






1.背景
现有的多模态情感分析在对于具有讽刺意味的数据识别还存在巨大挑战,讽刺可以定义为说出或写出与某人的意思相反的内容,或者以一种让某人感到愚蠢或愤怒的方式说话。例如,当某人写了一些积极的内容,但内容的含义是消极的,反之亦然。这使得情感分析变得更加复杂。由于讽刺的模糊性和复杂性,检测讽刺变得具有挑战性。现有的多模态讽刺检测(MSD)模型存在数据集偏差的问题,特别是统计标签偏差和无关讽刺词汇偏差。这些偏差会导致模型学习到虚假的相关性,从而影响预测的准确性。为了解决这个问题,作者提出了一个无需训练的反事实去偏框架TFCD。
2.方法
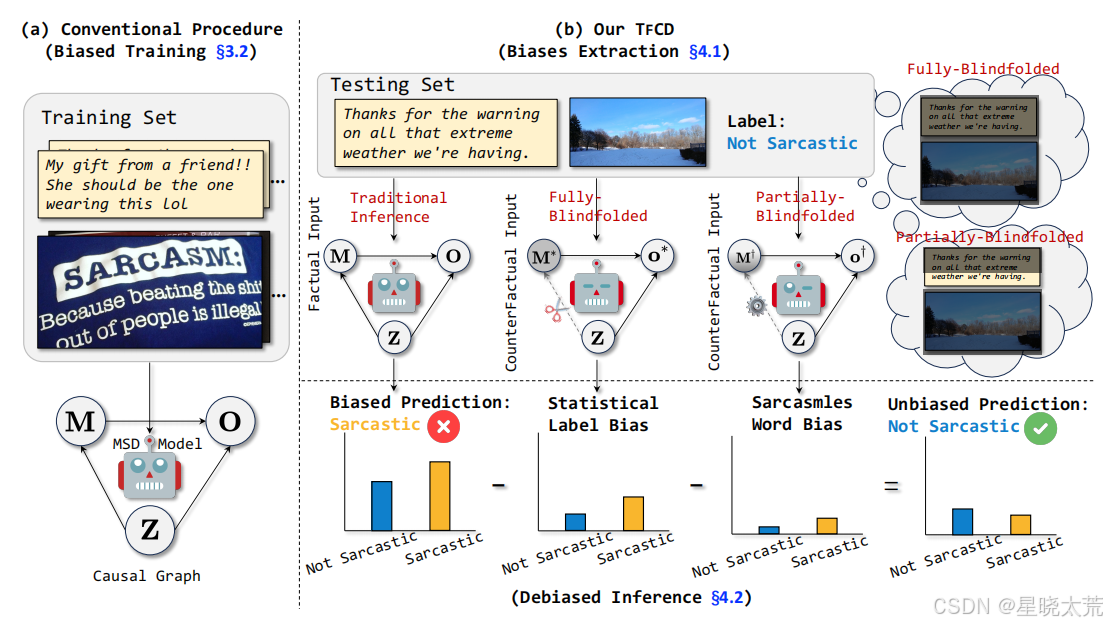
2.1传统模型流程
给定训练集中的一个样本 ,MSD 任务的目标是通过使用文本
和相应的图像
来学习一个模型
,以确定该样本是否包含讽刺。这一传统的训练过程表示为
,其中
表示样本具有讽刺性,反之则不然;
表示模型的可学习参数。现有的 MSD 模型专注于设计复杂的架构或机制,以从整体或局部的文本和图像特征中提取讽刺线索:
中 表示融合的多模态特征,
表示依赖于特定 MSD 模型的融合策略。然后,我们使用前向传播来预测样本,并通过反向传播以端到端的方式更新模型的可学习参数,如上图(a) 所示。遵循之前的工作,我们使用交叉熵损失来优化 MSD 任务:
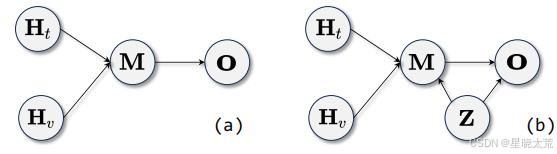
2.1MSD 因果图
MSD 因果图中涉及四个变量,分别是文本特征、视觉特征
、多模态特征
和预测
。
2.2统计标签偏差
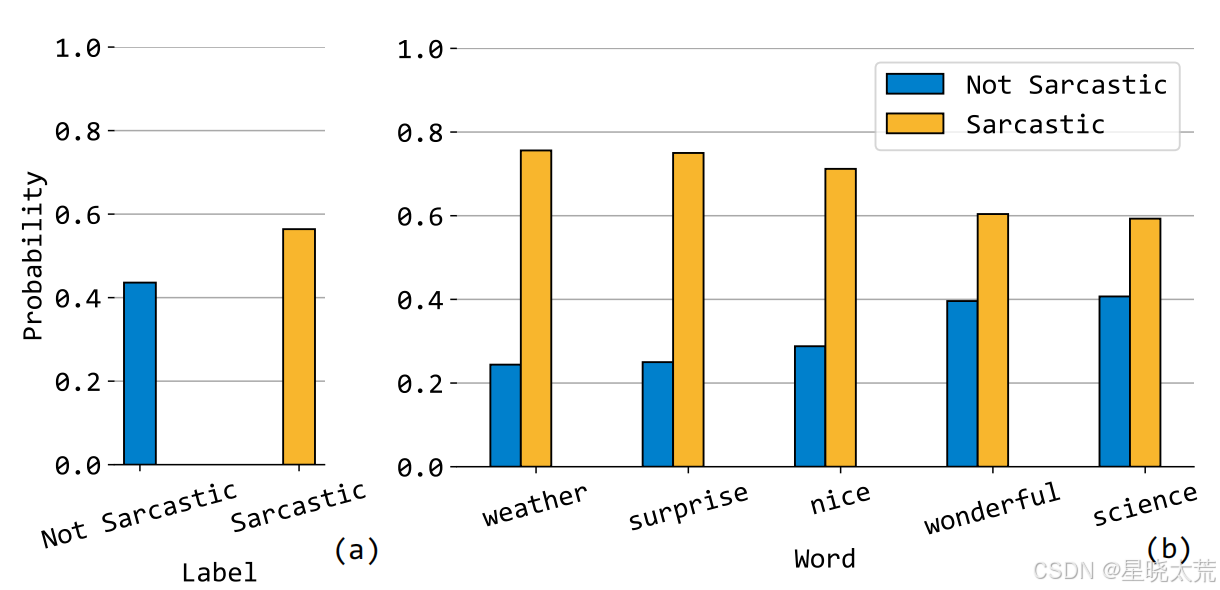
训练数据中标签分布不平衡(如“讽刺”类样本占比更高),导致模型预测时过度依赖多数类标签,而非真实语义。所以我们的目标是分离标签分布偏差的影响,使预测仅依赖多模态内容的真实因果效应。
