







 本文介绍了查找算法的重要性,特别是二分查找,它在已排序数据中的高效性,以及与线性查找的对比。通过实例演示了二分查找的实现和其在多次查找中的优势。
本文介绍了查找算法的重要性,特别是二分查找,它在已排序数据中的高效性,以及与线性查找的对比。通过实例演示了二分查找的实现和其在多次查找中的优势。
查找是另一类必须掌握的基础算法,它不仅会在机试中直接考查,而且是其他某些算法的基础。排序的重要意义之一便是帮助人们更加方便地进行查找。如果不对数据进行排序,那么在查找某个特定的元素时,需要依次检查所有的元素,这样的方式对于单次或少量的查找来说运行效率是很高的,但查找次数较多时,如果所有元素都是有序的,那么就能更快地进行检索,而不必逐个元素地进行比较。
例题一:
#include<iostream>
using namespace std;
int main()
{
int arr[200] = { 0 };
int n;
cin >> n;
for (int i = 0; i < n; i++)
{
cin >> arr[i];
}
int x;
cin >> x;
int flag = 0;//设置标志位
for (int i = 0; i < n; i++)
{
if (arr[i] == x)
{
flag = 1;//说明找到了x
cout << i;
break;
}
}
if (flag == 0)
{
cout << -1;
}
return 0;
}下面介绍一种不同于线性查找的查找策略,而是一种策略性、跳跃性的方法来遍历查找空
间,它就是二分查找。二分查找建立在待查找元素排列有序的前提下。假设元素是按升序排列的,将序列中间位置记录的关键字与查找关键字比较,若二者相等,则查找成功;否则利用中间位置记录的关键字将序列分成前、后两个子序列,若中间位置记录的关键字大于查找关键字,则进一步查找前面的子序列,否则进一步查找后面的子序列。重复以上过程,直到找到满足条件的记录(查找成功),或到子序列不存在为止(此时查找不成功)。
由于每次查找都会舍弃一半的元素,因此二分查找的时间复杂度可由线性查找的 O(n)降至
O(logn)。有的读者可能会有疑问,虽然二分查找的时间复杂度要低于线性查找,但排序的时
间复杂度至少是 O(nlogn),如此说来线性查找岂不是要优于二分查找?如果只要求对序列进行单次查找,那么线性查找不失为一个好策略,但如果要进行多次查找,那么线性查找将不再具有优势。假设查找次数为 m,那么线性查找的时间复杂度为 O(nm),二分查找的时间复杂度为O(nlogn + mlogn),可见当 m 特别小时线性查找很有优势,但当 m 大到一定程度时,二分查找的性能便会远远优于线性查找。
例题二:
思路:
代码:
方法一:
#include<iostream>
#include<algorithm>
using namespace std;
bool Binary_search(int data, int arr[], int n)
{
int left = 0, right = n - 1;
while (left <= right)//循环条件非常容易写错
{
int mid = (left + right) / 2;//这一句话很容易出错,left+right记得带上括号
if (arr[mid] == data)
{
return true;
}
else if (arr[mid] > data)
{
right = mid - 1;
}
else
{
left = mid + 1;
}
}
return false;
}
int main()
{
int n;
cin >> n;
int arr[100] = { 0 };
for (int i = 0; i < n; i++)
{
cin >> arr[i];
}
sort(arr, arr + n);
int m;
cin >> m;
for (int i = 0; i < m; i++)
{
int data;
cin >> data;
bool exist = Binary_search(data, arr, n);
if (exist)
{
cout << "YES" << endl;
}
else
{
cout << "NO" << endl;
}
}
return 0;
}注意:此处在刷OJ题目时,一般建议把arr数组设置为全局的数组,这样就可以在调用二分查找函数时不用把arr数组传参过去,以免防止传参设置错误的情况.
方法二: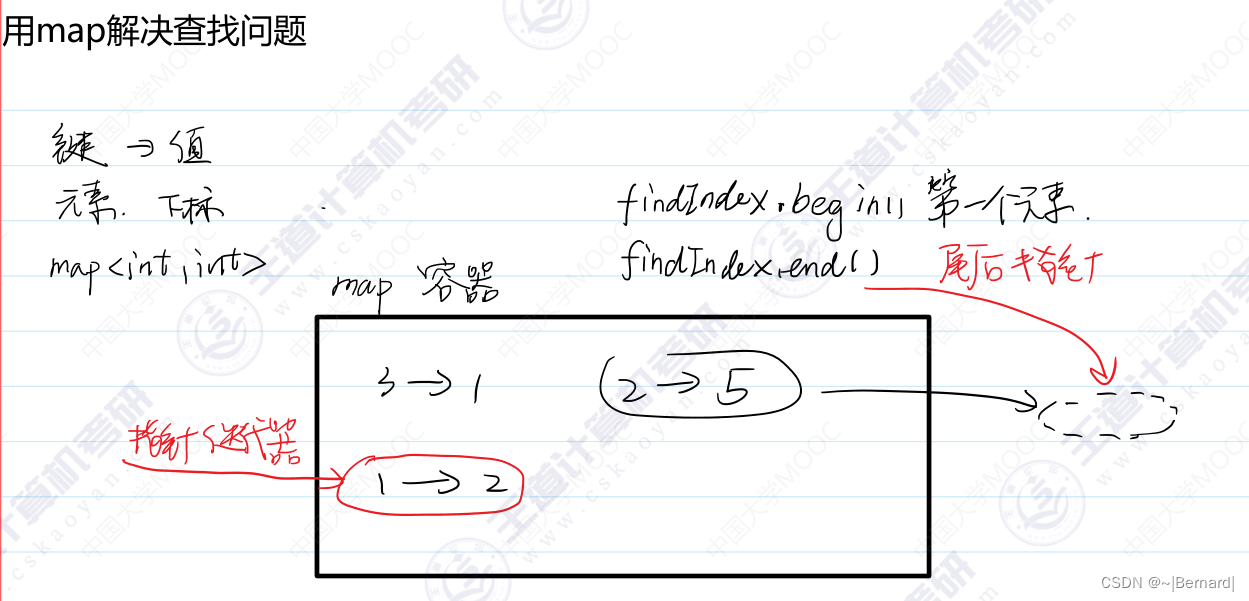
map的find函数,如果查找成功会返回对应位置元素的迭代器,如果查找失败,会返回最后一个元素的后一个位置的指针.
#include<map>
#include<iostream>
using namespace std;
int main()
{
int n;
cin >> n;
int arr[100] = { 0 };
map<int, int> Find_Index;//map的底层是一个二叉搜索树,查找效率非常高
for (int i = 0; i < n; i++)
{
cin >> arr[i];//依旧还是把元素放入arr数组中
Find_Index[arr[i]] = i;//注意这一步
//将数组的元素作为键,数组元素的下标作为值,插入到map中
}
int m;
cin >> m;
for (int i = 0; i < m; i++)
{
int data;
cin >> data;
if (Find_Index.find(data) == Find_Index.end())//find函数会返回找到那个元素的迭代器
{
cout << "NO" << endl;
}
else
{
cout << "YES" << endl;
}
}
return 0;
}















 2259
2259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











