






一项目概述:
“疫情下的社会心理学”这一课题旨在通过疫情期间大众在自媒体上的新闻评论等信息,凭借一些方法分析出总体的心理变化和情绪走向,并在宏观上把握了总体的心态格局。
对于该课题,我们小组首先爬取了哔哩哔哩和微博的大量数据,并且统计、分析不同月份的高频词汇,从而初步筛选数据。在此基础上,通过新闻的点赞、评论、转发数进行高斯拟合,取正态分布曲线的上分位点,筛选出核心新闻,并且将核心新闻的评论按照热门程度进行获取。与此同时,我们从疫情语境下的评论数据中获得了大量情绪样本进行标签化处理,建立心态辞典、训练合适模型,并且通过了大部分随机化样本的验证。我们把核心新闻的评论按照月份进行情绪分析,获取每种情绪在每个月的占比,并且将微博与哔哩哔哩相对比。
除了主要成果以外,我们小组还在研究过程中得到了一些副产物。首先,我们成功通过关键词算法得到了每日微博关键词,用来代表某一天新闻的特征。其次,由于拥有大量的微博数据,我们还进行了每个月微博数据分析。
二、项目实现过程
2.1 数据爬取与筛选
BiliBili
首先我们选择了哔哩哔哩的一些官方媒体,譬如央视新闻、观察者网等等,
选取2019年12月至2020年6月所有关于疫情的新闻标题进行获取,并且通过月份整合成文库,为后文筛选微博数据做好铺垫。由于此举将对之后的微博筛选有较大影响,故此处人工干预较多,主要用于选取标题。
除此以外,人工选取了113条精华新闻,爬取其全部评论。在爬取过程中,
我们发现由于哔哩哔哩提供的评论开源网站有一定局限,网页内重复评论现象严重,于是我们决定对长度超过5的评论进行hash去重。
除此以外,我们还去除了所有的回复评论,这些建立在别人评论之上的评论我们认为是无效的。除此以外,我们还简单过滤了一些对我们研究疫情社会学毫无意义的评论,譬如“A”、“前排”等等。因此最终我们在b站获取的评论总量为八万余条。
我们将哔哩哔哩大量的新闻标题,以不同月份为标准分类整理成文库。对于海量的微博数据,我们必须借助哔哩哔哩的数据信息来对微博的数据进行层层筛选。
为了信息的有效处理,我们将每一个月的所有新闻标题纳入该月的新闻标题文库。对于文库中的每一句话,使用HanLP工具进行停词,对于每一个词,在文库中查找出现的次数。由于停词机制的不完善,我们在程序运行完之后又简单进行了一些合并与归类。如此一来,我们便可以获得2019年12月至2020年6月每一个月的高频词汇,并且能用可视化的形式呈现出来。
以下是我们的每月高频词可视化结果:
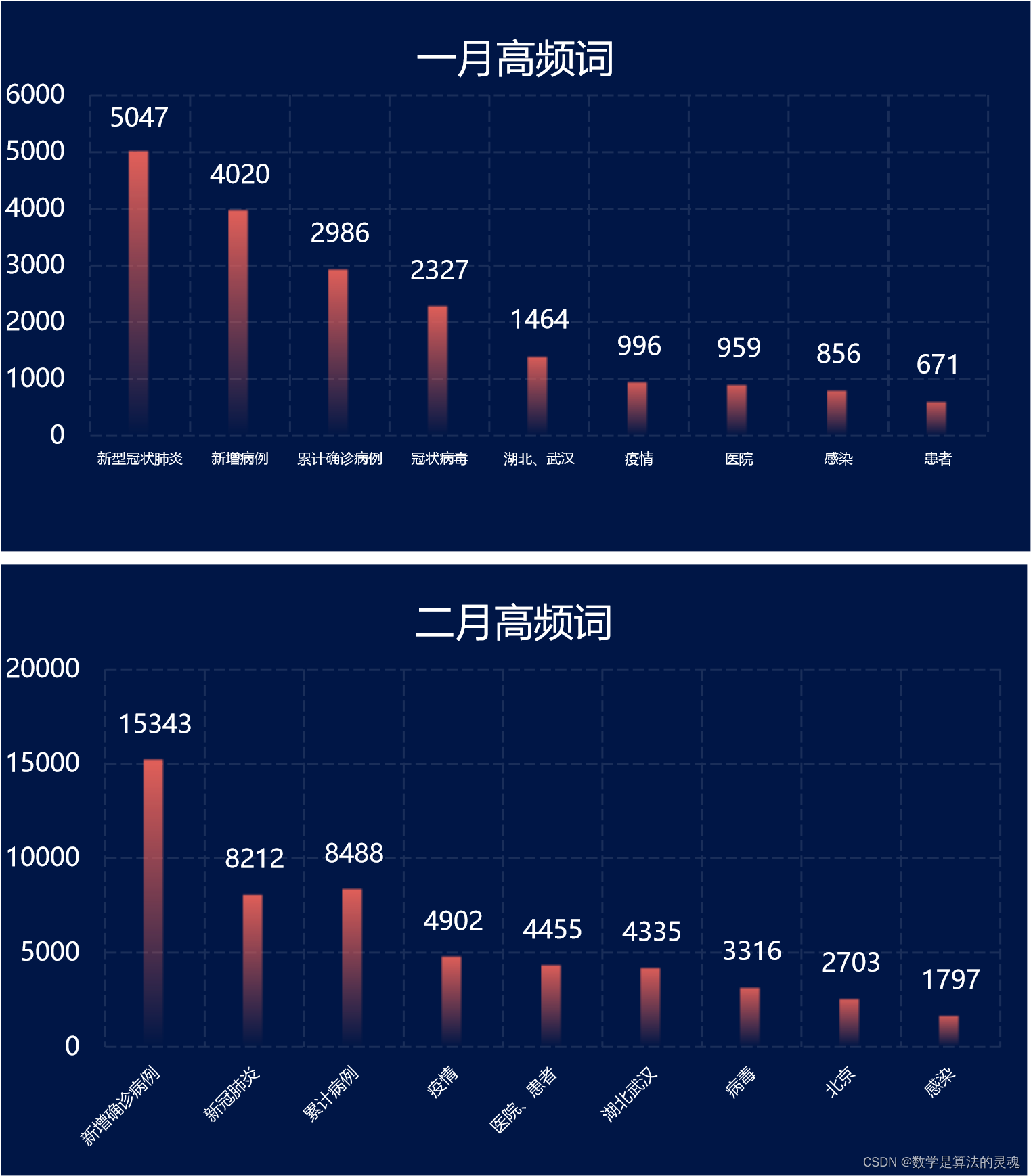
