







常见技巧与优化
主要讲解: MySQL 数据库使用时的一些技巧和方法
目录:
1、查找重复记录
数据库中的重复事件发生很多。查找重复值是使用数据库时必须处理的重要任务之一。
例如在一个购物应用中,商品表信息如下所示:
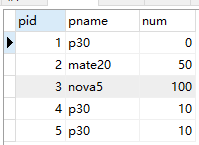
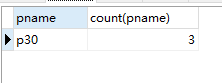
案例1:使用 sql 语句查询表中重复的商品记录
select pname,count(pname)
from product
group by pname
having count(pname)>1;
运行结果如下:
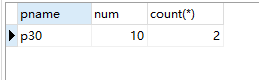
案例2:使用 sql 语句查询表中商品名称和数量都重复的记录
select pname,num,count(*)
from product
group by pname,num
having count(pname)>1 and count(num)>1;
运行结果如下:
2、删除重复记录
当确定了表中有重复的行,可能需要删除它们来清理这些不必要的数据。
案例:使用 sql 语句删除商品名称重复的记录,只保留 id 最大的记录
-- 删除商品名重复的记录
delete p1 from product p1
inner join product p2
where p1.pid<p2.pid and p1.pname=p2.pname;
-- 查询商品表
select * from product;
运行结果如下:
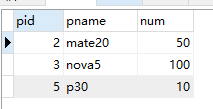
删除后再查询商品表,id 为 1 和 4 的 p30 记录都被删掉了。如果想要保留 id 最小的记录,可以把 p1.pid<p2.pid中的小于号,
改成大于号即可。
3、选择随机记录
有些业务需要从表中选择随机记录,例如:
在店铺商品中选择一些随机的商品,并推荐到侧边导购栏;
在画廊中选择随机图片,并将其用作精选照片。
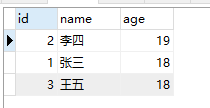
案例1:使用 sql 语句从 student 表中随机选择 1 名学生记录
表格中所有的学生信息:
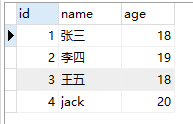
select * from student
order by rand()
limit 1;
运行两次结果分别如下:
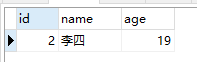
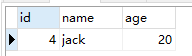
rand()函数为表中每一行记录生成一个随机值,order by 通过这个随机值进行排序,最后 limit 限定只返回第一行。由于每次
rand()的值都是不一样的,所以最终返回的结果也不一样。
案例2:使用 sql 语句从 studentinfo 表中随机选择 3 名学生记录
select * from student
order by rand()
limit 3;
运行两次结果分别如下:
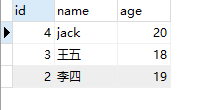
4、选择第 n 个最高记录
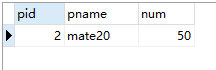
案例:查询库存第 2 多的商品信息
原商品图如下:

select * from
(select * from product
order by num desc
limit 2) as T
order by num asc
limit 1;
运行结果如下:
5、比较两个表的数据
现有两张表数据如下图所示:
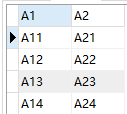
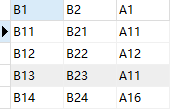
案例:查询出 A1 字段中,存在 t_a 表,但是不存在 t_b 表的数据
-- 方法一:
select * from t_a where a1 not in
(select a1 from t_b);
运行结果如下:
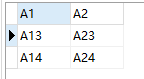
-- 方法二:
select t_a.* from t_a left join t_b
on t_a.A1=t_b.A1
where t_b.B1 is null;
运行结果如下:
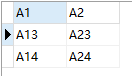
6、行转列
现在有一张成绩表,表数据如下图所示:

案例:为了方便查看每个同学的成绩,使用 sql 语句查询出如下结果:
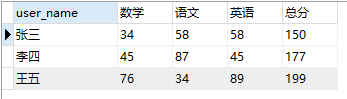
实现代码如下:
select user_name,
max(case course when '数学' then score else 0 end) 数学,
max(case course when '语文' then score else 0 end) 语文,
max(case course when '英语' then score else 0 end) 英语,
sum(score) 总分
from test_tb_grade
group by user_name;
7、all、any、some 查询
ALL 用在子查询前,通过比较运算符将一个表达式或列的值与子查询返回的一列值中的每一行进行比较,只要有一次比较的
结果为 FALSE,则 ALL 测试返回 FALSE。
有一张成绩表数据如下图(24条数据):


