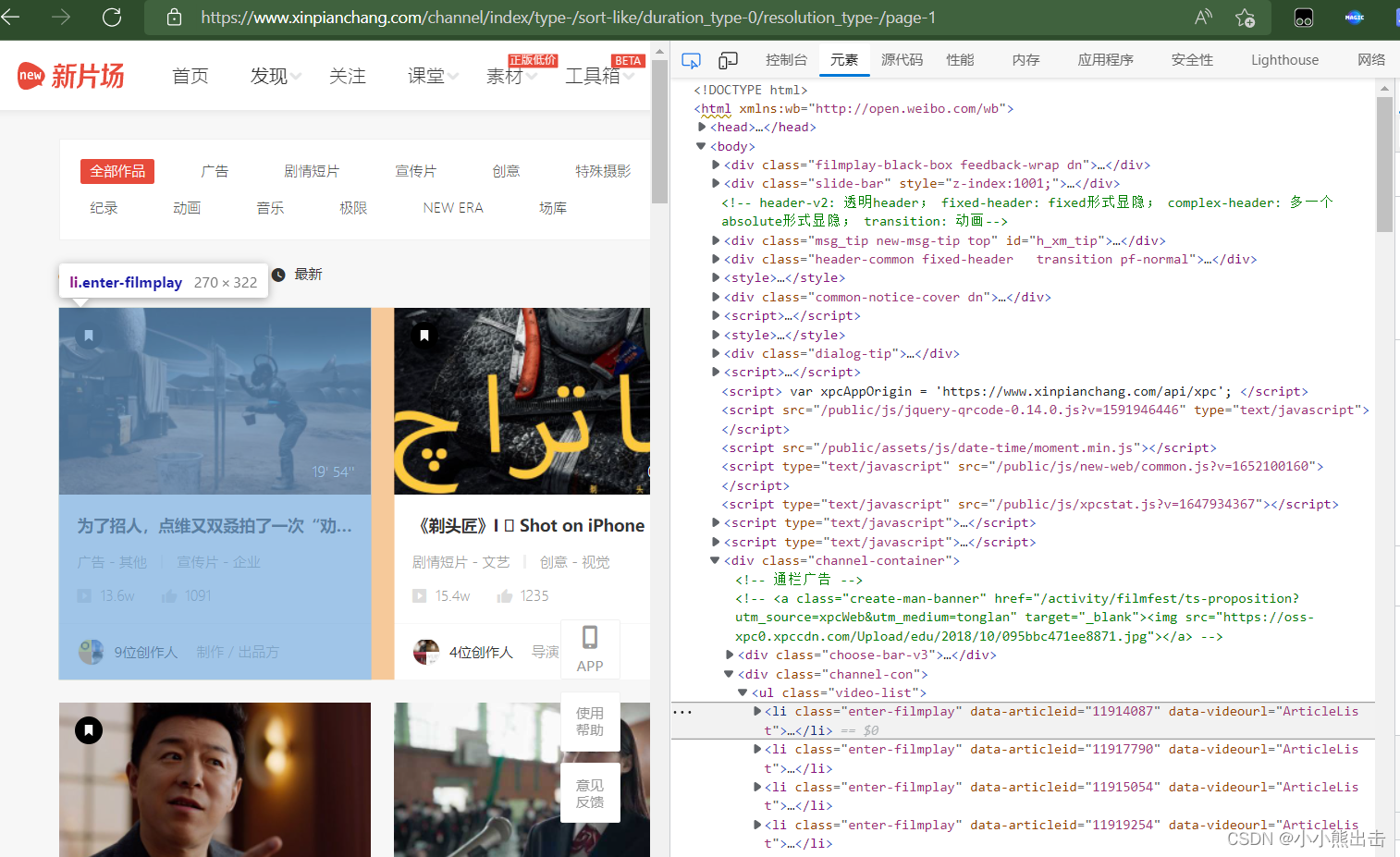
可以发现每一个li标签中
通过xpath可以定位到这里 /html/body/div[7]/div[2]/ul/li
import scrapy
from xinpianchang.items import * # 导入items里面所有的建模类
import re
import time
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='gb18030')
# 修改输出格式,有些情况下print无法输出特殊字符,需要修改输出格式,可以不设置
class NodeXinpianchangSpider(scrapy.Spider):
name = 'node_xinpianchang'
allowed_domains = ['xinpianchang.com']
start_urls = ['https://www.xinpianchang.com/channel/index/sort-like?from=navigator']
# 初始页面解析
def parse(self, response,**kwargs):
temps = response.xpath("/html/body/div[7]/div[2]/ul/li[1]")
# 因为数据太多先拿第一个视频数据经行解析
#初始页面可以提取如下的数据
for temp in temps:
# 视频标题
tag_name = temp.xpath("./div/div[1]/a/p/text()").extract_first()
# print(tag_name)
# 视频时长
tag_time= temp.xpath("./a/span/text()").extract_first()
# print(tag_time)
# 视频缩略图
name_picture = temp.css(".lazy-img::attr(_src)").extract_first()
# print(name_picture)
# 视频id
tag_id = temp.css(".enter-filmplay::attr(data-articleid)").extract_first()
# print(tag_id)
# 视频详情链接
tag_url = f"https://www.xinpianchang.com/a{
tag_id}?from=ArticleList"
# print(tag_url)
# 视频分类
tag_title = []
tag_titles = temp.xpath("./div/div[1]/div[1]/span/text()").extract()
for tag in tag_titles:
tag_title.append(tag.strip())
# print(tag_title)
# 播放量
tag_play = temp.xpath("./div/div[1]/div[2]/span[1]/text()").extract_first()
# 点赞量
tag_give = temp.xpath("./div/div[1]/div[2]/span[2]/text()").extract_first()
# 请求详情链接、使用callback回调、用meta将数据传出去
yield scrapy.Request(
url=tag_url,
callback=self.parse_detail,
meta={
"tag_id":tag_id,