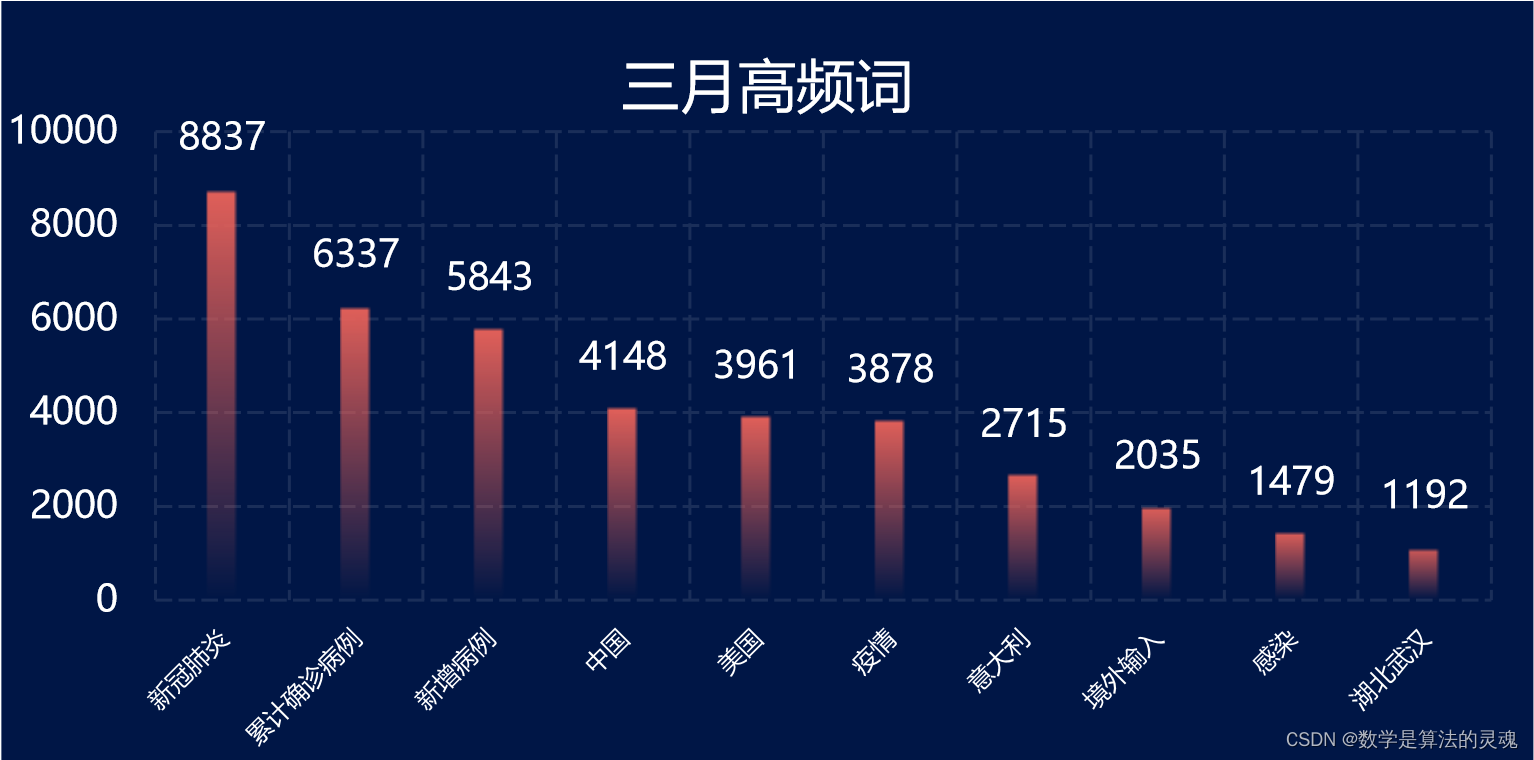
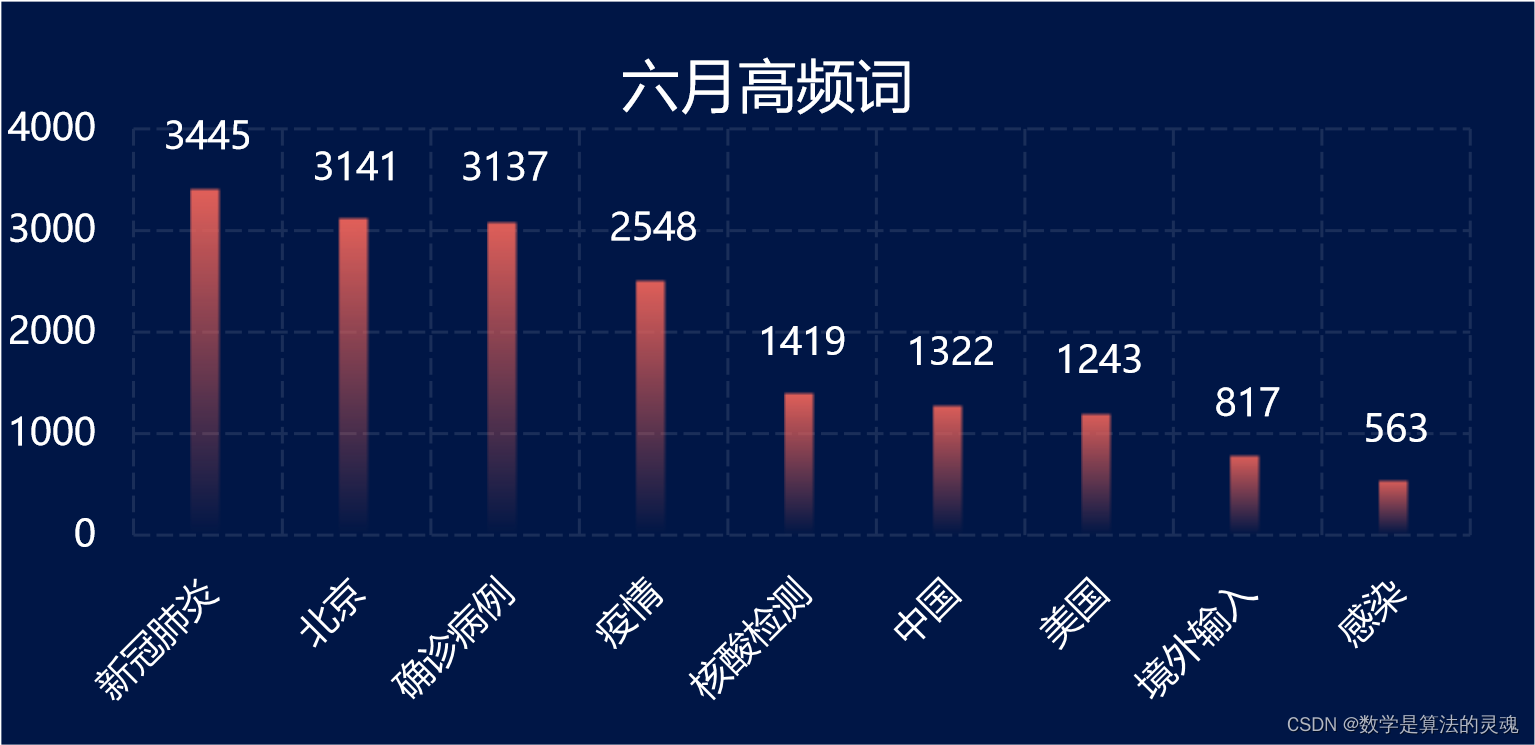
有了这些每月高频词,筛选微博数据就轻松了许多。
2.2 微博
由于微博的每日产生的数据量巨大,在未得到微博官方授权获取数据的情况下,我们难以获得并有效存储疫情期间的全部微博数据,同时考虑到来自不同媒体账号的数据,或者说,关注不同新闻媒体的人群,对于同一件新闻的看法具有较大的差异性,倘若只选择一家媒体的微博数据,极容易被一家之言蒙蔽,对调查结果的科学性造成较大的影响。最终我们依据媒体的热度,用户的活跃度,用户人群的差异以及媒体的权威性,选择了九家新闻媒体(观察者网,共青团中央,澎湃新闻,央视新闻,紫光阁,人民日报,凤凰网,中国新闻周刊,新京报),并决定获取这九家新闻媒体,从2019年12月至2020年6月间的全部与疫情相关的微博数据。
根据上述爬取的B站数据中的高频词汇进行分析,得到了像“疫情”,“新型冠状病毒”,“新冠”等一级高频词汇,以及如“肺炎”,“战疫”,“抗疫”,“新增”,“确诊”等次级高频词汇,依据这样的高频词汇,我们能够在爬取微博数据时,依据这些高频词汇在微博的标题/内容中出现的频数,来有效地初步筛选出与疫情相关的微博。
如“[#这是我们的春节#]【[#回乡见闻#]故乡里的中国|‘高龄大孩’的二胎家庭】我的同学小曾今年26岁,有个3岁的妹妹。”和疫情相关的高频词汇在这样的微博中出现的词频过少,或者说为0,那么它显然不是我们所需要的微博。
又如:“【#2月1日起购买火车票须提供乘车人手机号#】今天(1月31日)下午,记者从中国国家铁路集团有限公司获悉,2月1日起购买火车票须提供乘车人手机号码。根据有关部门要求,为加强新型冠状病毒感染的肺炎疫情防控工作,便于在需要时及时联系乘车旅客,自2月1日起,购票人须提供每一名乘车旅客本人使用的... ”这样的微博,其中多次出现与和疫情相关的高频词汇,如:“新型冠状病毒”,“肺炎”,“疫情”,那么我们认为这是我们需要的微博,并将之抓取。
在实际操作中,很容易发现,在12月及一月初时,因为新冠尚未全面爆发,各大媒体关于疫情的关注度较低,对于新冠的认知,也仅仅停留在“新的传染病”,“和SARS有相似之处”,相关的报道多着笔在“武汉发现不明原因肺炎”,“华南海鲜市场”,“蝙蝠”上。因而对于这一时段的微博新闻,采用之前所说的高频词汇是不合适的,容易错漏有价值的微博信息。所以我们针对这一时段的微博数据,采取了额外的高频词汇条件。除此之外,对于3月后,国内疫情相对缓和的情况,微博新闻的播报多着眼于国内“无增长”,“治愈”, “复工”,全球各国“新增”,这也为我们针对3月之后的微博新闻抓取提供了额外的高频词汇。