案例1:查询成绩比科目编号为“1”的这门课程的所有成绩都大的学生考试信息
SELECT * from exam where
exam>all(select exam from exam where SubjectId=1);
运行结果如下:
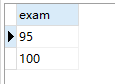
大于ALL 表示大于每一个值。换句话说,它表示大于最大值。
ANY 与子查询在一起使用时,按照比较运算符、表达式或字段对子查询的结果的每一行进行一次计算和比较。只要有一次满
足条件,那么 ANY 的结果就是真。
案例2:查询成绩比科目编号为“1”的任意一个成绩都大的考试信息
SELECT * from exam where
exam>any(select exam from exam where SubjectId=1);
运行结果如下:
SOME 与 ANY 的作用相同。
注意:"=ANY"运算符与"IN"等效。"< >ANY"运算符则不同于"NOT IN"。"< >ANY(A,B,C)" 表示不等于 A,或者不等于 B,或者不等
于 C。"NOT IN(A,B,C)“表示不等于 A、不等于 B 并且不等于 C。”< >ALL"与"NOT IN"表示的意思相同。
8、分组统计
在 test 数据库中有一张 sx_target 表,统计各个地区用户点击量,表数据图如下:

表数据量教大,这里只显示一小部分数据。
案例1:查询每个城市每个月份的点击量
select
city_name,state_month,sum(sx_sum)
from sx_target group by city_name,state_month;
运行结果如下:

案例2:在现有统计基础上,显示每个城市的合计,以及所有城市的合计
select city_name,state_month,sum(sx_sum)
from sx_target
group by city_name,state_month with ROLLUP
运行结果如下:

with rollup 是用来在分组的基础上再进行统计。
9、排名查询
在 sqlserver 和 oracle 数据库中,都有系统定义的排名函数,mysql 中目前还没有对排名查询的支持,需要我们自己去实现排名查询。
在 schooldb 数据库中有一张 exam 表,表测试数据如下:
案例:要求查询出,科目编号为 2 的科目成绩及排名
select examid,studentid,exam,rank from
(select examid,studentid,exam,
@rownum:=if(@prev=a.exam,@rownum,@inc) as rank,-- 定义了三个变量
@inc:=@inc+1,
@prev:=a.exam
from exam a,(select @rownum:=0,@prev:=null,@inc:=1) b
where SubjectId=2
order by a.exam desc) tb;
运行结果如下:

10、union 合并查询
MySQL 中 UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中并删除重复的数据。
在 test 数据库中有一张学生表 student 和一张教师表 teacher,表测试数据如下所示:
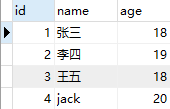
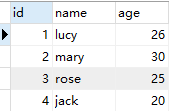
案例:要求查询所有师生的信息
select id,name,age from student
union
select id,name,age from teacher;
运行结果如下:
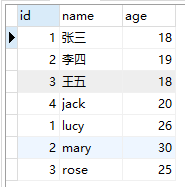
union 在合并时会删除重复记录,相当于 distinct,如果不想去重,可以使用 union all。
select id,name,age from student
union all
select id,name,age from teacher;
运行结果如下:
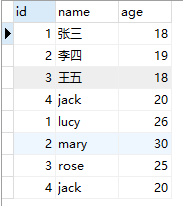
注意:使用 union 查询有以下几个要点:
union 联合的两个 select 必须拥有相同数量的列;
列必须有相似的数据类型;
列的顺序必须相同;
union 因为要去重,效率远不如 union all。
11、exists 查询
EXISTS 关键字后面的参数是一个任意的子查询,系统对子查询进行运算以判断它是否返回行,如果至少返回一行,那么
EXISTS 的结果是 TRUE,此时外层查询语句将进行查询;如果子查询没有返回任何行,那么 EXISTS 返回的结果是 FALSE,
此时外层语句将不进行查询。
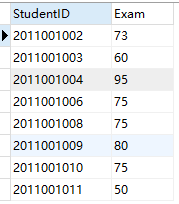
有一张exam 表,表测试数据如下:
案例:查询成绩表中科目编号为 2 的考试成绩中是否存在不及格的学生,如果存在不及格的学生就将参加科目编号 2 考试的学
生编号和成绩全部查询显示出来
SELECT StudentID,Exam FROM EXAM WHERE SubjectID=2 AND EXISTS
(SELECT StudentID from EXAM WHERE Exam<60);
运行结果如下:
12、计算列
储存在表中的数据不都是计算机应用程序所需要的,需要直接从数据库中检索出转换、计算或格式化过的数据,而不是检索
出数据,然后再在客户机应用程序或报告程序中重新格式化。这就是计算字段要发挥的作用。
在 test 数据库中有一张 users 表,表测试数据如下:
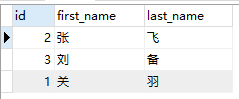
案例:在存储用户信息时,姓和名是分开的,现在要求通过 sql 查询出用户信息,要求姓名用一个字段显示。
select id,concat(first_name,last_name) as name from users;
运行结果如下:
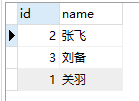
计算列除了拼接字符串,还可以进行算术计算。
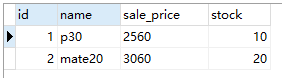
在 test 数据库中有一张 goods 表,表测试数据如下:
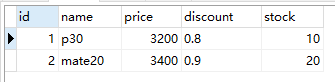
案例:price 字段表示单价,discount 字段表示折扣,要求查询出商品信息,并计算出商品的售价(即单价*折扣)。
select id,name,price*discount as sale_price,stock from goods;
运行结果如下:















 393
393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