为了获取偏差,我们假设模型假设模型将以等概率随机猜测(即均匀分布假设),这样我们就可以得到统计标签偏差的负面影响。TFCD框架通过反事实干预和均匀分布假设,量化并修正此类偏差,使模型预测更依赖内容语义而非标签频率。这一方法避免了传统策略的数据操作或模型重训练需求,具有高效性和通用性。
2.3讽刺词偏差
讽刺词偏差目的是识别并消除那些与讽刺类别强关联但本身并不具有讽刺含义的词汇对模型预测产生的误导性影响。通过消除讽刺词偏差,模型能够更加准确地专注于文本和图像中的真正语义信息,而不是依赖于这些误导性的统计关联,从而提高多模态讽刺检测(MSD)任务的性能。通过部分遮蔽(partially-blindfolded)的反事实输入来提取这种偏差。具体来说,使用 pysentiment 库构建主内容词汇表,然后将这些词汇替换为 [mask],同时将图像特征设置为全零向量。这样可以保留那些与讽刺类别强关联但本身不具有讽刺含义的词汇的影响,从而提取出讽刺词偏差。
2.4无偏推理
在获得两种偏差后,最终目标是利用多模态表示 对预测
的直接影响,以促进无偏差预测。这一过程可以通过概念简单但经验上稳健的逐元素减法来形式化:
其中 和
是两个超参数。请注意,我们确定了两个可调整的缩放因子,这些因子根据模型在验证集上的性能进行了优化,因为不同的偏差对最终预测有不同的影响。
3.实验
3.1实验环境
实验基于两个多模态讽刺检测数据集:
-
MMSD:源自英文推文,正例(讽刺类)通过特定标签筛选,负例(非讽刺)占主导(训练集负例56.4%),存在标签分布失衡和词汇偏差(如“weather”与讽刺类强关联)。
-
MMSD2.0:MMSD的改进版,移除误导性标签/表情符号,但未解决固有偏差(如标签仍轻微失衡,词汇偏差残留)。