最终我们得到了自2019年12月1日至2020年6月31日,九家媒体,合计23040条微博。
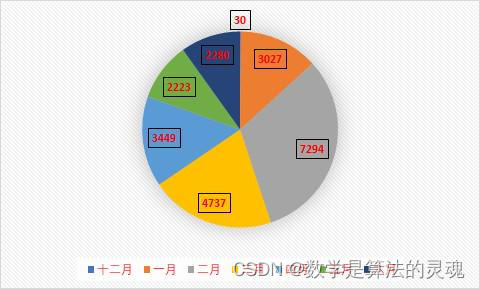
每月所有媒体疫情相关微博数合计
我们统计了每条微博的点赞数,评论数以及转发数,为后续的筛选做准备。同时,我们也依据微博下方评论的热门程度,依次抓取了前200余条热门评论或全部评论。
对于评论进行初步分析时,我们发现四点:
微博的用户,习惯于发送“@用户名:内容”这样格式的评论,这样的评论中无意义的“@用户名”部分会对后续的情绪分析造成影响,于是我们删除了这样的评论中无意义的部分;
微博的用户存在,“反复刷同样的评论”这样的情况,我们基于用户的UID,进行了筛选,对于同一用户只保留一条最热门评论;
"在疫情相关的评论下发放其他话题(#其他话题#)的信息也会存在,如 3月初引发热议的#外国人永久居留权#的话题,这是不好处理的,我们也只能将评论区出现的话题输出,加以人工筛选,对部分话题针对性地予以删除;
由于微博转发机制的设计,微博用户在转发微博时,可能会同时评论“转发微博”,对于这样的评论,我们也予以删除。
如此,我们最终得到了1773990条有效的评论数据(全部放在comment.zip中)。注:其中不包括澎湃新闻以及中国新闻周刊的评论数据,此外,央视新闻仅公开部分日期的微博数据,因此并不完整。
这些数据仍然不能直接使用于情绪预测,考虑到微博的热门程度不同,冷门微博下方的评论较少,依赖于热度的筛选效果较差,评论质量也会因此下降,因此,决定对微博热门程度进行筛选排序,得出核心微博,然后从核心微博下获取到核心评论。
每条微博一共有三个维度“点赞,评论,转发”对这条微博的热度进行一个评价,显然这三个数值越高,就说明了这个微博的热度越高,如果这三个因素线性关联较弱的话,我们可能会考虑使用pca对之进行一个降维,再对降维得到的数据进行一个分析,不过易观察得到,对于同一个媒体,其发送的微博,评论数,点赞数,分享数往往是线性相关的,这说明我们可以通过一个线性关系,来将之互相表示出来,因此我们可以认为,微博的热度是一维的。
注:下图点较散,是对数值做round取整的结果。
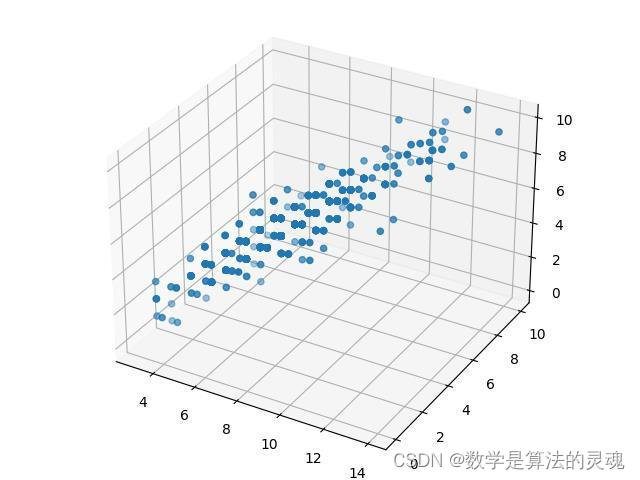
央视新闻 点赞,评论,转发三维散点图
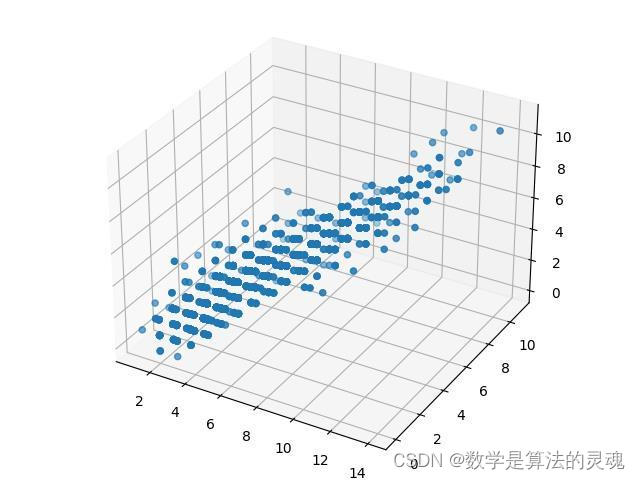
中国新闻周刊 三维散点图
我们观察到“微博热度”是近似于正态分布的,于是使用“微博热度”作为参数对每个媒体做高斯拟合:
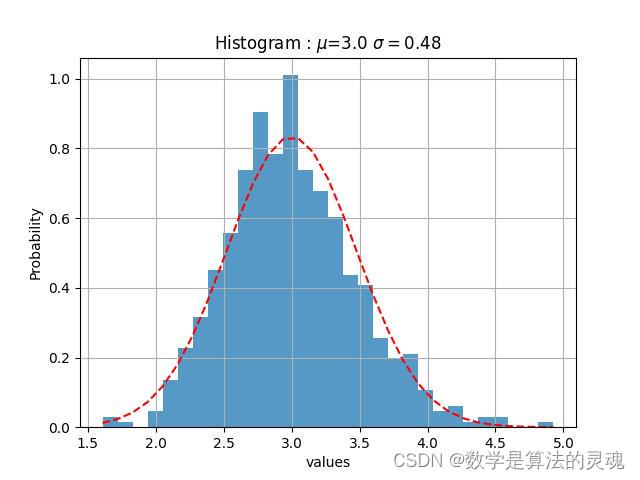
观察者网微博热度高斯拟合
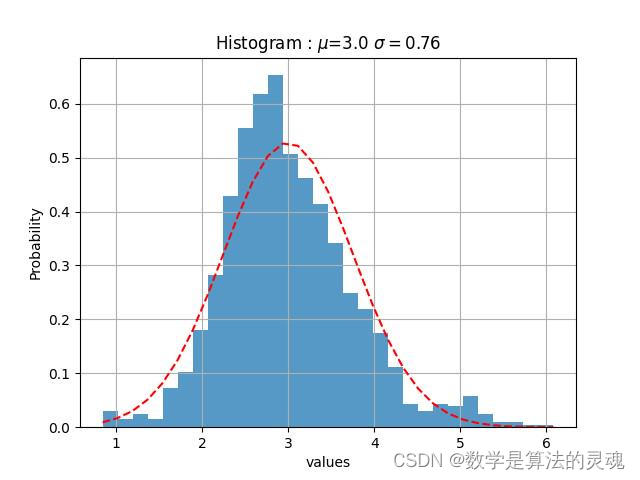
凤凰网微博热度高斯拟合
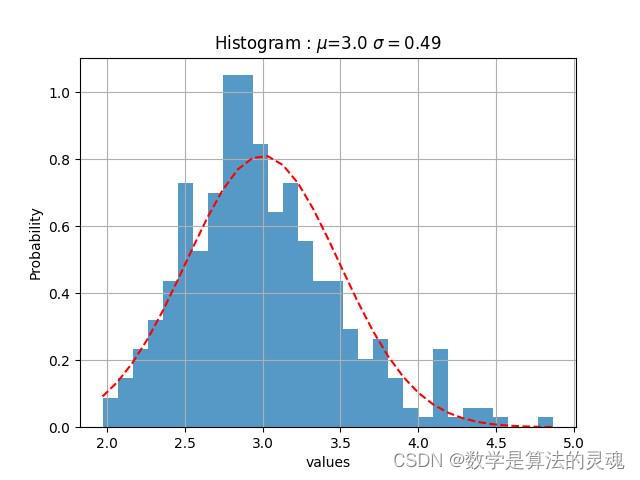
央视新闻微博热度高斯拟合
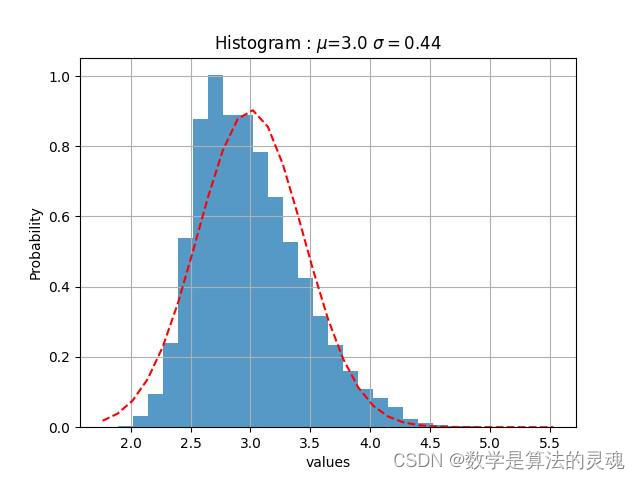
人民日报每日热度高斯拟合
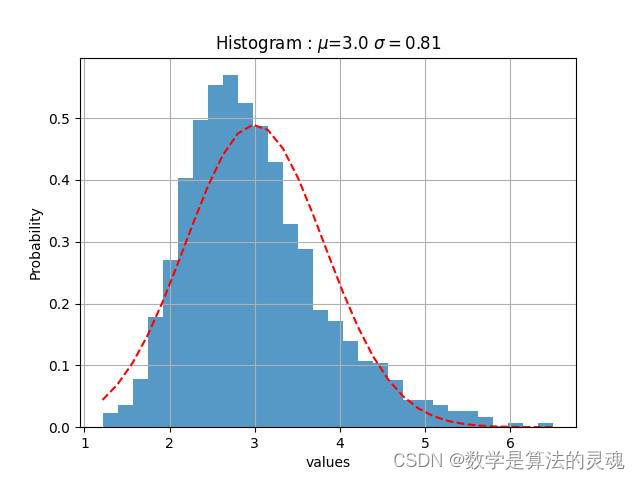
新京报每日热度高斯拟合
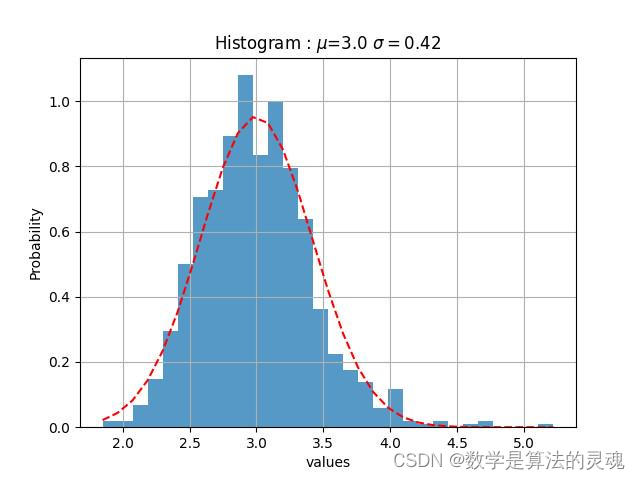
紫光阁每日热度高斯拟合
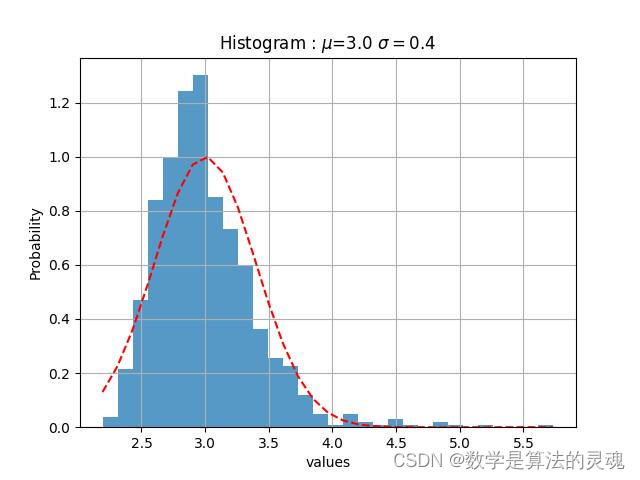
共青团中央高斯拟合
我们认为,一个微博的热度越高,那么它越关键,依据得到的高斯拟合的期望,方差,我们取每家媒体的上0.1分位点,即取全部数据的上百分之十,作为核心微博,再通过这些微博得到评论数据,最终筛选出217308条核心评论,217308/1773990=12.24%接近于10%,基本达到了筛选目的。
2.3 训练模型
情绪分析的基本思路是训练模型并使用模型对提供的每条评论进行情绪预测。模型的存在可以为每次预测提供依据并且免去了一次次查找文件的复杂过程。训练模型是一个机器学习的过程,在这里我们借助了HanLP作为此次作业的工具。
训练模型可以分为创建心态词典、以词典为基础进行训练两步。其中词典的建立是一个手动打标签的过程,即对一部分样本进行人工情感分析并依据结果进行分类。由于 HanLP 并没有提供类似的词典,我们首先在百度网盘、CSDN 等平台寻找心态词典。但这些途径获得的词典并不尽如人意,原因有三:1,历史过于悠久。在互联网这么一个日新月异的平台,十年前的用语与当今有天壤之别,不能很好的对情绪进行预测;2,对文本的划分过于粗糙。翻看某个情绪下的文件,经常可以看到没有任何相关性甚至完全相反的文本被归到其中;3,针对性低。词典所提供的情感往往与此次作业所需要的没有很多交集。因此我们决定自己制作词典,首先讲情绪划分为乐观镇定、鼓励感激、担忧疑问、愤怒以及骄傲五类。首先我们获得比较好爬取的B站数据,并对这一部分数据有选择的进行打标签。对于某些文本较少的数据我们又选取之后获得的微博数据进行补充。最终获得了一份对此次疫情针对性强、分类更加准确的心态词典。
