







动机
现有方法主要依赖于预训练模型的通用知识,忽视了领域特定知识的重要性。ConKI通过知识注入技术整合了领域特定知识,增强了模型对特定情感的识别能力。
传统方法在模态间交互和融合方面存在局限,未能充分利用不同模态间的互补信息。ConKI通过层次化对比学习,加强了模态间的交互和融合,提升了情感预测的准确性。
现有模型在性能提升和泛化能力方面存在限制。ConKI框架通过外部数据集的知识注入和层次化对比学习,不仅提高了模型在特定数据集上的性能,也增强了模型对未知数据的泛化能力。
模型
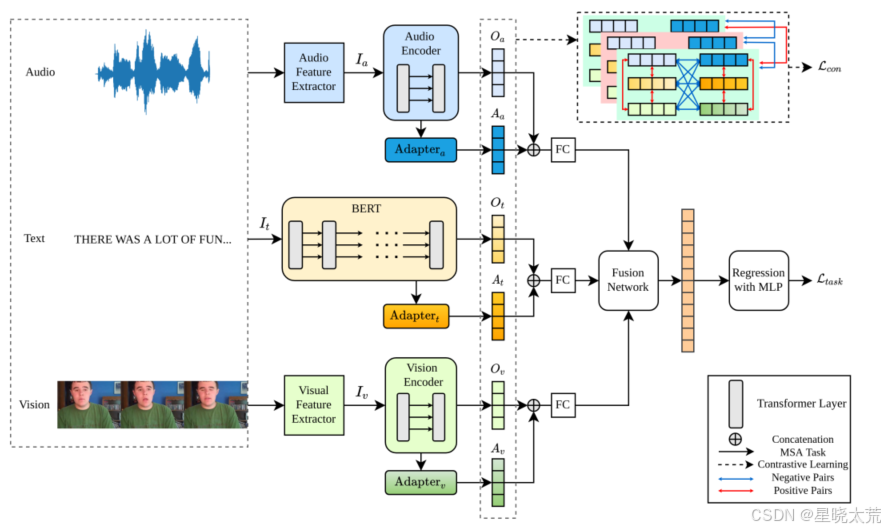
总体架构
首先使用相应的特征提取器和分词器将原始多模态输入处理成低级特征。然后,我们将
编码成由适配器生成的知识特定表示(即
)和由预训练编码器生成的泛知识表示(即
)。文本编码器来自公开可用的预训练模型,如BERT,而视觉/音频编码器是设计好的模型,随机初始化。生成知识特定和泛知识表示后,ConKI将同时用下游目标数据集进行两项不同任务的训练——主要的MSA回归任务和对比学习子任务。
MSA回归任务
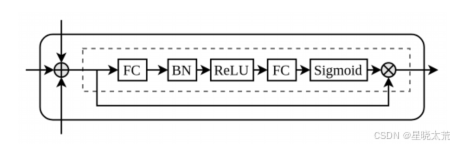
对于MSA任务,将每个模态的知识特定表示和泛知识表示进行拼接后,将它们送入全连接(FC)层进行模态内融合。然后我们设计了一个融合网络,包括一个拼接层和一个融合模块,用于多模态融合,如上图图所示。融合后的表示被送入多层感知器(MLP)网络以产生情感预测。
对比学习子任务
对于层次化对比学习的子任务,在知识层面、模态层面和样本层面精心构建正负样本对。配对策略的如下:
1.期望和
能够捕捉不同的知识,因此通过知识层面的对比将它们分开,使它们互补,以获得更丰富的模态表示。
2.由于视频的情感由所有模态决定,通过模态层面的对比学习六个表示之间的共同点。
3.表达相近情感的视频应该有一些相关性。通过样本层面的对比捕捉这种相关性,以帮助进一步学习在相近情感下的样本之间的共同点。
通过整合这些层次化的对比,ConKI能够捕捉到表示之间的全部动态,这可以显著地有益于主要的MSA任务。
知识注入
对于文本模态使用预训练的BERT模型来编码文本模态的输入句子。从最后一层提取的池化输出向量作为整个句子的表示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