实验基于 PyTorch 框架,在 NVIDIA Tesla V100 GPU 上运行,采用多模态模型的常规训练设置(损失函数、批量大小、学习率等与原论文一致以确保公平对比)。超参数(如标签/词汇去偏系数 α、β)通过 网格搜索(范围 0-1,步长 0.1)在验证集优化选定,结果取 5 次随机运行的平均值 以降低随机性影响。
-
关键差异:MMSD2.0通过数据清洗部分缓解标签失衡(训练集正负例接近平衡),但两类数据集均需解决模型对偏差的依赖问题。
-
实验意义:验证TFCD在高偏差(MMSD)和部分修正偏差(MMSD2.0)场景下的鲁棒性,证明其无需数据平衡或模型调整即可提升性能。
3.2对比试验
实验复现了 5 种主流模型(如 HFM、Multi-view CLIP 等),未开源模型通过论文描述复现。
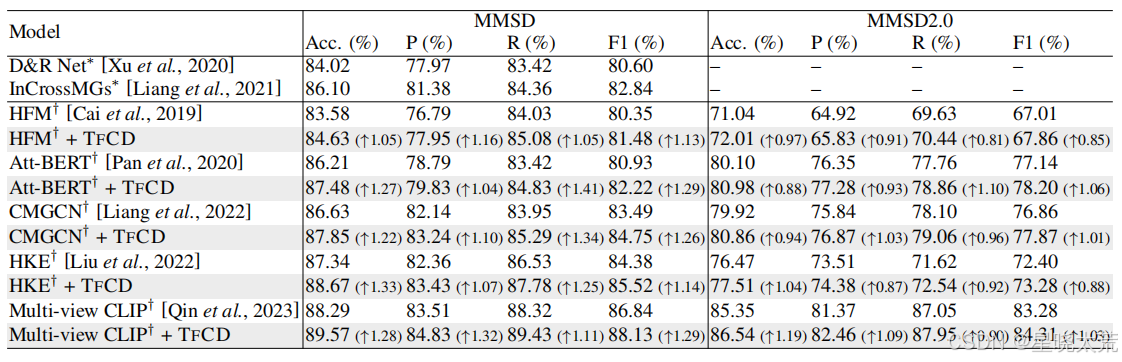
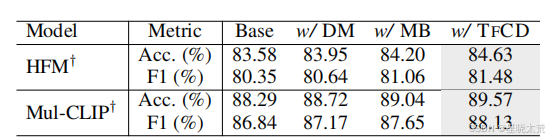
与其他去偏差策略的比较。作者还进行了比较实验,以验证所提出的去偏差框架与其他去偏差策略的效果,结果下表所示。可以发现,提出的框架优于典型的去偏差策略,从数据操作到模型平衡。而且这两种去偏差方法需要额外的人工或训练成本。作者所提出的框架仅在推理过程中工作,因此可以应用于已经训练好的模型,这可以作为增强当前 MSD 基线的强大、“无需数据操作”和“无需模型平衡”的武器。
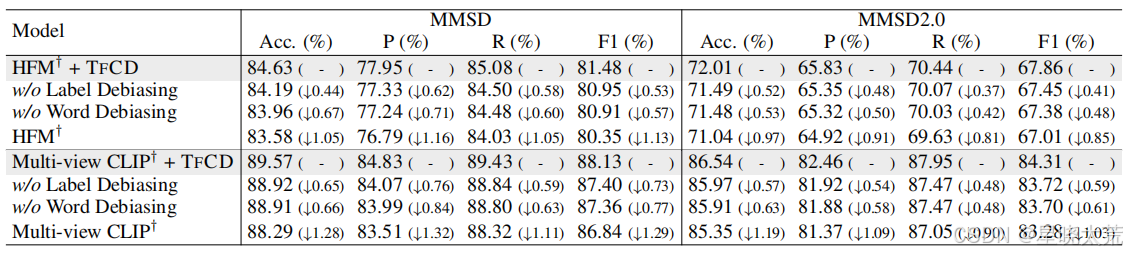
3.3消融实验
作者选择了两个代表性模型,即 HFM 和 Multi-view CLIP,来评估所提出的 TrCD 框架中每个组件的贡献。两个数据集上的消融研究结果如表 4 所示,其中所有改进均具有统计显著性,如配对 t 检验的 p-值 < 0.05 所示。我们得出以下结论:
(1) 移除任何组件都会导致两个数据集上的所有指标下降,这验证了所提出的标签和词语去偏差的有效性。这是因为标签去偏差引入了全局偏移,而词语去偏差则贡献了局部偏移,以在预测空间中“移动”,这使得训练模型对观察数据中潜在的有害偏差“视而不见”,从而使它们能够仅专注于每个样本的核心内容进行推理。(2) 词语去偏差的改进更为显著。这可能归因于训练模型通常利用词语级信息进行推理,这可能会不可避免地利用潜在的偏差词语。得益于词语去偏差,TrCD 在一定程度上解决了这些词语引入的虚假相关性。
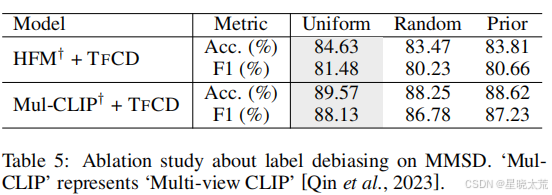
Random 表示 M∗是在没有任何约束的情况下学习的,Prior 表示 M∗服从训练集的先验分布。该实验通过对比不同分布假设下的模型表现,揭示了均匀分布假设在标签去偏差中的核心作用:它通过中立化标签分布的先验,阻断模型对偏差的依赖,从而更安全、有效地提升泛化性能。结果如下图
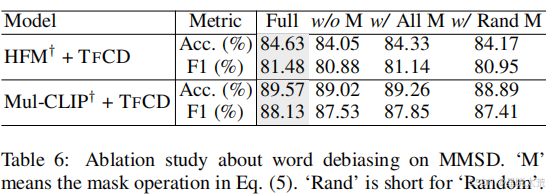
下图实验表明,选择性掩码主要内容词 是词语去偏差的关键:它通过精准阻断模型对偏差词的依赖,同时保留有效语义信息,使模型更关注跨模态的深层矛盾(如文本与图像的情感冲突)。TFCD的这一设计显著优于“全掩码”或“随机掩码”,为多模态去偏任务提供了高效、自适应的解决方案。
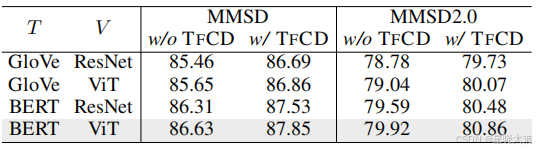
下图表明在使用不同的文本视觉编码器时,对四个 CMGCN 变体进行了实验,包括使用和不使用作者提出的 TFCD。观察到随着使用更先进的预训练骨干网络,TFCD 的增益增加。这证明了 TFCD 的性能不依赖于特别选择的骨干。
3.4方法分析
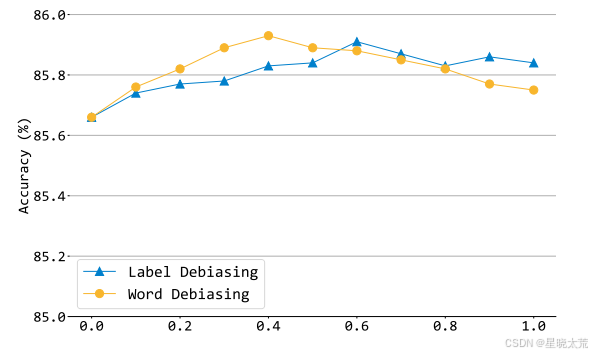
作者评估了超参数和