对模型的训练是通过HanLP提供的方法完成的。其实现的基本思路是通过分词功能把心态词典中的文本提取词语,并通过卡方检测去掉词语中低于一个阈值的,剩下的是有助于分类决策的关键词语。再通过朴素贝叶斯法训练出一个模型,并保存在指定的路径中,此后每次使用模型可以直接调用保存下来的模型文件,但如果对词典有所改动就需要先删除模型文件并再次训练。
至此,我们获得了本次作业所需要的情感分析模型。
2.4 分析数据
对评论的情感预测根据疫情阶段划分,即不重视与无奈传播阶段(2019.12.8-2020.1.22)、资源缺乏阶段(2020.1.23-2020.2.9)、严格统一管 控 和 物 资 配 给 阶 段 ( 2020.2.10-2020.3.9 ) 和 有 序 复 工 阶 段(2020.3.10-2020.6.30)。
情绪分析的样本是筛选后的新闻热度前两百的所有评论共21.7万条。对样本进行上述阶段划分后进行情绪预测,并获得每个阶段各个情绪的数量。对获得的数据进行阶段内的比较,得到该阶段占主导的情绪,然后再对数据进行阶段间的比较,获得人们在本次疫情中情感的变化。此外我们还对最开始获得的B站评论进行了分析,与微博分析结果进行对比对不同平台间情感是否有区别进行探究。
具体情况已详细写明在下文的研究成果中。
三、项目最终成果
3.1 情绪分析第一阶段:
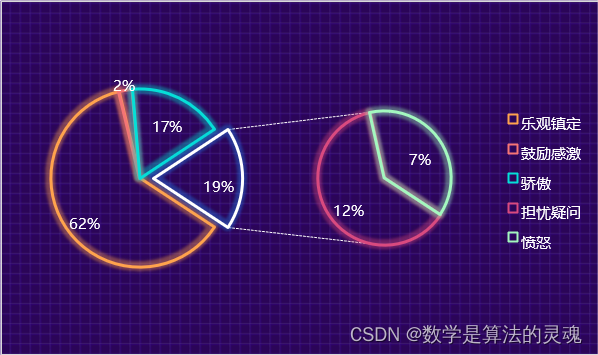
首先我们可以直观的看到,乐观镇定占了大多数。在第一阶段人们对疫情并没有给予足够的重视,并不认为新冠肺炎会发展成一次蔓延到全球的灾难,因此大多数人持有乐观镇定或是说并不把此次疫情当作很严重的事件的心态,在这么一种心态下就更别说对他人持有鼓励或是感激的心情了。其次,正直年末互联网上会有很多总结国家一年以来成就的视频、文章,因此网民爱国情绪大涨,在一些新闻评论下刷些自我骄傲的话语也是可以理解的。所以第一阶段群众对疫情的主要情绪是偏向于无所谓的乐观。
3.2 第二阶段:
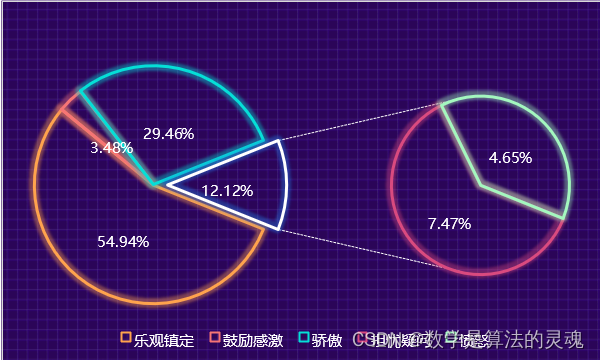
在第二阶段中,我们可以很清楚的看到骄傲的情绪有所增加。第一阶段末终南山院士宣布挂帅出征,终南山作为非典时期的最大功臣,他在第二阶段发布的一些内容,不管是积极还是消极,正如我身边长辈所说的那样,终南山的出现本身就能给人一种安心的感觉。因此乐观的情绪依然占大多数,并且在此阶段国家进行的一系列紧急措施更是让人们更加的信任祖国。
3.3 第三阶段:
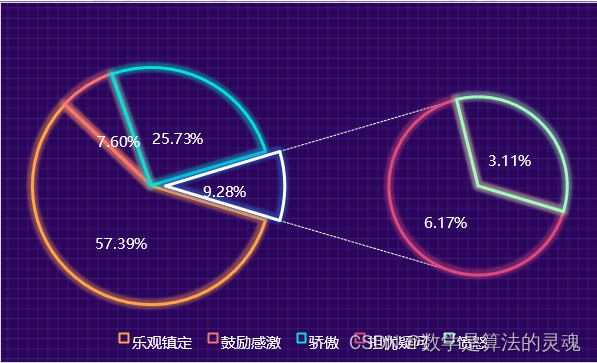
第三阶段鼓励感激增长了两倍多,这与疫情发展息息相关。检测水平提高、
