







 文章介绍了如何使用Python的pdfplumber库从PDF文件中提取文本,通过处理和筛选,快速找到特定学校(如山东大学)的获奖名单,并将结果保存到TXT文件中。提供的代码示例展示了数据提取和筛选的步骤。
文章介绍了如何使用Python的pdfplumber库从PDF文件中提取文本,通过处理和筛选,快速找到特定学校(如山东大学)的获奖名单,并将结果保存到TXT文件中。提供的代码示例展示了数据提取和筛选的步骤。
全国大学生数学竞赛山东赛区的成绩终于出来了,所给的数据是PDF形式(如图),数据获取方式在文末
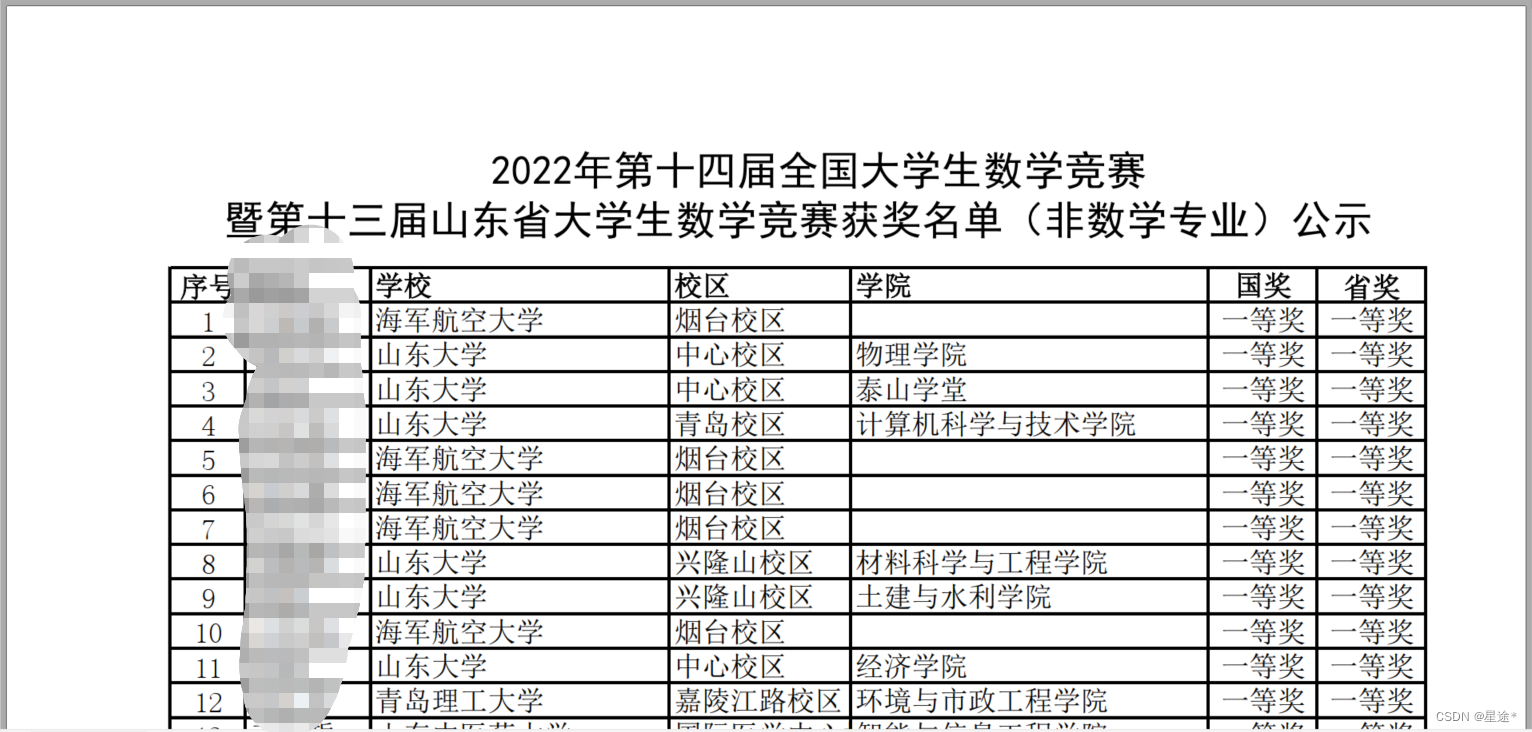
本文介绍如何快速筛选出同校同学的获奖名单(所有这类形式的数据通用)
主要思路为:
step1 提取PDF中的文本,并以换行符为分隔拆分成列表类型
step2 为方便查看数据 ,给数据加上类型标签
step3 筛选
以下是代码实现:
import os
import pdfplumber
# pdf文件地址
PDF_path = "D:\A-pycharmproject1\数学竞赛\PDF"
#获取此文件夹下的文件名称
file_list = os.listdir(PDF_path)
#定义一个空列表存储数据
total_data = []
for name in file_list:
data = []
with pdfplumber.open(PDF_path+"\\"+name) as pdf:
pages_data = [page.extract_text() for page in pdf.pages]#读取PDF每页的文本,共多少页,pages_data就有几个元素
#将pages_data内的元素按“\n”拆分放入data列表
for item in pages_data:
data += item.split("\n")
#由于这三个PDF是不同类别的,所以在数据前面加上标识
data = [name[19:-8]+item for item in data]#需要实事求是,以实际情况出发
# 合并到total_data列表中
total_data += data
#查询字段str
str = "山东大学"
#target
target = [item for item in total_data if str in item]
with open(str+".txt", mode='a', encoding='utf-8') as f:
for item in target:
f.write(item+"\n")
# f.write("\n")
f.close()
封装成函数
import os
import pdfplumber
# pdf文件地址
PDF_path = "D:\A-pycharmproject1\数学竞赛\PDF"
#查询字段str
str = "山东大学"
def search(PDF_path,str):
#获取此文件夹下的文件名称
file_list = os.listdir(PDF_path)
#定义一个空列表存储数据
total_data = []
for name in file_list:
data = []
with pdfplumber.open(PDF_path+"\\"+name) as pdf:
pages_data = [page.extract_text() for page in pdf.pages]#读取PDF每页的文本,共多少页,pages_data就有几个元素
#将pages_data内的元素按“\n”拆分放入data列表
for item in pages_data:
data += item.split("\n")
#由于这三个PDF是不同类别的,所以在数据前面加上标识
data = [name[19:-8]+item for item in data]
# 合并到total_data列表中
total_data += data
print(f"{name}处理完毕")
#target
target = [item for item in total_data if str in item]
print("检索完毕")
with open(str+".txt", mode='a', encoding='utf-8') as f:
for item in target:
f.write(item+"\n")
# f.write("\n")
f.close()
print("导出成功")
search(PDF_path,str)文件结构如下

数据
数学竞赛获奖名单 https://www.aliyundrive.com/s/zXgUdQCzaTZ 点击链接保存,或者复制本段内容,打开「阿里云盘」APP ,无需下载极速在线查看,视频原画倍速播放。
最后,这个方法不是唯一方法也不是最优方法,用时12s左右

















 595
595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