的取值范围和模型预测准确度之间的关系,发现随着系数的逐步增加,准确率相应提高。每种去偏差策略的最佳性能在不同的点达到(在实践中,标签去偏差为 0.6,词语去偏差为 0.4),超过这些点后出现下降趋势。此外,我们发现标签去偏差表现出相对温和的变化,而词语去偏差对系数的变化表现出更高的敏感性,需要更仔细的调整。
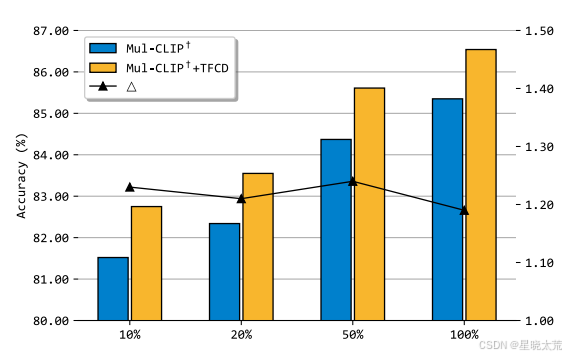
作者在低资源场景下进行了实验,使用不同数量的训练样本包括 10%、20% 和 50%。从下图 中,观察到使用我们的 TFCD 的 Multi-view CLIP 在低资源场景下始终优于其基线对应模型。作者将此归因于提出的去偏差策略(尤其是标签去偏差),即使正负训练样本的比例不同,模型也可以消除虚假相关性。这证明了的 TFCD 在训练和测试样本分布不一致的情况下的鲁棒性,取得了显著的改进。
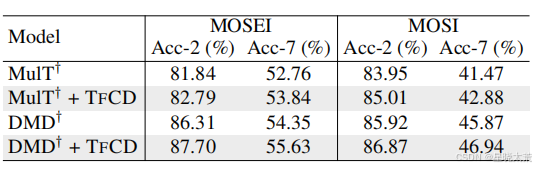
作者还在情感分析领域选择了两个代表性模型结果如下表所示。发现使用 TFCD 的模型始终比其原始对应模型提升了约 1% 的性能,这证明了 TFCD 的泛化性。
4.结论
本文提出了一种无需训练的去偏差策略,称为 TFCD,以减少多模态讽刺检测(MSD)中统计标签和讽刺词的有害偏差。
具体来说,TFCD 通过定制的因果图解耦了变量之间的因果关系,并提出了一个偏差提取模块来提取由这两种偏差引起的负面影响。然后通过逐元素减法减轻这些偏差,以实现无偏差推理。大量实验证明,TFCD 可以持续改进现有基线。与模型无关且无需训练的 TFCD 无疑优于之前方法中采用的复杂重新训练模块。

















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