无症状患者的流动等因素将疫情推向高潮。此时各省驰援武汉的医护人员也基本到位,同时医护人员牺牲的消息也接踵而至。因此人们对远方的亲人、奋斗在一线的工作者怀有鼓励感激的情感越来越多。
3.4 第四阶段:
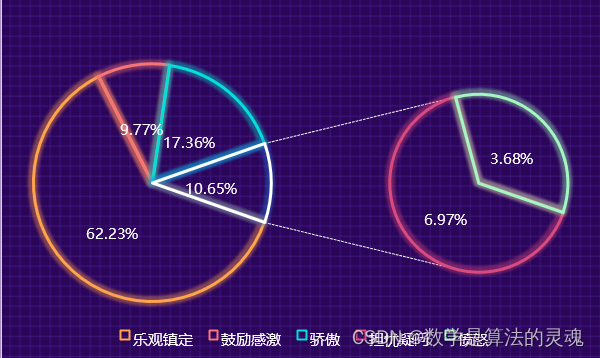
第四阶段我国疫情趋于平稳,国外疫情迎来高潮。但是两相对比下骄傲的情绪反而降低,有了增长的是乐观与鼓励感激。对此我们认为,此次疫情中暴露在群众事业中的医护人员、警察等社区工作者让群众意识到平日里保护他们的一直都是这些平凡而伟大的人。因此对国家这一抽象整体的骄傲转化为更加实体化的人身上,因此内心更加安定。所以乐观与感激的情绪有所增加。
3.5 B站数据:
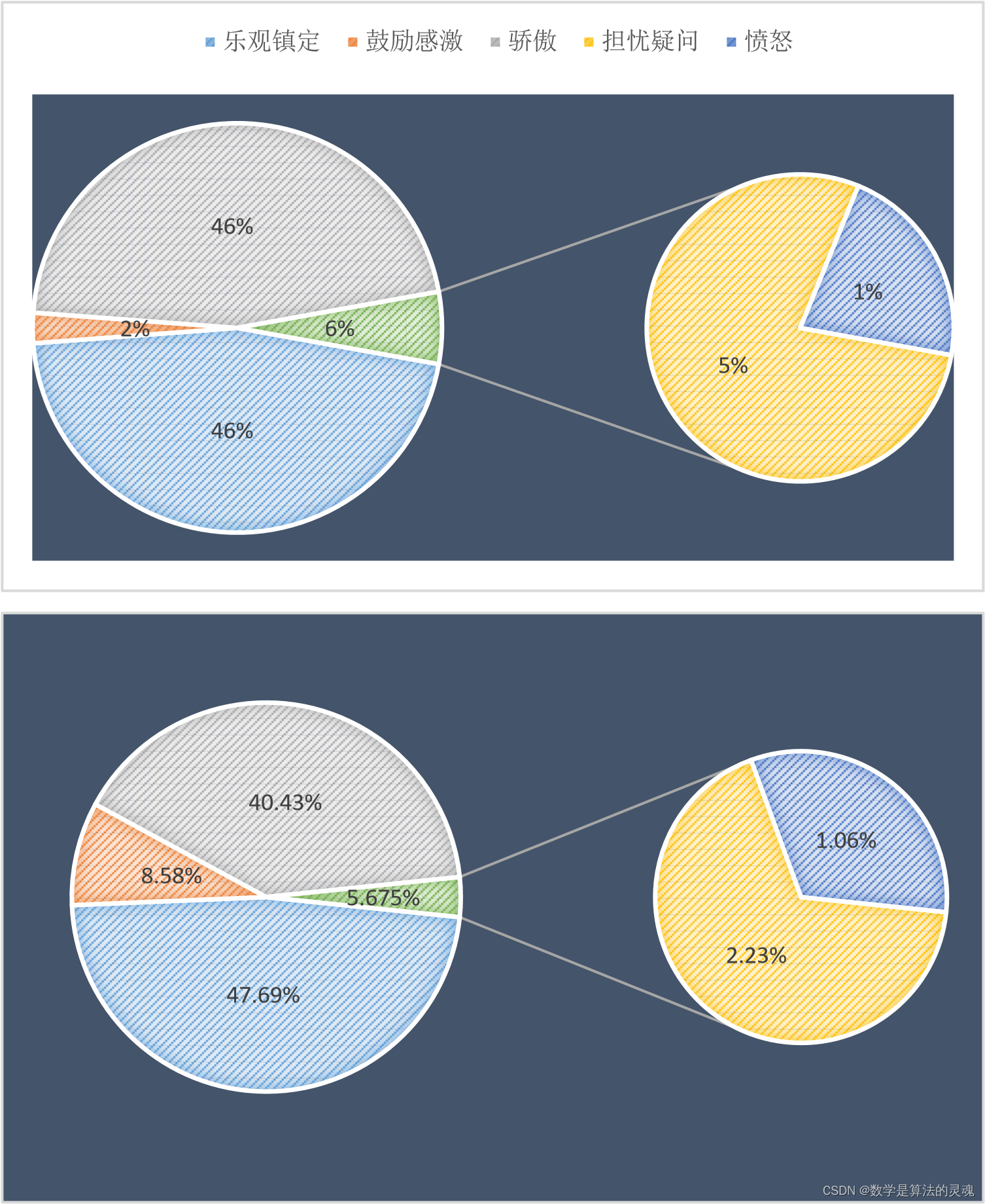
以上分别为B站评论关于第二、第三阶段的情感比例。我们可以看到鼓励感激的变化与微博类似,但骄傲所占比明显增多。B站是一个视频网站,视频的形式对于爱国主义教育更加有益,而且B站评论或是弹幕存在刷屏的现象,因此某一情绪可能会有着异常的增加。此外可以看到B站评论中,负面情绪的占比明显的比微博少很多,我们认为这是因为B站有着更好的审核机制,一些负面的视频被抹杀在了摇篮中;并且B站的用户年龄普遍比微博低,更少的沾染了社会中的戾气。
3.6 小结:
纵观此次疫情,我们发现代表负面情绪的担忧与愤怒占比并没有我们想象中那么高,甚至可以说很低并且随着时间发展总体上还是下降的趋势。因为负面情绪的特征词较为明显,因此我们认为对真实情况的反应是准确的。对此我们有以下解释:1,全面建设小康以来,人们物质水平普遍提高的同时,对精神文明的追求自发的提高了,更加注重自身在公共场合的形象,不管是虚拟还是现实;2,我们数据最大来源人民日报为了稳定群众情绪,对报道的侧重点有所倾斜,一些容易引发民愤的事件报道较少(从最近一些影响力较大的事件人民日报从未报道也可得知)。此外我们可以看到,乐观的情绪在整个疫情中虽然有所增减,但始终占据着主导地位。并且疫情的第一与最后一阶段情绪比例较为相似,乐观与骄傲的情绪基本一致,但很多的负面情绪转变为了鼓励感激,这意味着一次疫情让社会中的戾气减少,人与人之间更加和善,当真是疫情无情人有情!
3.7 每月微博分析
对每个月,全部媒体的微博数据进行分析,我们得出了如下的8张图表,这也有助于我们认识疫情发展的不同阶段人们的态度。
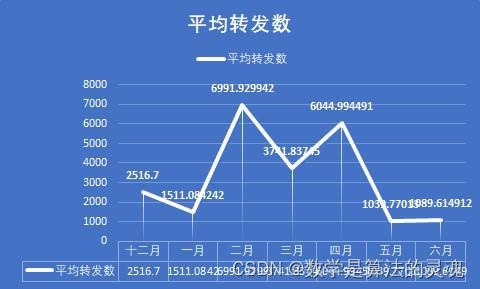
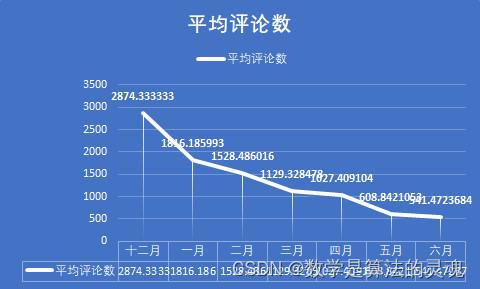
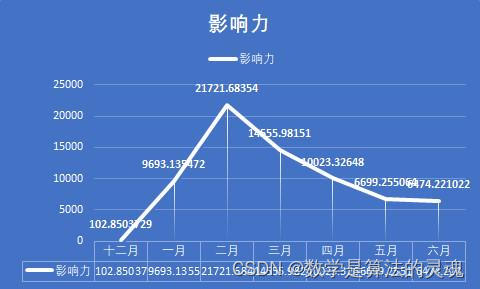