"tag_title":tag_title,
"tag_play":tag_play,
"tag_give":tag_give,
"tag_time":tag_time,
"tag_name":tag_name,
"name_picture":name_picture,
"tag_url":tag_url,
}
)
在items里面经行建模将数据放到建模中
将所有所需要的数据经行建模
写在items.py里面
# coding=utf-8
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class Xinpianchang01Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
mongodb_collection = "The_initial_video"
# """
# 视频id。、视频标题。、视频缩略图。、视频分类。、视频创建时间。、视频详情链接。
# """
video_name = scrapy.Field() # 视频标题
video_picture = scrapy.Field() # 视频缩略图
video_id = scrapy.Field() # 视频id
video_url = scrapy.Field() # 视频详情链接
video_title = scrapy.Field() # 视频分类
setup_time = scrapy.Field() # 视频创建时间
class VideoItem(scrapy.Item):
# """
# 视频id、视频预览图。、视频链接。、视频格式。、作品分类。、播放时长。、作品描述。、播放次数。、被点赞次数
# """
# # 视频详情
mongodb_collection = "video_data"
video_time = scrapy.Field() # 视频时长
video_play = scrapy.Field() # 播放量
video_give = scrapy.Field() # 点赞量
# 视频id
video_id = scrapy.Field()
# 作品分类
video_title = scrapy.Field()
# 视频预览图
video_img = scrapy.Field()
# 作品描述
CDWA = scrapy.Field()
# 视频链接
video_url = scrapy.Field()
# 视频格式
format = scrapy.Field()
class AuthorItem(scrapy.Item):
# """
# 作者id。、作者主页banner图片。、用户头像。、作者名字。、自我介绍。,被点赞次数。、粉丝数量。、关注数量。、所在位置、职业。
# """
# 作者详情
mongodb_collection = "Author"
# 作者id
author_id = scrapy.Field()
# 作者名称
author_name = scrapy.Field()
# 作者头像
author_head = scrapy.Field()
# 作者主页banner图片
banner = scrapy.Field()
# 自我介绍
introduce = scrapy.Field()
# 被点赞次数
by_gives  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 936
936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