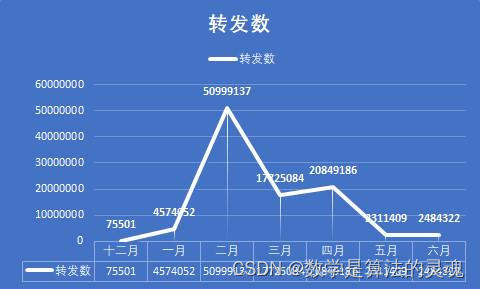
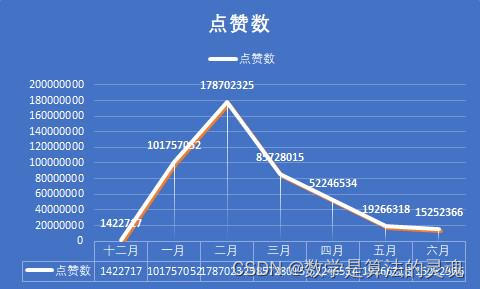
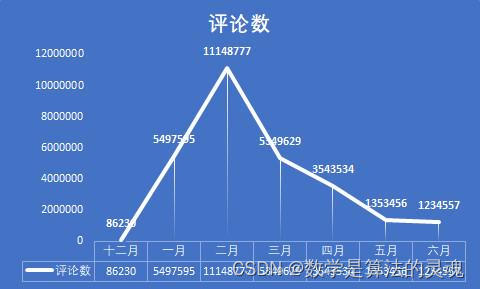
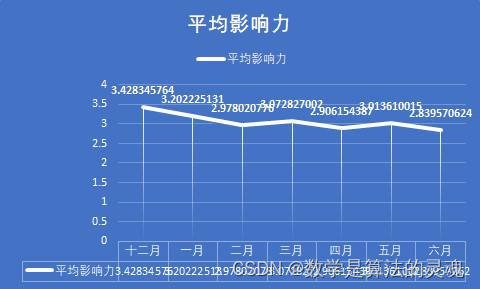
不难发现,点赞数和评论数的走势几乎是一致的,这说明了用户的点赞和评论在一条微博中扮演着相似作用,可能是因为感兴趣,所以我们会在一个微博下方留言,并予以点赞。但是分享的走势却是与前两者差异很大,因此我们有理由认为,分享扮演着很不一样的功能。
众所周知,当我们觉得一条微博的信息比较重要时,我们会乐于将之转发,以期自己的亲朋好友能够也看到这条微博,这说明了用户对于这条微博的重视程度。
这个假设是否成立呢?我们依次来分析,在十二月的时候,人们对疫情的重视度尚不足够,病毒的面貌也没有暴露在我们眼前,这段时间的微博数量很少,官方并没有采取什么积极的行动,官媒也因此没有什么可以播报的。但是我们可以看到,尽管微博数量很少,但是我们看到平均点赞数和平均评论数却很多,这说明尽管疫情尚不严重,但是人们看到这样与自己生活息息相关的事情,仍是感到非常重视的,一些人对于新出现的传染病,也是表达了自己的担忧,具有非典经验的人们,很容易联想到当年的SARS,并感到怀疑。但是事情并没有确切的消息,尚不能确定真的会想当年的非典一样造成严重的后果,过于忧虑轻易转发反而容易被别有用心者扣上阴谋论的高帽。于是平均转发数比之疫情爆发时要明显较少,这是情有可原的。
到了一月初,疫情的消息不温不火,似乎也没造成多大的影响,因此,相关新闻得到的关注度反而有所降低,人们更加不会把疫情当回事儿。但是等到1 月20日后,疫情急剧爆发,微博数大量增加,总的点赞数,评论数,分享数也得到了迅猛的增长。2月是疫情最严重的时期,微博数也最多,总点赞数,转发数,评论数达到峰值,人们认识到疫情的严重性,对于每一个官方发布的重要的疫情信息,比如各地新增的确诊人数,以及采取的防疫措施,都会有意识地进行转发。
2月末到3月,疫情在国内得到了遏制,新增确诊人数已经大大减少,此时国际疫情开始爆发,正如每日关键词可以看到的,媒体开始将主要的矛头转向国际,如日本,意大利,美国等国家的疫情状况。国内疫情的减弱,让人们对疫情的关注度大大下降,这从平均点赞数,平均评论数和平均转发数的大幅缩减可以看出。4月,国内疫情基本结束,媒体开始反思与总结疫情经验,加之国外疫情持续发酵,这既引发了爱国热潮,也带来了对于疫情不同看法的激烈辩论,带来了新一轮的转发热潮。这同时保持了疫情相关新闻的热度,使得平均点赞数,平均评论数不至于大幅下降。
到了5月,6月,国内疫情开始冷却,微博的各项指标都大幅下降,人们开始将关注度投向其他领域,这也十分合理。
可以看到一个似乎不合理的地方,是在于,平均点赞数和平均评论数,从 12月以来一直在下滑,这是否和人们对疫情的重视度理论上的先升后降的大趋势产生了矛盾。其实不然,尽管微博流量很大,但微博始终不是互联网全部流量的来源,微博的日活跃数也是有一个上限的。在疫情初期,各大媒体每日发表的微博数较少,人们有充足的关注度,可以放在这发放的少数微博上,带来了平均点赞数和平均评论数的顶峰。而当疫情爆发以后,各大媒体每日产生的疫情相关的微博数目都大大提升,有些达到了数十之数,显然一个微博用户再将心思放在微博上,也不能关注到每一条微博,因此,我们能够看到微博的总流量大大提高,但是分摊到每一条微博上的流量则会相应的降低了,这就是微博的流量到达了上限的缘故。
综上所述,我们认为,人们在疫情初期其实对疫情是有较高的关注度的,但是由于政府未能采取有效的行动,这份关注逐渐损失,也没有产生较好的结果。当疫情爆发时,人们多表示极为重视,而将自身的互联网生活的大部分精力放在了关注疫情相关信息上,一度带来了流量的大幅提升。当国内疫情得到控制后,人们对疫情的重视程度就有所降低了,但由于国际疫情的爆发,这份降低尚且不太明显,而等到国际疫情的新鲜感逐渐丧失以后,人们多将注意力摆放在日常生活之中,尽管疫情相关的微博数量依然很多,但对疫情的关注已经大大消失了。
四、代码开源地址
4.1 项目完整代码:
https://download.csdn.net/download/qq_38735017/87415764
4.2 数据集地址
全部微博的数据:master分支\微博爬取\project\weibo* 全部评论的数据:
链接:https://pan.baidu.com/s/1b212PyxRTkrueT9HnF2afA 提取码:babo
核心评论的数据:
链接: https://pan.baidu.com/s/1uk49FRQAv4lpzKinla6Xug
提取码:a4e9 每日关键词:master分支\HanLP 数据处理\HLP\data\每日关键词.txt
B站数据:
链接:https://pan.baidu.com/s/1j6jbK3M_aaDQq9TzxHuQAQ
提取码:2n5p



















 7910
7910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











